特征值分解(Eigen Value Decomposition,EVD)、奇异值分解(Singular Value Decomposition,SVD)原理、公式推导及应用
1 正交矩阵&正交变换
- 正交变换是保持图形形状和大小不变的几何变换,包含旋转、平移、轴对称及这些变换的复合形式,正交变换可以保持向量的长度和向量之间的角度不变。特别的,标准正交基经正交变换后仍为标准正交基。
- 在有限维的空间中,正交变换在标准正交基下的矩阵表示为正交矩阵,其所有行和所有列也都各自构成一组标准正交基。
- 同时,正交变换的逆变换也是正交变换,后者的矩阵表示是前者矩阵表示的逆。
2 特征值分解(Eigen Value Decomposition,EVD)
2.1 定义
【百度百科】特征分解(Eigendecomposition),又称谱分解(Spectral decomposition)是将矩阵分解为由其特征值和特征向量表示的矩阵之积的方法。需要注意只有对可对角化矩阵才可以施以特征分解。
如果矩阵 A A A是一个 m × m m \times m m×m的实对称矩阵(即 A = A T A=A^T A=AT),那么它可以被分解为如下形式:
A = Q Λ Q T = Q [ λ 1 0 ⋯ 0 0 λ 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ λ m ] Q T (2-1) A=Q \Lambda Q^T=Q \begin{bmatrix} \lambda_1 & 0 & \cdots & 0 \\ 0 & \lambda_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda_m \end{bmatrix} Q^T \tag{2-1} A=QΛQT=Q⎣⎢⎢⎢⎡λ10⋮00λ2⋮0⋯⋯⋱⋯00⋮λm⎦⎥⎥⎥⎤QT(2-1)
其中 Q Q Q为标准正交阵,即有 Q Q T = I QQ^T=I QQT=I, Λ \Lambda Λ为 m × m m \times m m×m的对角矩阵, λ i \lambda_i λi称为特征值, Q Q Q为特征矩阵, Q Q Q中的列向量 q i q_i qi称为特征向量。
2.2 推导
假设存在 m × m m \times m m×m的满秩对称矩阵 A A A,它有 m m m个不同的特征值 λ i ( i = 1 , 2 , . . . , m ) \lambda_i(i=1,2,...,m) λi(i=1,2,...,m),对应的特征向量为 x i ( i = 1 , 2 , . . . , m ) x_i(i=1,2,...,m) xi(i=1,2,...,m)( x i x_i xi为 m m m维列向量),则有:
