用树莓派做一个语音机器人
早就想写一篇语音机器人的文章,凑巧这两天受委托做个树莓派语音机器人,又复习一下流程熟悉了过程才准备写一篇文章,这是基于图灵机器人和百度api的语音助手。
目录
- 准备
-
- 硬件准备
- 包的准备
- 准备机器人
-
- 录音
- 语音转文字
- 图灵机器人回复
- 文字转语音
- 完整代码
准备
硬件准备
首先我们需要给树莓派安装麦克风和扬声器,当然没有扬声器也可以直接用耳机,然后进行调试。
输入:
lsusb

或者
arecord -l

识别成功之后进行录音
arecord -D "plughw:1,0" -f dat -c 1 -r 16000 -d 5 test.wav
如果发现录音杂音很大的话可以尝试使用alsamixer进行调音
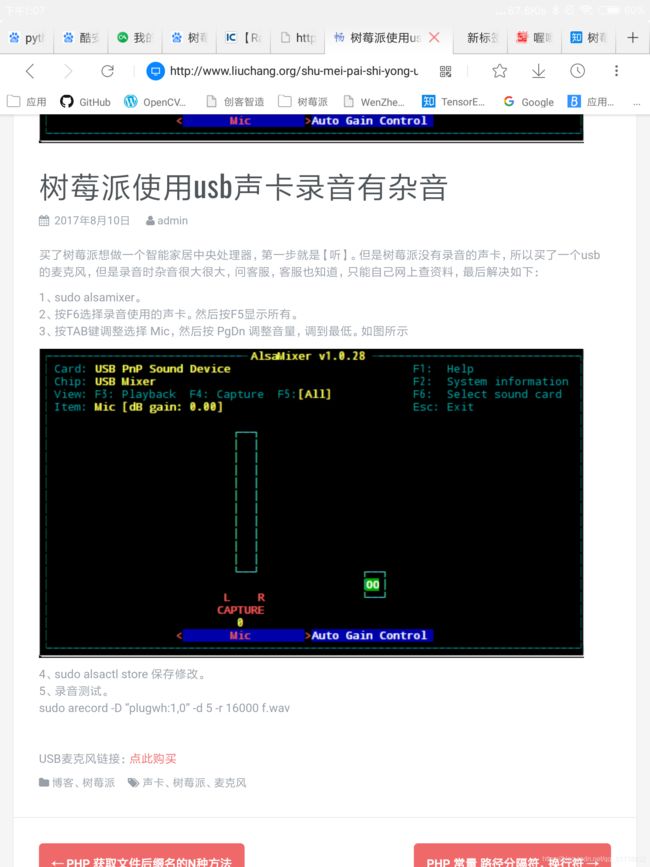
包的准备
我们一般需要下载的包如下
pip3 install baidu-aip
pip3 install requests
准备机器人
注意我们一定要子啊所有开始之前加入
# coding=utf-8
录音
录音一般都很简单,用下面代码就可以
import os
os.system('sudo arecord -D "plughw:1,0" -f S16_LE -r 16000 -d 4 ' + path)
但是我在使用的时候第一次用还可以,但是之后就会出现
arecord main:828的错误
这个错误我找了许多方法都没有解决于是我就换了个录音方法,比较麻烦,看个人需求,这里需要下载一个pyaudio包
pip3 install pyaudio
# 或者
sudo apt-get install portaudio19-dev
pip3 install pyaudio
def SoundRecording(path):
import pyaudio
import wave
import os
import sys
CHUNK = 512
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = path
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("recording...")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("done")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
语音转文字
这个就比较简单了,我们直接调用百度api就可以,我们先去百度AI的控制台申请个应用找到ID,AK,SK,然后获取access_token
APP_ID = '22894511'
API_KEY = 'En7e3iR8dHO1F7Hx3Fy7M0vd'
SECRET_KEY = 'c1591BrrbodXP5zQuBcQSNim8xcL6ZiE'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 将语音转文本STT
host = f'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=6KLdtAifYT46PtyzULAGpIzu&client_secret=tCEEz7LC4XfD2RA4ojgdOUvBBd7i3T4Y'
access_token = requests.get(host).json()["access_token"]
def SpeechRecognition(path):
with open(path, 'rb') as fp:
voices = fp.read()
try:
# 参数dev_pid:1536普通话(支持简单的英文识别)、1537普通话(纯中文识别)、1737英语、1637粤语、1837四川话、1936普通话远场
result = client.asr(voices, 'wav', 16000, {'dev_pid': 1537, })
result_text = result["result"][0]
print("you said: " + result_text)
return result_text
except KeyError:
print("KeyError")
图灵机器人回复
这里我们只需要将转成的文本内容发送给图灵机器人就可以了,这时我们也需要申请一个图灵机器人账号才可以,又图灵的AK
# 图灵机器人的API_KEY、API_URL
turing_api_key = "自己的AK"
api_url = "http://openapi.tuling123.com/openapi/api/v2" # 图灵机器人api网址
headers = {'Content-Type': 'application/json;charset=UTF-8'}
def TuLing(text_words=""):
req = {
"reqType": 0,
"perception": {
"inputText": {
"text": text_words
},
"selfInfo": {
"location": {
"city": "天津",
"province": "天津",
"street": "天津科技大学"
}
}
},
"userInfo": {
"apiKey": turing_api_key,
"userId": "Leosaf"
}
}
req["perception"]["inputText"]["text"] = text_words
response = requests.request("post", api_url, json=req, headers=headers)
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"]
print("AI Robot said: " + result)
return result
文字转语音
返回的值是文字,我们肯定会希望它能够转化为语音,这样才感觉好玩。
host = f'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=6KLdtAifYT46PtyzULAGpIzu&client_secret=tCEEz7LC4XfD2RA4ojgdOUvBBd7i3T4Y'
