MS COCO数据集及COCO的API简介
参考链接
零、COCO数据集的注意事项
COCO数据集一般是不包含背景的,coco的类别id是从1开始的(默认0留给背景),如果自己生成的json文件里有id为0的数据(多余的),看能不能把它给删掉。或者你自己改yolox读取数据的代码,忽略掉id为0的标签。(id把人纠结了好久,使用labelme的官方脚本生成COCO格式的数据集)
如何将自己的数据集转化成COCO格式,请参考之前写的一篇博文:labelme的使用。
一、使用Python的json库查看
二、读取每张图片的bbox信息
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
json_path = "D:/pywork/labelme2coco/data_dataset_coco/annotations.json"
img_path = "D:/pywork/labelme2coco/data_dataset_coco"
# load coco data
coco = COCO(annotation_file=json_path)
执行完以上代码后,控制台打印出以下内容:

coco.loadImgs(img_id)
这个返回的结果是一个list, [0]表示取list中第一个元素,[‘file_name’]取出当前图片的名字。
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
json_path = "D:/pywork/labelme2coco/data_dataset_coco/annotations.json"
img_path = "D:/pywork/labelme2coco/data_dataset_coco"
# load coco data
coco = COCO(annotation_file=json_path)
# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))
# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
# 遍历前三张图像
for img_id in ids[:3]:
# 获取对应图像id的所有annotations idx信息
ann_ids = coco.getAnnIds(imgIds=img_id)
# 根据annotations idx信息获取所有标注信息
targets = coco.loadAnns(ann_ids)
# get image file name
path = coco.loadImgs(img_id)[0]['file_name']
# read image
img = Image.open(os.path.join(img_path, path)).convert('RGB')
draw = ImageDraw.Draw(img)
# draw box to image
for target in targets:
x, y, w, h = target["bbox"]
x1, y1, x2, y2 = x, y, int(x + w), int(y + h)
draw.rectangle((x1, y1, x2, y2), outline='red')
draw.text((x1, y1), coco_classes[target["category_id"]])
# show image
plt.imshow(img)
plt.show()
ImageDraw.Draw.rectangle()绘制一个矩形
outline-用于轮廓的颜色。
fill-用于填充的颜色
ps:默认情况绘制的矩形框显示的是白色的,由于图片背景和白色相近,刚开始都没发现画了框……
三、读取每张图像的segmentation信息
import os
import random
import numpy as np
from pycocotools.coco import COCO
from pycocotools import mask as coco_mask
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
random.seed(0)
json_path = "D:/pywork/labelme2coco/data_dataset_coco/annotations.json"
img_path = "D:/pywork/labelme2coco/data_dataset_coco"
# random pallette
pallette = [0, 0, 0] + [random.randint(0, 255) for _ in range(255*3)]
# load coco data
coco = COCO(annotation_file=json_path)
# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))
# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
# 遍历前三张图像
for img_id in ids[:3]:
# 获取对应图像id的所有annotations idx信息
ann_ids = coco.getAnnIds(imgIds=img_id)
# 根据annotations idx信息获取所有标注信息
targets = coco.loadAnns(ann_ids)
# get image file name
path = coco.loadImgs(img_id)[0]['file_name']
# read image
img = Image.open(os.path.join(img_path, path)).convert('RGB')
img_w, img_h = img.size
masks = []
cats = []
for target in targets:
cats.append(target["category_id"]) # get object class id
polygons = target["segmentation"] # get object polygons
rles = coco_mask.frPyObjects(polygons, img_h, img_w)
mask = coco_mask.decode(rles)
if len(mask.shape) < 3:
mask = mask[..., None]
mask = mask.any(axis=2)
masks.append(mask)
cats = np.array(cats, dtype=np.int32)
if masks:
masks = np.stack(masks, axis=0)
else:
masks = np.zeros((0, height, width), dtype=np.uint8)
# merge all instance masks into a single segmentation map
# with its corresponding categories
target = (masks * cats[:, None, None]).max(axis=0)
# discard overlapping instances
target[masks.sum(0) > 1] = 255
target = Image.fromarray(target.astype(np.uint8))
target.putpalette(pallette)
plt.imshow(target)
plt.show()
mask.frPyObjects方法
针对以上代码中函数解释:
rles = coco_mask.frPyObjects,就是将标注的分割结果多边形坐标,转化为编码的RLE编码,然后coco_mask.decode(rles)解码为掩膜数组,cats就是每个分割标注的类别id。
if len(mask.shape) < 3:
mask = mask[..., None]
mask = mask.any(axis=2)
以上代码的含义:理想情况下,mask是[w, h, c],如果是[w, h]就加个c通道,any就是有值为前景为True,否则为背景。
四、COCO数据集的介绍
(1)分类
- 目标检测任务 Object Detection Task,可以细分为两大类:通过矩形框将待测目标框出来;把整个目标用一种颜色涂出来,包括它的轮廓都区分的比较明显(这种标注方式也称为实例分割)
- Stuff 分割任务 Stuff Segmentation Task,与前面任务不同之处:前面任务处理的是有特定大小、形状的物体,后面这个任务关注的是草、山、沙子没有特定空间范围、形状的物体
- 全景分割 Panoptic Segmentation Task,同时实现前面两种任务,既要检测出形状明显的人,又要检测出形状不明显的背景信息。
- 看图说话 Captioning Challenge,
- 人体关键点检测 Keypoint Detection Task
- 人体姿态密度检测任务 DensePose Task
(2)特点