A x 1 = λ 1 x 1 A x 2 = λ 2 x 2 ⋯ A x m = λ m x m (2-2) \begin{array}{cc} Ax_1=\lambda_1 x_1 \\ Ax_2=\lambda_2 x_2 \\ \cdots \\ Ax_m=\lambda_m x_m \end{array} \tag{2-2} Ax1=λ1x1Ax2=λ2x2⋯Axm=λmxm(2-2)
令 U = [ x 1 x 2 ⋯ x m ] U=\begin{bmatrix} x_1 & x_2 & \cdots & x_m \end{bmatrix} U=[x1x2⋯xm],则上式可以表示为矩阵形式:
A U = U Λ (2-3) AU=U\Lambda \tag{2-3} AU=UΛ(2-3)
Λ = [ λ 1 0 ⋯ 0 0 λ 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ λ m ] (2-4) \Lambda= \begin{bmatrix} \lambda_1 & 0 & \cdots & 0 \\ 0 & \lambda_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda_m \end{bmatrix} \tag{2-4} Λ=⎣⎢⎢⎢⎡λ10⋮00λ2⋮0⋯⋯⋱⋯00⋮λm⎦⎥⎥⎥⎤(2-4)
进一步就可以得到A的特征值分解:
A = U Λ U − 1 = U Λ U T (2-5) A=U\Lambda U^{-1}=U\Lambda U^T \tag{2-5} A=UΛU−1=UΛUT(2-5)
3 奇异值分解(Singular Value Decomposition,SVD)
3.1 定义
【百度百科】奇异值分解(Singular Value Decomposition)是线性代数中一种重要的矩阵分解,奇异值分解则是特征分解在任意矩阵上的推广。在信号处理、统计学等领域有重要应用。
如果 A A A是一个 m × n m \times n m×n阶矩阵,则存在一个分解使得:
A = U Σ V T A=U \Sigma V^T A=UΣVT
其中 U U U和 V V V分别为 m × m m \times m m×m和 n × n n \times n n×n的酉矩阵/单位正交矩阵(即 U U T = U T U = I , V V T = V T V = I UU^T=U^TU=I,VV^T=V^TV=I UUT=UTU=I,VVT=VTV=I)。 U U U称为左奇异矩阵, V V V称为右奇异矩阵, Σ \Sigma Σ对角线上的元素 σ i \sigma_i σi即为 M M M的奇异值。一般地 Σ \Sigma Σ有如下形式:
