通过pycocotools获取每个类别的COCO指标
在目标检测任务中,我们常用的评价指标一般有两种,一种是使用Pascal VOC的评价指标,一种是更加严格的COCO评价指标,一般后者会更常用点。在计算COCO评价指标时,最常用的就是Python中的pycocotools包,但一般计算得到的结果是针对所有类别的,例如:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.512
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.798
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.573
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.191
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.397
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.565
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.443
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.625
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.632
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.319
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.531
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.677
有时我们希望得到更加细致的评价指标,例如每个类别的mAP(IoU=0.5),但在pycocotools包中没有很方便的方法获取我们想要的针对每个类别的指标(也可能是我没找到)。由于COCO的mAP是通过每个类别的AP取均值得到的,所以肯定是有办法获取到的。于是最近在网上找博文看,但并没找到获取的方法,于是自己简单的研究了一下,然后发现的一个获取每个类别的指标方法,可能有些繁琐,但也能实现我想要的结果。下面展示了,我获取到的每个类别的mAP(IoU=0.5),将这些值取平均刚好就是COCO评价指标中的第二项Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.798。
aeroplane : 0.8753141995190012
bicycle : 0.8466808382590398
bird : 0.8386935920049995
boat : 0.6672499606761113
bottle : 0.7188496493312971
bus : 0.8586308398228168
car : 0.870935280030881
cat : 0.9003052051938752
chair : 0.6304237906514033
cow : 0.8368120734488325
diningtable : 0.6166672284682384
dog : 0.8840554238307297
horse : 0.8607321365522124
motorbike : 0.8674344255722228
person : 0.9057066476290816
pottedplant : 0.5753096972905023
sheep : 0.858248932068312
sofa : 0.708768072293537
train : 0.8563969185870246
tvmonitor : 0.7775703364087823
接下来简单说下我的思路以及涉及的一些代码。因为平时打印COCO指标时是最后调用的COCOeval类的summarize()方法,而且在该方法中有注释Compute and display summary metrics for evaluation results.即计算并显示评估指标。然后分析了下代码后(代码下面有给出),发现对于目标检测任务(对应代码中iouType: 'bbox')代码执行流程是:_summarizeDets()->_summarize(),在_summarizeDets()函数中调用了12次_summarize()即分别对应着COCO输出指标的12个值。那_summarize()函数中就是计算每个结果的详细代码(既然在这里计算,那么肯定会涉及所有类别的性能指标)。仔细一看,果然找到了,所有对应Precision的结果全部保存在self.eval['precision']中,所有对应Recall的结果全部都保存在self.eval['recall']中。对于Precision,代码中有注释,维度信息为[TxRxKxAxM];对于Recall,维度信息为[TxKxAxM],那其中每个参数代表的含义是什么呢?在accumulate()方法中找到了以下代码,并进行了注释。
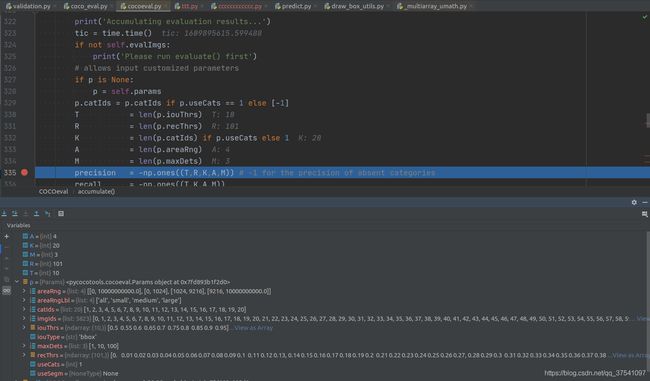
T = len(p.iouThrs) # [0.5, 0.55, ..., 0.95]
R = len(p.recThrs) # [0, 0.01, 0.02, ..., 1]
K = len(p.catIds) if p.useCats else 1
