先用knn对数据集进行预处理再利用神经网络对数据集进行分类_干货 | 6大商品数据分析模型分享!...
 Kervin_Chan | 作者 掘金 | 来源 https://juejin.im/post/6844903967416123399
Kervin_Chan | 作者 掘金 | 来源 https://juejin.im/post/6844903967416123399
本节将介绍几个常用的商品分析模型,包括商品价格敏感度模型、新产品市场定位模型、销售预测模型、商品关联销售模型、异常订单检测模型、商品规划的最优组合。
1
商品价格敏感度模型 商品价格敏感度模型 是指通过研究找到用户对于价格是否敏感以及敏感程度的价格杠杆。利用价格敏感度模型可以辅助于销售定价,促销活动的折扣方式、参考价格、价格变动幅度等方面的参考。例如: 促销活动时是否应该包含M2商品; 当商品M3提价100元时,订单量会如何变化;在商品详情页的参考价格应该定为多少才能让客户感觉到已经降价并触发下单动作;满减、满返、跨品类用券等哪些方式最适合M4商品。商品价格敏感度分析可以通过两种方式实现:
1.调研问卷法
通过调研问卷的形式针对关注的品类或商品做调研分析是比较通用的一种方法。这种方法可以获得品类详细信息,并且可以通过问卷设置不同的关注信息点,收集到的信息更符合实际需求。 但是,当面临新的价格敏感度分析需求时,通常都需要重新开展调研分析工作。这种方式实施起来周期较长且反馈结果较慢,另外,当要收集的商品信息较多时,可能很难获得完整数据。2.数据建模法
通过数据建模的方式建立商品价格和销售量之间的关系模型是研究价格敏感度的有效方法。 这种方法实施起来相对简单: 首先,收集不同价格下的销售数据。价格敏感度模型需要有基于不同价格下的销售数据产生,因此需要商品运营部门针对性的做调价。这种调价动作根据需求的不同,可能是长期的,也可能是短期的。 长期的调价是一种“自然状态”,因为在一个较长周期内商品会经历生命周期的不同阶段,并结合商品促销、打折等运营工作产生多种价格和销售数据;而短期的调价更多的是为了采集数据而产生。 其次,数据建模分析。商品价格敏感度模型关注的主要是价格和销量之间的关系,可以用回归方法来解决。在回归方法中,自变量中除了价格外,还需要包含其他两类信息:商品信息,商品品类、上市时间、同期竞争对手价格、是否参与促销活动、促销方式、折扣力度、通用属性等。
客户信息,客户性别、年龄、收入、学历、会员级别、历史订单量、品类偏好度、活跃度、价值度等。
2
新产品市场定位模型 新产品市场定位分析用于当企业新生产或策划一款产品时,需要根据市场上现有的竞争对手产品情况做定位分析。 该分析的目的是评估新产品与哪些产品能形成竞品关系,可以针对性地找到与竞品的差异性和优势,例如功能特点、使用周期、产品质量等,从而应用到产品定价、市场宣传、渠道推广等方面。 新产品市场定位分析可以通过基于相似度的方法实现。例如: 使用非监督式的KNN(K近邻),模型的核心是通过对新产品的数据与现有数据的比较,发现跟新产品相似的其他产品。通过KNN实现新产品市场定位分析的步骤如下:
步骤1:数据准备。先准备好要训练的数据集,由于这不是一个分类应用,因此数据集中只包含不同竞品的特征变量即可,无需目标变量。
步骤2:数据预处理。预处理过程根据数据集情况可能包括二值化标志转换、缺失值处理、异常值处理、数据标准化等。需要注意的是, 由于是基于距离的计算,分类和顺序变量需要做二值化转换,异常值(包括量纲和值的异常)都会对相似度产生重大影响。
步骤3:建立KNN模型并训练模型。直接使用NearestNeighbors方法建立模型后使用fit方法做训练。
步骤4:找到新产品最近的K个相似产品。使用KNN模型的 kneighbors方法获得指定数量的K个近邻。
from sklearn.neighbors import NearestNeighbors #导入NearestNeighbors库