Σ = [ σ 1 0 ⋯ 0 0 σ 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ 0 ] m × n (3-1) \Sigma= \begin{bmatrix} \sigma_1 & 0 & \cdots & 0 \\ 0 & \sigma_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 0 \end{bmatrix}_{m \times n} \tag{3-1} Σ=⎣⎢⎢⎢⎡σ10⋮00σ2⋮0⋯⋯⋱⋯00⋮0⎦⎥⎥⎥⎤m×n(3-1)
3.2 推导
在矩阵的特征值分解中,矩阵 A A A的行列维度是相同的,但在实际应用中,矩阵往往是非方阵、非对称的(如点云配准问题等)。为了对这类矩阵进行分解,我们引入奇异值分解(SVD)。
假设矩阵 A A A的维度为 m × n ( m ≠ n ) m \times n (m \not= n) m×n(m=n),虽 A A A不是方阵,但 A A T AA^T AAT和 A T A A^TA ATA均为方阵,其维度分别为 m × m m \times m m×m和 n × n n \times n n×n。因此可以对这两个方阵分别进行特征值分解:
A A T = P Λ 1 P T A T A = Q Λ 2 Q T (3-2) AA^T= P \Lambda_1 P^T \\ A^TA= Q \Lambda_2 Q^T \tag{3-2} AAT=PΛ1PTATA=QΛ2QT(3-2)
其中 Λ 1 \Lambda_1 Λ1和 Λ 2 \Lambda_2 Λ2均为对角矩阵,且两个方阵具有相同的非零特征值 σ 1 , σ 2 , . . . , σ k {\sigma_1,\sigma_2,...,\sigma_k} σ1,σ2,...,σk,其中 k ≤ m i n ( m , n ) k \leq min(m,n) k≤min(m,n)。这样就可以进一步得到奇异值分解的公式:
A = P Λ Q T (3-3) A=P \Lambda Q^T \tag{3-3} A=PΛQT(3-3)
接下来通过更直观的方式对SVD的原理和推导过程进行说明(参考:You Don’t Know SVD (Singular Value Decomposition))。
首先从最简单的二维坐标说起,任何力矢量都可以沿 x x x和 y y y轴分解:
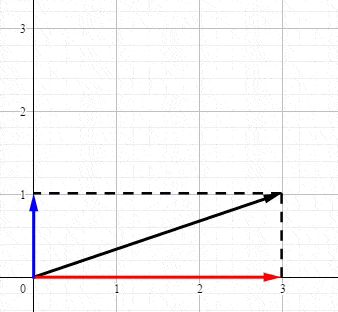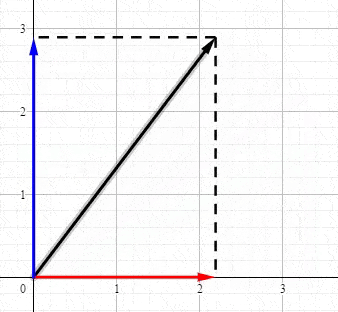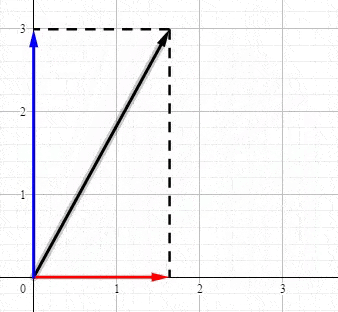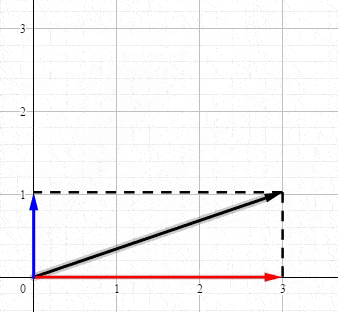
这其实就是最简单的SVD,SVD就是将向量分解到正交轴上(正交变换前的正交轴和正交变换后的正交轴)。
如下图,我们将向量 a a a进行分解:
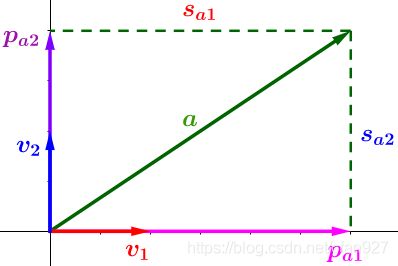
可以得到3个信息:
- 投影方向(单位向量 v 1 v_1 v1和 v 2 v_2 v2):表示沿着 x x x和 y y y轴的投影方向,这也可以为其它的正交轴;
- 投影长度(线段 s a 1 s_{a1} sa1和 s a 2 s_{a2} sa2)
- 投影向量( p a 1 p_{a1} pa1和 p a 2 p_{a2} pa2):通过投影向量可以反向计算出原始向量 a a a,同时我们可以发现 p a 1 = s a 1 ∗ v 1 p_{a1}=s_{a1}*v_1 pa1=sa1∗v1, p a 2 = s a 2 ∗ v 2 p_{a2}=s_{a2}*v_2 pa2=sa2∗v2
那么我们就可以得到一个关键结论:
任何向量都可以表示为:
- 投影方向的单位矢量( v 1 v_1 v1, v 2 v_2 v2,…)
- 在投影方向上的长度( s a 1 s_{a1} sa1和 s a 2 s_{a2} sa2,…)
将这一结论扩展到多个向量(或点)以及所有维度上,就是SVD所作的事情:
我们先从单个向量入手,利用矩阵来处理这看似复杂的问题。因此我们必须找到一种方法来表示使用矩阵进行向量分解的操作。
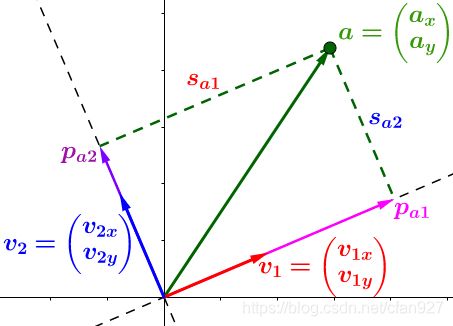
我们知道,一个向量在另一个向量上的投影长度可以用向量的点积来计算:
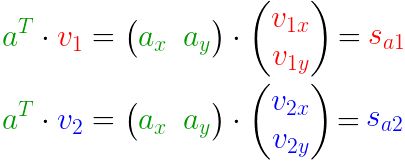
上式可以利用矩阵表示为:
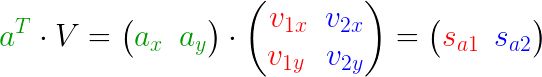
也可以将其扩展为多个点/向量:
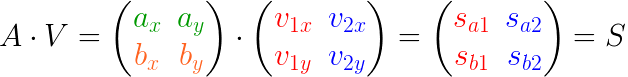
添加点 b b b后:
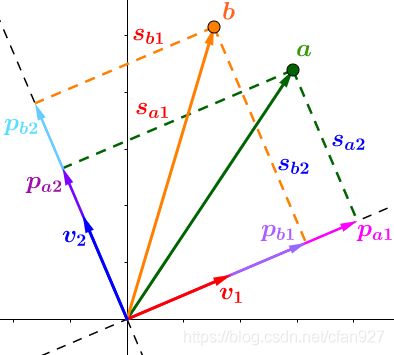
进一步,将上式扩展为任意多点和维度,有:
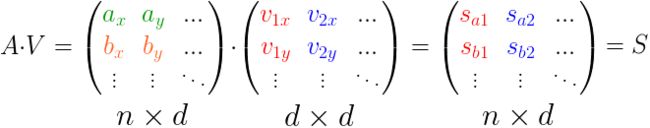
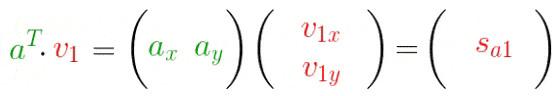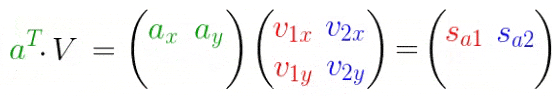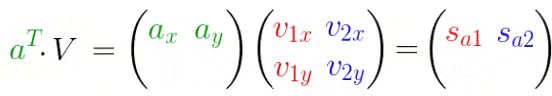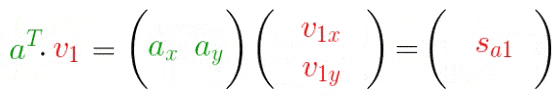

这等价于:
![]()
这就是SVD所说的(记住关键结论):
任何向量集(A)都可以用它们在正交轴(V)上的投影长度(S)来表示。
然而,传统的奇异值公式为:
![]()
实际上这也就等价于求解下式的来源:![]()
如果你仔细观察矩阵S,你会发现它包括:
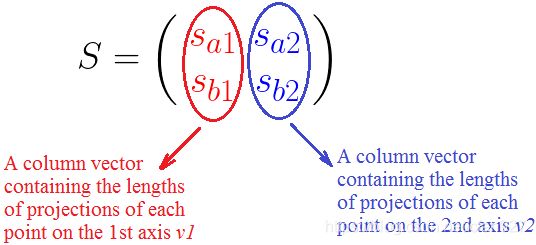
如果我们能将这些列向量归一化是最好的,也就是说使它们具有单位长度。这是通过将每个列向量除以它的大小来实现的,但是是以矩阵的形式。
但首先,我们来看一个简单的例子,看看这个“除法”是怎么做的:
假设我们要把M的第一列除以2。我们肯定要乘以另一个矩阵来保持等式:
很容易证明未知矩阵就是单位矩阵,第一个元素被除数2代替
第二列除以3现在变成了一个直接的问题把单位矩阵的第二元素换成3
很明显,这个操作可以推广到任何大小的矩阵。




我们现在想把上面的除法概念应用到矩阵 S S S上。为了归一化 S S S的列向量,我们用它们的大小来除它们
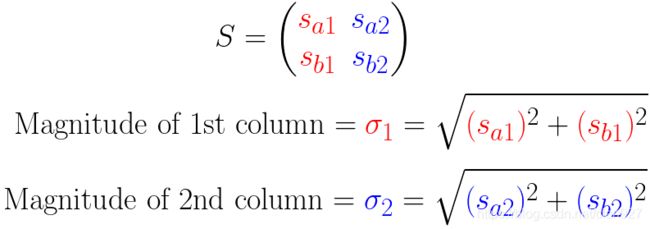
在上面的例子中,我们对M所做的就是:
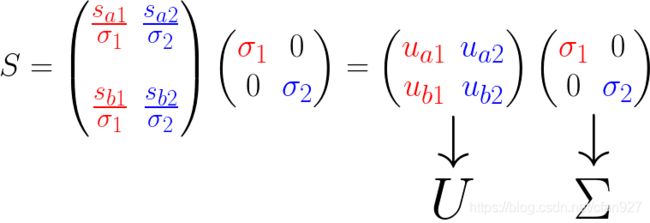
最终我们可以得到奇异值分解的公式:

当然,为了不分散对核心概念的注意力,省略了一些细节和严格的数学运算。
再来看 U U U和 Σ \Sigma Σ:
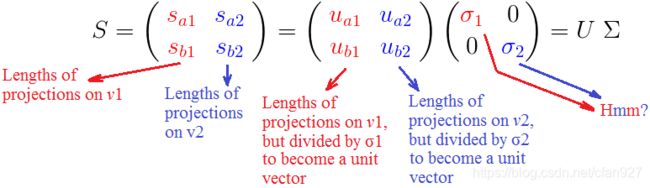
那 σ \sigma σ呢?为什么我们要用正常化的方式去寻找它们来增加自己的负担呢?
我们已经看到 σ i \sigma_i σi是所有的点,在第 i i i个单位向量 v i v_i vi上投影长度的平方和的平方根。那么这又说明了什么呢?
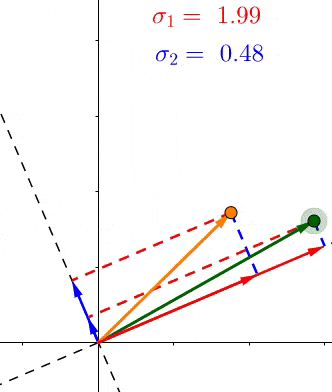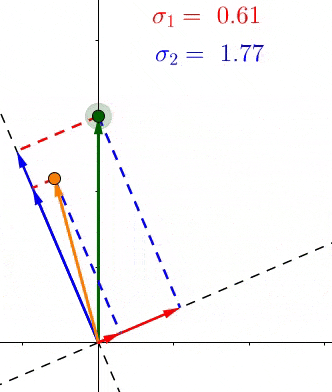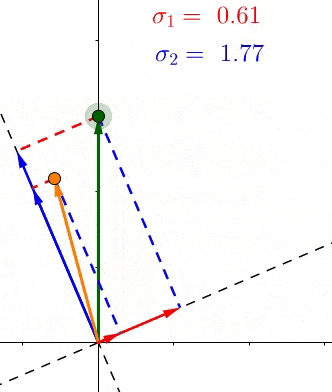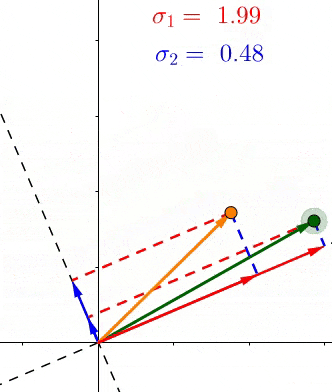
因为在它们的定义中, σ \sigma σ包含特定轴上投影长度的和,它们表示所有点到那个轴的距离。例如如果 σ 1 > σ 2 \sigma_1 > \sigma_2 σ1>σ2,那么大多数点更接近 v 1 v_1 v1,反之亦然。这在SVD的无数应用中有着巨大的实用价值。
4 SVD的应用
SVD在数据压缩等领域都有应用,具体参考[1][2][3][4]。
参考
[1] https://blog.csdn.net/sjyttkl/article/details/97563819
[2] https://www.zhihu.com/question/34143886/answer/196294308
[3] https://www.cnblogs.com/endlesscoding/p/10033527.html#335555762
[4] https://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
[5] You Don’t Know SVD (Singular Value Decomposition)