A = len(p.areaRng) # [[0, 10000000000.0], [0, 1024], [1024, 9216], [9216, 10000000000.0]]
M = len(p.maxDets) # [1, 10, 100]
precision = -np.ones((T, R, K, A, M)) # -1 for the precision of absent categories
recall = -np.ones((T, K, A, M))
scores = -np.ones((T, R, K, A, M))
T表示COCO计算时采用的10个IoU值,从0.5到0.95每间隔0.05取一个值。R表示COCO计算时采用的每一个概率阈值,这里是从0到1每间隔0.01(即一个百分点)取一个值,共101的值。K表示检测任务中检测的目标类别数,假设针对Pascal VOC数据集就为20。A表示检测任务中针对的目标尺度类型,第一个表示没有限制,第二个代表小目标(area < 32^2),第三个代表中等目标(32^2 < area < 96^2),第四个代表大目标(area > 96^2),共4个值。M为每张图片最大检测目标个数,COCO中有1,10,100共3个值。- 注意,precision,recall初始化时,所有的数值都是等于-1的。
- 下图展示以Pascal VOC数据集为例的参数值。
然后简单分析下_summarize()函数。在调用这个函数时有传入4个参数:
- 第一个
ap,如果为1表示要计算Precision,为0表示要计算Recall - 第二个
iouThr,表示计算指定的IoU的Precision或Recall,如果不传该参数,默认为None,表示计算[0.5, 0.55, …, 0.95]这10个值计算结果的均值。 - 第三个
areaRng,表示计算的目标尺度,有small、medium、large,默认参数是all表示计算所有尺度的信息。 - 第四个
maxDets,表示每张图片的检测目标个数,有1,10,100三个值。
接着以stats[0] = _summarize(1)为例,表示要计算COCO指标中的第一项,即Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ],
- 调用
_summarize()函数后传入了参数ap=1, - 计算
aind为[0]表示计算所有目标的尺度, - 计算
mind为[2]表示每张图检测目标数为100.

- 由于
ap=1,故s = self.eval['precision'],s中存储的是之前计算的所有Precison信息,注意维度信息[TxRxKxAxM]上面说过, - 接着
s = s[:,:,:,aind,mind]表示获取的是针对所有尺度目标以及每张图检测目标数为100的Precision信息, - 接着判断
if len(s[s>-1])==0:,上面说过Precison初始化时值都是等于-1的,如果该条件满足,则说明是没有计算到任何数值的,而一般是不会出现这种情况的所以进一步计算mean_s = np.mean(s[s>-1]),这就是基于上面得到的Precision矩阵求均值,注意计算均值时是不包括值为-1元素的,因为表达式中有通过s>-1筛选出所有大于-1的元素。 - 接着返回计算得到的
mean_s
剩下调用_summarize()函数的代码和刚刚上面讲的流程类似就不在赘述,官方的源码如下:
def summarize(self):
'''
Compute and display summary metrics for evaluation results.
Note this functin can *only* be applied on the default parameter setting
'''
def _summarize(ap=1, iouThr=None, areaRng='all', maxDets=100):
p = self.params
iStr = ' {:<18} {} @[ IoU={:<9} | area={:>6s} | maxDets={:>3d} ] = {:0.3f}'
titleStr = 'Average Precision' if ap == 1 else 'Average Recall'
typeStr = '(AP)' if ap == 1 else '(AR)'
iouStr = '{:0.2f}:{:0.2f}'.format(p.iouThrs[0], p.iouThrs[-1]) \
if iouThr is None else '{:0.2f}'.format(iouThr)
aind = [i for i, aRng in enumerate(p.areaRngLbl) if aRng == areaRng]
mind = [i for i, mDet in enumerate(p.maxDets) if mDet == maxDets]
if ap == 1:
# dimension of precision: [TxRxKxAxM]
s = self.eval['precision']
# IoU
if iouThr is not None:
t = np.where(iouThr == p.iouThrs)[0]
s = s[t]
s = s[:, :, :, aind, mind]
else:
# dimension of recall: [TxKxAxM]
s = self.eval['recall']
if iouThr is not None:
t = np.where(iouThr == p.iouThrs)[0]
s = s[t]
s = s[:, :, aind, mind]