X = [[0., 0.1, 0.6], [0., 1.5, 0.3], [1.2, 1.6, 0.5]] #定义训练集,训练集包含3 条记录,每个记录包含3个特征变量
neigh = NearestNeighbors(n_neighbors=1) #建立非监督式的KNN模型对象 neigh.fit(X) # 训练模型对象
new_X = [[1., 1., 1.]] #要预测的新产品数据 print(neigh.kneighbors(new_X)) #打印输出新产品最相似的训练集产品(array([[ 0.80622577]]), array([[2]]))第一个数字是与新产品数据最相似的产品的距离
第二个数字是对应最相似产品记录的索引值(注意索引值从0开始,2表达第三个)
3
销售预测模型 销售预测模型 根据历史的销售数据来预测未来可能产生的销售情况 。该模型常用于促销活动前的费用申请、目标制定、活动策略等的辅助支持。 销售预测模型通常要得到的结果为未来会产生多少销售量、收入、订单量等具体数值,可通过时间序列、回归和分类三种方法实现。基于时间序列做销售预测。使用时间序列做销售预测的方法常用于没有太多可用的自变量的场景下,只能基于历史的销售数据做预测性分析。有关时间序列的更多话题,后面再讲。
基于回归做销售预测。基于可控的特征变量建立回归模型来预测未来的销售情况是更常用的方法,有关回归模型的更多内容,后面再讲。
基于分类做销售预测。分类方法是针对每个销售客户产生的是否购买的预测分类,然后再基于能产生购买的预测分类做客单价、订单量和收入的分析。这是一种对于具体数值的变通实现思路。有关分类分析的更多内容,后面再讲。
4
商品关联销售模型 商品关联销售模型 主要用来解决哪些商品可以一起售卖或不能一起打包组合的问题。关联销售是商品销售的常态,也是促进单次销售收入和拉升复购效果的有效手段。 商品关联销售模型的实现方式是关联类算法,包括Apriori、FP-Growth、PrefixSpan、SPADE、AprioriAll、AprioriSome等,主要实现的是基于一次订单内的交叉销售以及基于时间序列的关联销售。 关联销售算法的实现步骤上与普通的监督式和监督式算法略有不同,原因是关联分析对于数据集的要求不同。一般包括三种数据源格式:第一种是事务型交易数据,典型的数据格式是每个数据行以订单 ID或客户ID作为关联分析的参照维度,如果同一个订单内有多少个商品,那么将会有多个数据行记录,如下图:
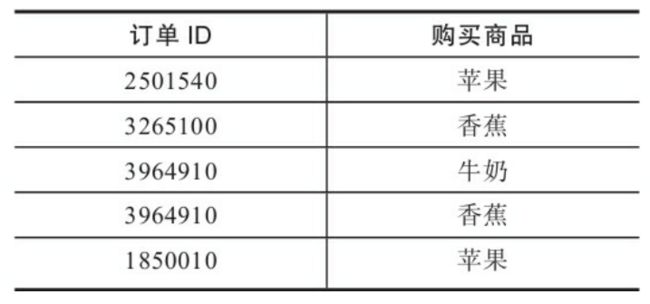
第二种是合并后的交易数据,数据格式是每个数据行以订单ID或客户ID作为分析的参照维度,如果同一个订单内有多个商品,那么多个商品会被合并到一条记录中,如下图:

第三种是真值表格数据,每个数据行是每个订单ID或客户ID,列是每个要关联项目的是否购买值,通常以T或F来表示,如下图:
 以上三种数据格式中,第一种和第二种常见于企业内部的源数据环境或数据仓库,第三种需要经过ETL处理得到,很多第三方工具也可以提供这种数据形式。如果企业内不具备能够直接做关联分析的数据,则需要做对应处理。
以上三种数据格式中,第一种和第二种常见于企业内部的源数据环境或数据仓库,第三种需要经过ETL处理得到,很多第三方工具也可以提供这种数据形式。如果企业内不具备能够直接做关联分析的数据,则需要做对应处理。
5
异常订单检测 异常订单检测 用来识别在订单(尤其是促销活动中的订单)中的异常状态,目标找到非普通用户的订单记录,例如黄牛订单、恶意订单、商家刷单等。黄牛订单会大量削减促销对普通用户的吸引程度,使得促销权益和利益被一小部分人获取,而非给到目标会员。
恶意订单则更加危险,很多竞争对手间会通常这种方式在促销活动中,将大量的商品库存通过订单的方式锁定,然后再活动结束后通过取消、退货等方式释放库存。这种方式将使促销活动由于无法真正卖出商品而无法实现促销的目的,同时还会消耗公司大量的人力、物力,是各个公司都非常反感的恶意竞争方式。
商家刷单是一种常见的用于提升商家排名的方式,通常由商家来安排内部或关联人员大量购买商品,以形成商家流量和销售提升的目的。
基于监督式的分类算法:将历史已经识别出来的真实异常订单数据通过分类模型(例如SVM、随机森林等)做训练,然后应用新数据做分类预测,看预测结果是否属于异常订单。
基于非监督式的算法:通过非监督式算法(例如OneClassSVM)基于历史的数据做训练,然后针对新的数据做判别,找到存在异常可能性标签的订单列表。
6
商品规划的最优组合 在做商品促销或广告宣传时,通常企业会面临多种组合策略,它是在一定限制条件下考虑通过何种组合策略来实现最大或最小目标。此时,可以考虑使用线性规划方法。 线性规划 (Linear programming,LP)是运筹学中研究比较早、方式相对成熟且实用性非常强的研究领域,主要用来辅助人们进行科学管理,目标是合理地利用有限的人力、物力、财力等资源作出的最优决策。 解决简单线性规划问题的最直接的方法是图解法,即借助直线与平面区域的交点求解直线在y轴上的截距的最大值或最小值。 在做线性规划时涉及几个概念:未知数:影响决策主要变量或因素。
约束条件:解决线性规划问题时已知的并须遵守的前提条件。
目标函数:用来表示未知数与目标变量关系的函数,线性规划中一般是线性函数。
可行域:满足优化问题约束条件的解叫作可行解,由所有可行解组成的集合叫作可行域。
最优解:满足目标函数最大化或最小化目标的最优的解。
步骤1:找到影响目标的主要因素,它们是规划中的未知数。
步骤2:基于未知数确定线性约束条件。
步骤3:由未知数和目标之间的关系确定目标函数。
步骤4:找到直角坐标系中的可行域。
步骤5:在可行域内求目标函数的最优解及最优值。
 由于这是一个简单二维变量,因此可以先画出直角坐标图和可行域,然后基于目标函数找到最优解位置
由于这是一个简单二维变量,因此可以先画出直角坐标图和可行域,然后基于目标函数找到最优解位置 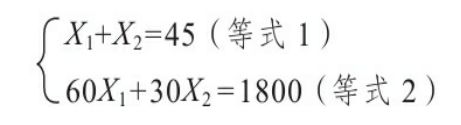 通过图可以发现最优解是目标函数与X1+X2=45和60X1+30X2=1800的交点,求解两个函数的解用到的是九年义务教育阶段基本数学知识。
通过图可以发现最优解是目标函数与X1+X2=45和60X1+30X2=1800的交点,求解两个函数的解用到的是九年义务教育阶段基本数学知识。 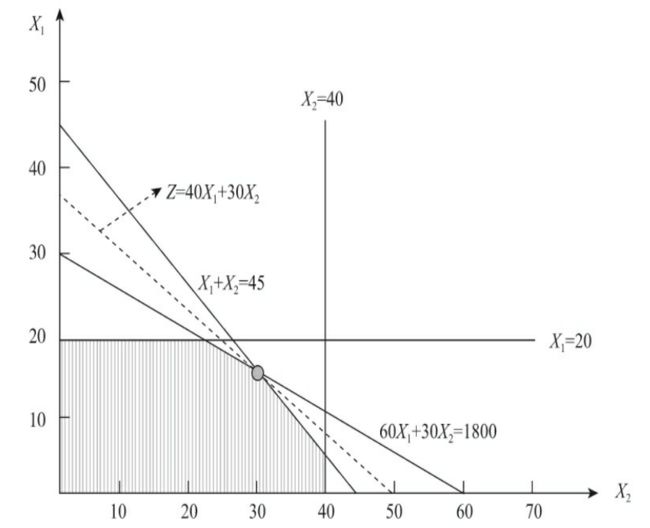
步骤1:将等式1做转换:X1=45-X2 然后将转换后的X1代入等式2,并依次求解:
步骤2:60(45-X2)+30X2=1800
步骤3:2700-60X2+30X2=1800
步骤4:2700-30X2=1800
步骤5:30X2=900
步骤6:X2=30
步骤7:X1=45-30=15
步骤8:然后将X1和X2带入目标函数:z=40X1+30X2=40×15+30×30=1500
Java极客们都在关注「JavaGeek」,专注分享Java技术干货,包括多线程、JVM、Spring Boot、Spring Cloud、Intellij IDEA、Dubbo、Zookeeper、Redis、架构设计、微服务等。
关注并回复「Java学习」获得 1024G Java学习资料 推荐阅读40000字笔记!HiveSQL再不懂来找我!内部泄露版!互联网大厂的薪资和职级一览好文!10年数据分析老司机的深度思考!VS Code、Atom、Sublime Text:谁才是真正的编辑器之王?太强了!这个 Jupyter notebook 离线工具可以用一辈子!经典的SparkSQL/Hive-SQL/MySQL面试-练习题“干货学习,点赞三连↓
推荐阅读40000字笔记!HiveSQL再不懂来找我!内部泄露版!互联网大厂的薪资和职级一览好文!10年数据分析老司机的深度思考!VS Code、Atom、Sublime Text:谁才是真正的编辑器之王?太强了!这个 Jupyter notebook 离线工具可以用一辈子!经典的SparkSQL/Hive-SQL/MySQL面试-练习题“干货学习,点赞三连↓