如何加载并处理COCO文件?COCO API是官方提供的一些处理标注文件的函数。在python中pycocotools。
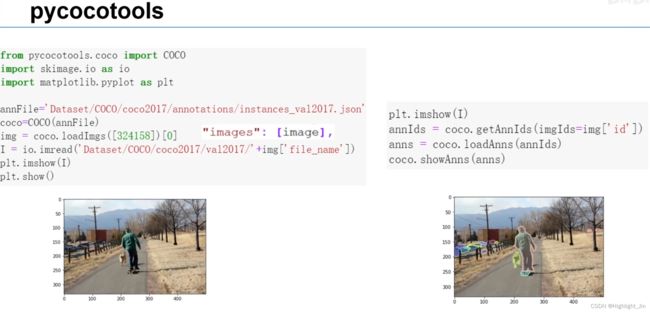

五、COCO API的使用
第一部分 详细解释
0.参考链接:
- COCO的API简介【python3仅针对Detection】
- 参考博文:太阳花的小绿豆–MS COCO数据集介绍以及pycocotools简单使用中4.验证mAP部分
配套的视频讲解:COCO数据集介绍以及pycocotools简单使用22:42开始
1.首先导入COCO的相关库
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
说明:(1)COCO类的初始化参数必须为标注文件或None,比如在YOLOX的官方源码coco.py中的代码如下:
self.coco = COCO(os.path.join(self.data_dir, "annotations", self.json_file)) # COCO这个类主要是解析json文件的,完全不需要去细究
执行完上述代码,会输出下图的提示信息:

(2)COCOeval类,共传入三个参数,参数1为COCO类的GT对象,也就是在(1)中加载的json文件;参数2为COCO类的result(DT)对象,也就是模型预测的结果转化成coco json format的格式;参数3指定哪个字段进行指标的计算。
annType = ["segm", "bbox", "keypoints"]
cocoEval = COCOeval(cocoGt, cocoDt, annType[1])
把真实值cocoGt和预测值cocoDt传入。
整合信息,将cocoGt与cocoDt联系起来,返回COCOeval类的对象。
【即该对象同时拥有cocoGt与cocoDt的信息并指定用cocoGt的annotations的哪个字段进行计算指标 】
2.加载GT对象和DT对象,一个是真实值,一个是预测值。
2.1加载GT对象,参考1中的说明(1)
self.coco = COCO(os.path.join(self.data_dir, "annotations", self.json_file)) # COCO这个类主要是解析json文件的,完全不需要去细究
cocoGt = self.dataloader.dataset.coco # 这个是解析出json文件的结果--GT
2.2加载DT对象
主要通过COCO API中的loadRes方法,用于加载算法的结果并创建可用于访问数据的API。YOLOX中通过以下3行代码进行实现。
_, tmp = tempfile.mkstemp() # 生成临时底层的临时文件
json.dump(data_dict, open(tmp, "w")) # 写入临时文件
cocoDt = cocoGt.loadRes(tmp)
# Load result file and return a result api object.
# 加载算法的结果并创建可用于访问数据的API。--DT指的是模型预测的检测结果
执行完以上代码,控制台会输出以下提示信息:
 3.整合信息,将GT和DT联系起来,返回COCOEval类的对象。通过以下代码:
3.整合信息,将GT和DT联系起来,返回COCOEval类的对象。通过以下代码:
annType = ["segm", "bbox", "keypoints"]
cocoEval = COCOeval(cocoGt, cocoDt, annType[1])
把真实值cocoGt和预测值cocoDt传入。
整合信息,将cocoGt与cocoDt联系起来,返回COCOeval类的对象。
【即该对象同时拥有cocoGt与cocoDt的信息并指定用cocoGt的annotations的哪个字段进行计算指标 】
执行完以上代码,不会输出任何信息。
注意:对于coco_eval, 需要的每个box的数据格式为[x_min, y_min, w, h],而YOLOX中我们预测的box格式是[x_min, y_min, x_max, y_max],所以需要转下格式
bboxes = xyxy2xywh(bboxes)
4.计算每张图片所设置的模型类别的结果,核心计算是iou。此处是计算所有类别的平均指标,如果需要计算指标的模型类别,参考上面参考链接中的第一条。
cocoEval.evaluate()
执行完以上代码,输出下图的信息(此处运行的是YOLOX的官方源码):

5.累计每张图片的评估结果
cocoEval.accumulate()
执行完以上代码,输出下图的信息:
![]()
![]() 6.打印结果
6.打印结果
cocoEval.summarize()

7.COCOeval类中的实例的属性cocoEval.eval代表了计算的结果,cocoEval.eval是一个字典,需要计算哪个指标从该字典中获取即可
 8.关于coco_eval.eval[‘precision’]的介绍参考链接:点击这里
8.关于coco_eval.eval[‘precision’]的介绍参考链接:点击这里
coco_eval.eval['precision']是一个5维的数组,维度解释如下。
dimension of precisions: [TxRxKxAxM]
precision has dims (iou, recall, cls, area range, max dets)
第一维T:IoU的10个阈值,从0.5到0.95间隔0.05。
第二维R:101个recall 阈值,从0到101
第三维K:类别,如果是想展示第一类的结果就设为0
第四维A:area 目标的大小范围 (all,small, medium, large)
第五维M:maxDets 单张图像中最多检测框的数量 三种 1,10,100
所以,coco_eval.eval['precision'][0, :, 0, 0, 2] 所表示的就是当IoU=0.5时,从0到100的101个recall对应的101个precision的值。
COCO目标检测测评指标
9.关于coco_eval.eval[‘recall’]的介绍参考链接:点击这里
T = len(p.iouThrs) # [0.5, 0.55, ..., 0.95]
R = len(p.recThrs) # [0, 0.01, 0.02, ..., 1]
K = len(p.catIds) if p.useCats else 1
A = len(p.areaRng) # [[0, 10000000000.0], [0, 1024], [1024, 9216], [9216, 10000000000.0]]
M = len(p.maxDets) # [1, 10, 100]
precision = -np.ones((T, R, K, A, M)) # -1 for the precision of absent categories
recall = -np.ones((T, K, A, M))
scores = -np.ones((T, R, K, A, M))
第二部分 一个完整的示例
整体完整的概览简易实例:
示例一:
coco_true = self.coco
coco_pre = coco_true.loadRes(self.results_file_name)
self.coco_evaluator = COCOeval(cocoGt=coco_true, cocoDt=coco_pre, iouType=self.iou_type)
self.coco_evaluator.evaluate()
self.coco_evaluator.accumulate()
print(f"IoU metric: {self.iou_type}")
self.coco_evaluator.summarize()
coco_info = self.coco_evaluator.stats.tolist() # numpy to list
示例二:

正式开始介绍:
0.数据准备(来源于第一部分参考链接中的第二个):
- COCO2017验证集json文件instances_val2017.json
链接: https://pan.baidu.com/s/1ArWe8Igt_q0iJG6FCcH8mg 密码: sa0j - 别人训练的Faster R-CNN(VGG16)在验证集上预测的结果predict_results.json
链接: https://pan.baidu.com/s/1h5RksfkPFTvH82N2qN95TA 密码: 8alm
1.代码逻辑介绍
(1)通过COCO这个类载入之前标注好的json文件,得到coco_true
(2)通过coco_true.loadRes()载入网络在数据集上的预测结果,得到coco_pre
(3)在COCOEval类中传入初始化参数cocoGT, cocoDT, iouType,cocoGT表示Ground Truth,cocoDT表示自己预测的信息,iouType表示传入计算map的类别。由于此处是目标检测,传入bbox参数。得到coco_evaluator变量
(4)分别调用.evaluate()、.accumulate()、.summarize()就能计算出我们预测的结果和真实的目标边界框的map了
2.代码整体示例
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
# accumulate predictions from all images
# 载入coco2017验证集标注文件
coco_true = COCO(annotation_file='./instances_val2017.json')
# 载入网络在coco2017验证集上预测的结果
coco_pre = coco_true.loadRes('predict_results.json')
coco_evaluator = COCOeval(cocoGt=coco_true, cocoDt=coco_pre, iouType='bbox')
coco_evaluator.evaluate()
coco_evaluator.accumulate()
coco_evaluator.summarize()
3.结果展示

参考链接
1.通过pycocotools获取每个类别的COCO指标
2.MS COCO数据集介绍以及pycocotools简单使用
3.COCO数据集格式解析(较好)
「解析」图像分割-mask的读取与保存
4.制作自己的数据集,附代码
categories表示所有的类别,有多少类就定义多少,类别的id从1开始,0为背景。
5.通过pycocotools获取每个类别的COCO指标
6.(1)COCO minitrain(github 链接)
- Link to the Json file is in the Readme.
- For images, there is a downloader available in the src folder.
(2)划分出小型COCO数据集 tiny-coco|mini-coco知乎博文
(3)miniCOCO可以使用的小型COCO数据集
(4)mscoco数据集_姿态估计数据集可视化【附代码】
7.COCO数据集格式、mask两种存储格式、官方包API详解(这个说得好,这个里面有mask的两种存储格式)
# 多边形填充, mask代表将要填充的初始图,polys存储所有的多边形边界坐标,1代表所填充的值
cv2.fillPoly(mask, polys, 1)
以上函数表示多边形填充, 参数的具体含义:mask代表将要填充的初始图,polys存储所有的多边形边界坐标,1代表所填充的值。
六、COCO数据集可视化
1.COCO数据集可视化程序(包括bbox和segmentation)
2.coco数据集格式介绍(这里面介绍了COCO格式的segmentation的字段以及iscrowd)
segmentation字段
segmentation格式有两种表示,polygon以及RLE。
- polygon格式比较简单,这些数按照相邻的顺序两两组成一个点的xy坐标,如果有n个数(必定是偶数),那么就是n/2个点坐标。
- RLE全称(run-length encoding),称变动长度编码法(run coding),在控制论中对于二值图像而言是一种编码方法,对连续的黑、白像素数(游程)以不同的码字进行编码。举个简单的例子:对于一个很长的二值的序列,如00000111100111110……,我们直接存储整个二值序列很浪费空间,如果使用RLE编码方法的话,我们存储的是其连续的0/1的数目,对于这个二值序列用RLE可以表示为54251……。RLE所占字节的大小和边界上的像素数量是正相关的。RLE格式带来的好处就是当基于RLE去计算目标区域的面积以及两个目标之间的unoin和intersection时会非常有效率。上面的segmentation中的counts数组和size数组共同组成了这幅图片中的分割 mask。其中size是这幅图片的宽高。因为在这幅图像中,每一个像素点要么在目标区域中,要么在背景中,所以这副图像的分割结果是一个bool量:如果该像素在目标区域中为true那么在背景中就是False;如果该像素在目标区域中为1那么在背景中就是0。对于一个240x320的图片来说,一共有76800个像素点,根据每一个像素点在不在目标区域中,我们就有了76800个bit,使用RLE编码格式存储分割结构既可以直观地表示这些bit,也可以大大节省存储空间。
iscrowd字段
iscrowd=0的时候,表示这是一个单独的物体,轮廓用Polygon(多边形的点)表示,iscrowd=1的时候表示多个没有分开的物体,轮廓用RLE编码表示(只要是iscrowd=0那么segmentation就是polygon格式;只要iscrowd=1那么segmentation就是RLE格式)。比如说一张图片里面有三个人,一个人单独站一边,另外两个搂在一起(标注的时候距离太近分不开了),这个时候,单独的那个人的注释里面的iscrowd=0,segmentation用Polygon表示,而另外两个用放在同一个annotation的数组里面用一个segmentation的RLE编码形式表示(注意,单个的对象(iscrowd=0)可能需要多个polygon来表示,比如这个对象在图像中被挡住了)。
3.COCO格式的数据,可视化polygon
1.单独可视化一张图片
# 单独可视化一张图片
import json
import cv2
from matplotlib import pyplot as plt
from matplotlib.cbook import pts_to_midstep
import numpy as np
print(cv2.__version__)
label_json = json.load(open('D:/COCO/datasets/annotations/instances_train2017.json', encoding='utf-8'))
img = cv2.imread('D:/COCO/datasets/train2017/JPEGImages/7_aug_1.jpg')
fig = img.copy()
images = label_json['images'][0]
image_id = images['id']
annotations = label_json['annotations']
for anno in annotations:
if anno['image_id'] == image_id:
points = np.array(anno['segmentation'][0], dtype=np.int).reshape(-1, 2) # 此处要指定int
cv2.polylines(fig, [points], isClosed=True, color=(255, 125, 125), thickness=5)
cv2.namedWindow('image', 2)
cv2.imshow('image', fig)
cv2.waitKey(0)
2.可视化每一张图的多边形看是否正确
在这里插入代码片