if len(s[s > -1]) == 0:
mean_s = -1
else:
mean_s = np.mean(s[s > -1])
print(iStr.format(titleStr, typeStr, iouStr, areaRng, maxDets, mean_s))
return mean_s
def _summarizeDets():
stats = np.zeros((12,))
stats[0] = _summarize(1)
stats[1] = _summarize(1, iouThr=.5, maxDets=self.params.maxDets[2])
stats[2] = _summarize(1, iouThr=.75, maxDets=self.params.maxDets[2])
stats[3] = _summarize(1, areaRng='small', maxDets=self.params.maxDets[2])
stats[4] = _summarize(1, areaRng='medium', maxDets=self.params.maxDets[2])
stats[5] = _summarize(1, areaRng='large', maxDets=self.params.maxDets[2])
stats[6] = _summarize(0, maxDets=self.params.maxDets[0])
stats[7] = _summarize(0, maxDets=self.params.maxDets[1])
stats[8] = _summarize(0, maxDets=self.params.maxDets[2])
stats[9] = _summarize(0, areaRng='small', maxDets=self.params.maxDets[2])
stats[10] = _summarize(0, areaRng='medium', maxDets=self.params.maxDets[2])
stats[11] = _summarize(0, areaRng='large', maxDets=self.params.maxDets[2])
return stats
def _summarizeKps():
stats = np.zeros((10,))
stats[0] = _summarize(1, maxDets=20)
stats[1] = _summarize(1, maxDets=20, iouThr=.5)
stats[2] = _summarize(1, maxDets=20, iouThr=.75)
stats[3] = _summarize(1, maxDets=20, areaRng='medium')
stats[4] = _summarize(1, maxDets=20, areaRng='large')
stats[5] = _summarize(0, maxDets=20)
stats[6] = _summarize(0, maxDets=20, iouThr=.5)
stats[7] = _summarize(0, maxDets=20, iouThr=.75)
stats[8] = _summarize(0, maxDets=20, areaRng='medium')
stats[9] = _summarize(0, maxDets=20, areaRng='large')
return stats
if not self.eval:
raise Exception('Please run accumulate() first')
iouType = self.params.iouType
if iouType == 'segm' or iouType == 'bbox':
summarize = _summarizeDets
elif iouType == 'keypoints':
summarize = _summarizeKps
self.stats = summarize()
- 看完之后进一步思考,通过上面的分析,计算所有类别的COCO Precision时是通过
s = s[:,:,:,aind,mind]然后取的均值得到的,再次提醒Precision的原始维度信息是[TxRxKxAxM],上面说了其中K代表的是目标的类别数,如果在K对应的维度传入对应类别的索引不就可以获取得到对应类别的Precision信息了。比如在Pascal Voc数据集中第一个检测类别是aeroplane,那我们在K维度传入索引0不就能获取到对应类别aeroplane的Precision信息了吗。然后在T维度传入0.5不就是对应IoU=0.5时的Precision信息了吗。 - 接着我根据原
summarize()函数自己定义了一个summarize()函数,不建议在源码上进行修改,然后在传入的参数中新增了一个catId参数,默认为None计算所有类别的COCO指标,如果传入了对应的catId参数(例如我想计算对应aeroplane类别的COCO指标,那么传入catId=0)就计算对应类别的COCO指标,我们知道COCO总共会打印12个指标,其中第2个对应IoU=0.5的mAP值,所以计算每个类别的COCO指标后获取第2个指标就是对应Pascal VOC的评价指标(IoU=0.5).下面是我自己修改后的summarize()函数,改动很小。
def summarize(self, catId=None):
"""
Compute and display summary metrics for evaluation results.