access_token = requests.get(host).json()["access_token"]
def SpeechSynthesis(text_words=""):
result = client.synthesis(text_words, 'zh', 1, {'per': 4, 'vol': 10, 'pit': 9, 'spd': 5})
if not isinstance(result, dict):
with open('app.mp3', 'wb') as f:
f.write(result)
os.system('mpg321 app.mp3')
完整代码
这里的代码我是用的pyaudio,不需要可以自行修改
# coding=utf-8
import json
import os
import requests
from aip import AipSpeech
BaiDu_APP_ID = "22894511"
API_KEY = "En7e3iR8dHO1F7Hx3Fy7M0vd"
SECRET_KEY = "c1591BrrbodXP5zQuBcQSNim8xcL6ZiE"
client = AipSpeech(BaiDu_APP_ID, API_KEY, SECRET_KEY)
turing_api_key = '67d5386150e248fea4af3db80f4ca1ae'
api_url = 'http://openapi.tuling123.com/openapi/api/v2'
headers = {'Content-Type': 'application/json;charset=UTF-8'}
# 获取accecc_token
host = f'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=6KLdtAifYT46PtyzULAGpIzu&client_secret=tCEEz7LC4XfD2RA4ojgdOUvBBd7i3T4Y'
access_token = requests.get(host).json()["access_token"]
running = True
resultText, path = "", "output.wav"
# 录音模块
def SoundRecording(path):
import pyaudio
import wave
import os
import sys
CHUNK = 512
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = path
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("recording...")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("done")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
# 语音转文字模块
def SpeechRecognition(path):
with open(path, 'rb') as fp:
voices = fp.read()
try:
# 参数dev_pid:1536普通话(支持简单的英文识别)、1537普通话(纯中文识别)、1737英语、1637粤语、1837四川话、1936普通话远场
result = client.asr(voices, 'wav', 16000, {'dev_pid': 1537, })
result_text = result["result"][0]
print("you said: " + result_text)
return result_text
except KeyError:
print("KeyError")
# 图灵回复模块
def TuLing(text_words=""):
req = {
"reqType": 0,
"perception": {
"inputText": {
"text": text_words
},
"selfInfo": {
"location": {
"city": "天津",
"province": "天津",
"street": "天津科技大学"
}
}
},
"userInfo": {
"apiKey": turing_api_key,
"userId": "Leosaf"
}
}
req["perception"]["inputText"]["text"] = text_words
response = requests.request("post", api_url, json=req, headers=headers)
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"]
print("AI Robot said: " + result)
return result
#文字转语音模块
def SpeechSynthesis(text_words=""):
result = client.synthesis(text_words, 'zh', 1, {'per': 4, 'vol': 10, 'pit': 9, 'spd': 5})
if not isinstance(result, dict):
with open('app.mp3', 'wb') as f:
f.write(result)
os.system('mpg321 app.mp3')
# 循环模块
if __name__ == '__main__':
while running:
SoundRecording(path)
resultText = SpeechRecognition(path)
response = TuLing(resultText)
if '退出' in response or '再见' in response or '拜拜' in response:
running = False
SpeechSynthesis(response)