Note this functin can *only* be applied on the default parameter setting
"""
def _summarize(ap=1, iouThr=None, areaRng='all', maxDets=100):
p = self.params
iStr = ' {:<18} {} @[ IoU={:<9} | area={:>6s} | maxDets={:>3d} ] = {:0.3f}'
titleStr = 'Average Precision' if ap == 1 else 'Average Recall'
typeStr = '(AP)' if ap == 1 else '(AR)'
iouStr = '{:0.2f}:{:0.2f}'.format(p.iouThrs[0], p.iouThrs[-1]) \
if iouThr is None else '{:0.2f}'.format(iouThr)
aind = [i for i, aRng in enumerate(p.areaRngLbl) if aRng == areaRng]
mind = [i for i, mDet in enumerate(p.maxDets) if mDet == maxDets]
if ap == 1:
# dimension of precision: [TxRxKxAxM]
s = self.eval['precision']
# IoU
if iouThr is not None:
t = np.where(iouThr == p.iouThrs)[0]
s = s[t]
# 判断是否传入catId,如果传入就计算指定类别的指标
if isinstance(catId, int):
s = s[:, :, catId, aind, mind]
else:
s = s[:, :, :, aind, mind]
else:
# dimension of recall: [TxKxAxM]
s = self.eval['recall']
if iouThr is not None:
t = np.where(iouThr == p.iouThrs)[0]
s = s[t]
# 判断是否传入catId,如果传入就计算指定类别的指标
if isinstance(catId, int):
s = s[:, catId, aind, mind]
else:
s = s[:, :, aind, mind]
if len(s[s > -1]) == 0:
mean_s = -1
else:
mean_s = np.mean(s[s > -1])
print_string = iStr.format(titleStr, typeStr, iouStr, areaRng, maxDets, mean_s)
return mean_s, print_string
stats, print_list = [0] * 12, [""] * 12
stats[0], print_list[0] = _summarize(1)
stats[1], print_list[1] = _summarize(1, iouThr=.5, maxDets=self.params.maxDets[2])
stats[2], print_list[2] = _summarize(1, iouThr=.75, maxDets=self.params.maxDets[2])
stats[3], print_list[3] = _summarize(1, areaRng='small', maxDets=self.params.maxDets[2])
stats[4], print_list[4] = _summarize(1, areaRng='medium', maxDets=self.params.maxDets[2])
stats[5], print_list[5] = _summarize(1, areaRng='large', maxDets=self.params.maxDets[2])
stats[6], print_list[6] = _summarize(0, maxDets=self.params.maxDets[0])
stats[7], print_list[7] = _summarize(0, maxDets=self.params.maxDets[1])
stats[8], print_list[8] = _summarize(0, maxDets=self.params.maxDets[2])
stats[9], print_list[9] = _summarize(0, areaRng='small', maxDets=self.params.maxDets[2])
stats[10], print_list[10] = _summarize(0, areaRng='medium', maxDets=self.params.maxDets[2])
stats[11], print_list[11] = _summarize(0, areaRng='large', maxDets=self.params.maxDets[2])
print_info = "\n".join(print_list)
if not self.eval:
raise Exception('Please run accumulate() first')
return stats, print_info
然后通过多次调用自己修改后的summarize()函数并传入相应的参数就能得到所有想要的结果,其中coco_eval是COCOeval类,并且之前已经调用过accumulate()函数。
# calculate COCO info for all classes
coco_stats, print_coco = summarize(coco_eval)
# calculate voc info for every classes(IoU=0.5)
voc_map_info_list = []
for i in range(len(category_index)):
stats, _ = summarize(coco_eval, catId=i)
voc_map_info_list.append(" {:15}: {}".format(category_index[i + 1], stats[1]))
print_voc = "\n".join(voc_map_info_list)
print(print_voc)
# 将验证结果保存至txt文件中
with open("record_mAP.txt", "w") as f:
record_lines = ["COCO results:",
print_coco,
"",
"mAP(IoU=0.5) for each category:",
print_voc]
f.write("\n".join(record_lines))
保存在record_mAP.txt文件中的信息:
COCO results:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.512
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.798
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.573
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.191
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.397
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.565
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.443
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.625
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.632
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.319
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.531
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.677
mAP(IoU=0.5) for each category:
aeroplane : 0.8753141995190012
bicycle : 0.8466808382590398
bird : 0.8386935920049995
boat : 0.6672499606761113
bottle : 0.7188496493312971
bus : 0.8586308398228168
car : 0.870935280030881
cat : 0.9003052051938752
chair : 0.6304237906514033
cow : 0.8368120734488325
diningtable : 0.6166672284682384
dog : 0.8840554238307297
horse : 0.8607321365522124
motorbike : 0.8674344255722228
person : 0.9057066476290816
pottedplant : 0.5753096972905023
sheep : 0.858248932068312
sofa : 0.708768072293537
train : 0.8563969185870246
tvmonitor : 0.7775703364087823
更详细的代码可参考我的Github-> pytorch_object_detection-> faster_rcnn->
validation.py:
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing