K8S使用手册
概念理解
Pod概念
①Pod是Kubernetes中一个抽象化概念,由一个或多个容器组合在一起得共享资源。这些资源包括:
1)共享存储,如 Volumes 卷
2)网络,唯一的集群IP地址
3)每个容器运行的信息,例如:容器镜像版本
②Pod理解
Pod模型是特定应用程序的“逻辑主机”,并且包含紧密耦合的不同应用容器。
Pod中的容器共享IP地址和端口。
组件
使用proxy监听端口
[root@tke-node1 ~]# kubectl proxy --port=8080 &
[root@tke-node1 ~]# curl http://localhost:8080/api/
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "cls-2kj2mgeq.ccs.tencent-cloud.com:60002"
}
]
}
组件关系
kubelet单独运行,因为要和宿主机直接打交道。然后通过静态pod启动三大组件。
各类IP
NodeIP:主机IP;
ClusterIP:ServcieIP即VIP;
PodIP:Pod的IP。
各类端口
NodePort:主机上监听的端口;
Port:service中clusterIP 对应的端口。
TargetPort:ClusterIP作为负载均衡, 后端目标实例(容器)的端口。指后端pod暴露的端口,就是pod中的containerPort。
如果既不指定port又不指定targetPort,那么port和targetPort都会继承pod中的containerPort。
如果指定了port而没有指定targetPort,那么targetPort会继承port值,所以此时必须指定targetPort值为pod中的containerPort,不能随便指定端口号,除非port值和pod中的containerPort相同(这种情况可以不指定targetPort)。
当type为ClusterIP时,流量经过的端口走向是:svc端口(port)----pod端口(targetPort)----容器端口(containerPort)
当type为NodePort时,流量经过的端口走向是:节点端口(NodePort)----svc端口(port)----pod端口(targetPort)----容器端口(containerPort)
EndPoint为podIP:targetPort:即每个Service的所有Endpoints
Service 的几种类型
ClusterIp:默认类型,每个Node分配一个集群内部的Ip,内部可以互相访问,外部无法访问集群内部。
NodePort:基于ClusterIp,另外在每个Node上开放一个端口,可以从所有的位置访问这个地址。
LoadBalance:基于NodePort,并且有云服务商在外部创建了一个负载均衡层,将流量导入到对应Port。要收费的。
ExternalName:将外部地址经过集群内部的再一次封装(实际上就是集群DNS服务器将CNAME解析到了外部地址上),实现了集群内部访问即可。
Ingress:通过独立的ingress对象来制定请求转发的规则,把请求路由到一个或多个service中。这样就把服务与请求规则解耦了。
资源状态
kubernetes:
node:
- TerminatedAllPods # Terminated All Pods (information)
- RegisteredNode # Node Registered (information)*
- RemovingNode # Removing Node (information)*
- DeletingNode # Deleting Node (information)*
- DeletingAllPods # Deleting All Pods (information)
- TerminatingEvictedPod # Terminating Evicted Pod (information)*
- NodeReady # Node Ready (information)*
- NodeNotReady # Node not Ready (information)*
- NodeSchedulable # Node is Schedulable (information)*
- NodeNotSchedulable # Node is not Schedulable (information)*
- CIDRNotAvailable # CIDR not Available (information)*
- CIDRAssignmentFailed # CIDR Assignment Failed (information)*
- Starting # Starting Kubelet (information)*
- KubeletSetupFailed # Kubelet Setup Failed (warning)*
- FailedMount # Volume Mount Failed (warning)*
- NodeSelectorMismatching # Node Selector Mismatch (warning)*
- InsufficientFreeCPU # Insufficient Free CPU (warning)*
- InsufficientFreeMemory # Insufficient Free Mem (warning)*
- OutOfDisk # Out of Disk (information)*
- HostNetworkNotSupported # Host Ntw not Supported (warning)*
- NilShaper # Undefined Shaper (warning)*
- Rebooted # Node Rebooted (warning)*
- NodeHasSufficientDisk # Node Has Sufficient Disk (information)*
- NodeOutOfDisk # Node Out of Disk Space (information)*
- InvalidDiskCapacity # Invalid Disk Capacity (warning)*
- FreeDiskSpaceFailed # Free Disk Space Failed (warning)*
pod:
- Pulling # Pulling Container Image (information)
- Pulled # Ctr Img Pulled (information)
- Failed # Ctr Img Pull/Create/Start Fail (warning)*
- InspectFailed # Ctr Img Inspect Failed (warning)*
- ErrImageNeverPull # Ctr Img NeverPull Policy Violate (warning)*
- BackOff # Back Off Ctr Start, Image Pull (warning)
- Created # Container Created (information)
- Started # Container Started (information)
- Killing # Killing Container (information)*
- Unhealthy # Container Unhealthy (warning)
- FailedSync # Pod Sync Failed (warning)
- FailedValidation # Failed Pod Config Validation (warning)
- OutOfDisk # Out of Disk (information)*
- HostPortConflict # Host/Port Conflict (warning)*
replicationController:
- SuccessfulCreate # Pod Created (information)*
- FailedCreate # Pod Create Failed (warning)*
- SuccessfulDelete # Pod Deleted (information)*
- FailedDelete # Pod Delete Failed (warning)*
服务质量
Kubernetes 创建 Pod 时就给它指定了下列⼀种 QoS 类:
-
Best-Effort ,最低优先级,第⼀个被kill。
-
Burstable ,第⼆个被kill。
-
Guaranteed ,最⾼优先级,最后kill。除⾮超过limit或者没有其他低优先级的Pod。
命令和参数
如果在使用K8S创建服务时,填写了容器得运行命令和参数,容器服务将会覆盖镜像构建时的默认命令(即Entrypoint和CMD),规则如下:
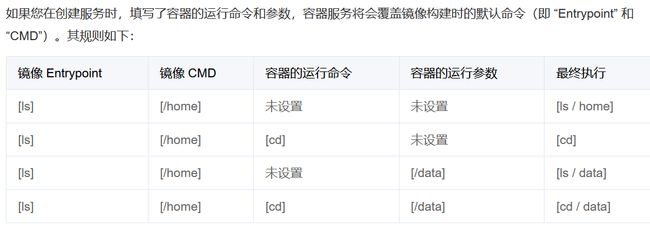
资源对象
PodPreset
这个需求实际上非常实用。比如,开发人员只需要提交一个基本的、非常简单的 Pod YAML,Kubernetes 就可以自动给对应的 Pod 对象加上其他必要的信息,比如 labels,annotations,volumes 等等。而这些信息,可以是运维人员事先定义好的。这么一来,开发人员编写 Pod YAML 的门槛,就被大大降低了
所以,这个叫作 PodPreset(Pod 预设置)的功能 已经出现在了 v1.11 版本的 Kubernetes 中。
举个例子,现在开发人员编写了如下一个 pod.yaml 文件:
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
role: frontend
spec:
containers:
- name: website
image: nginx
ports:
- containerPort: 80
作为 Kubernetes 的初学者,你肯定眼前一亮:这不就是我最擅长编写的、最简单的 Pod 嘛。没错,这个 YAML 文件里的字段,想必你现在闭着眼睛也能写出来。
可是,如果运维人员看到了这个 Pod,他一定会连连摇头:这种 Pod 在生产环境里根本不能用啊!
所以,这个时候,运维人员就可以定义一个 PodPreset 对象。在这个对象中,凡是他想在开发人员编写的 Pod 里追加的字段,都可以预先定义好。比如这个 preset.yaml:
apiVersion: settings.k8s.io/v1alpha1
kind: PodPreset
metadata:
name: allow-database
spec:
selector:
matchLabels:
role: frontend
env:
- name: DB_PORT
value: "6379"
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
在这个 PodPreset 的定义中,首先是一个 selector。这就意味着后面这些追加的定义,只会作用于 selector 所定义的、带有“role: frontend”标签的 Pod 对象,这就可以防止“误伤”。
然后,我们定义了一组 Pod 的 Spec 里的标准字段,以及对应的值。比如,env 里定义了 DB_PORT 这个环境变量,volumeMounts 定义了容器 Volume 的挂载目录,volumes 定义了一个 emptyDir 的 Volume。
接下来,我们假定运维人员先创建了这个 PodPreset,然后开发人员才创建 Pod:
$ kubectl create -f preset.yaml
$ kubectl create -f pod.yaml
这时,Pod 运行起来之后,我们查看一下这个 Pod 的 API 对象:
$ kubectl get pod website -o yaml
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
role: frontend
annotations:
podpreset.admission.kubernetes.io/podpreset-allow-database: "resource version"
spec:
containers:
- name: website
image: nginx
volumeMounts:
- mountPath: /cache
name: cache-volume
ports:
- containerPort: 80
env:
- name: DB_PORT
value: "6379"
volumes:
- name: cache-volume
emptyDir: {}
需要说明的是,PodPreset 里定义的内容,只会在 Pod API 对象被创建之前追加在这个对象本身上,而不会影响任何 Pod 的控制器的定义。
比如,我们现在提交的是一个 nginx-deployment,那么这个 Deployment 对象本身是永远不会被 PodPreset 改变的,被修改的只是这个 Deployment 创建出来的所有 Pod。这一点请务必区分清楚。
这里有一个问题:如果你定义了同时作用于一个 Pod 对象的多个 PodPreset,会发生什么呢?
实际上,Kubernetes 项目会帮你合并(Merge)这两个 PodPreset 要做的修改。而如果它们要做的修改有冲突的话,这些冲突字段就不会被修改。
K8S网络
腾讯云容器网络 vpc 对比 vxlan 性能测试
https://cloud.tencent.com/developer/article/1006675
调度
亲和度设置
高级调度nodeSelector、nodeaffinity;podaffinity、podantiaffinity
软亲和和硬亲和
preferredDuringSchedulingIgnoredDuringExecution,软亲和
通过在服务的deployment上配置反亲和性,让服务的pod尽量不要调度到同一个Node上,间接达到pod较为均匀分布在多个Node上的效果,也可以降低Node故障时对服务的影响。
requiredDuringSchedulingIgnoredDuringExecution,硬亲和
也可以配置成严格模式,要求每个Node上最多只能有一个Pod,但这样配置在启动的pod数多于Node数时会因可用Node不足起不来
容器健康检查和恢复机制
健康检查示例
在 Kubernetes 中,你可以为 Pod 里的容器定义一个健康检查“探针”(Probe)。这样,kubelet 就会根据这个 Probe 的返回值决定这个容器的状态,而不是直接以容器进行是否运行(来自 Docker 返回的信息)作为依据。这种机制,是生产环境中保证应用健康存活的重要手段。
另外Deployment、Statefulset的restartPolicy也必须为Always,保证pod异常退出,或者健康检查 livenessProbe失败后由kubelet重启容器。https://kubernetes.io/zh/docs/concepts/workloads/controllers/deployment
Job和CronJob是运行一次的pod,restartPolicy只能为OnFailure或Never,确保容器执行完成后不再重启。
这也正是 Deployment 只允许容器的 restartPolicy=Always 的主要原因:只有在容器能保证自己始终是 Running 状态的前提下,ReplicaSet 调整 Pod 的个数才有意义。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: test-liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
在这个 Pod 中,我们定义了一个有趣的容器。它在启动之后做的第一件事,就是在 /tmp 目录下创建了一个 healthy 文件,以此作为自己已经正常运行的标志。而 30 s 过后,它会把这个文件删除掉。
与此同时,我们定义了一个这样的 livenessProbe(健康检查)。它的类型是 exec,这意味着,它会在容器启动后,在容器里面执行一条我们指定的命令,比如:“cat /tmp/healthy”。这时,如果这个文件存在,这条命令的返回值就是 0,Pod 就会认为这个容器不仅已经启动,而且是健康的。这个健康检查,在容器启动 5 s 后开始执行(initialDelaySeconds: 5),每 5 s 执行一次(periodSeconds: 5)。
$ kubectl create -f test-liveness-exec.yaml
然后,查看这个 Pod 的状态:
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
test-liveness-exec 1/1 Running 0 10s
可以看到,由于已经通过了健康检查,这个 Pod 就进入了 Running 状态。而 30 s 之后,我们再查看一下 Pod 的 Events:
$ kubectl describe pod test-liveness-exec
你会发现,这个 Pod 在 Events 报告了一个异常:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
显然,这个健康检查探查到 /tmp/healthy 已经不存在了,所以它报告容器是不健康的。那么接下来会发生什么呢?我们不妨再次查看一下这个 Pod 的状态:
$ kubectl get pod test-liveness-exec
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
这时我们发现,Pod 并没有进入 Failed 状态,而是保持了 Running 状态。这是为什么呢?其实,如果你注意到 RESTARTS 字段从 0 到 1 的变化,就明白原因了:这个异常的容器已经被 Kubernetes 重启了。在这个过程中,Pod 保持 Running 状态不变。需要注意的是:Kubernetes 中并没有 Docker 的 Stop 语义。所以虽然是 Restart(重启),但实际却是重新创建了容器。这个功能就是 Kubernetes 里的 Pod 恢复机制,也叫 restartPolicy。它是 Pod 的 Spec 部分的一个标准字段(pod.spec.restartPolicy),默认值是 Always,即:任何时候这个容器发生了异常,它一定会被重新创建。
健康检查本质
值得一提的是,Kubernetes 的官方文档,把 restartPolicy 和 Pod 里容器的状态,以及 Pod 状态的对应关系,总结了非常复杂的一大堆情况。实际上,你根本不需要死记硬背这些对应关系,只要记住如下两个基本的设计原理即可:
1、只要 Pod 的 restartPolicy 指定的策略允许重启异常的容器(比如:Always),那么这个 Pod 就会保持 Running 状态,并进行容器重启。否则,Pod 就会进入 Failed 状态 。
2、对于包含多个容器的 Pod,只有它里面所有的容器都进入异常状态后,Pod 才会进入 Failed 状态。在此之前,Pod 都是 Running 状态。此时,Pod 的 READY 字段会显示正常容器的个数,比如:
所以,假如一个 Pod 里只有一个容器,然后这个容器异常退出了。那么,只有当 restartPolicy=Never 时,这个 Pod 才会进入 Failed 状态。而其他情况下,由于 Kubernetes 都可以重启这个容器,所以 Pod 的状态保持 Running 不变。
而如果这个 Pod 有多个容器,仅有一个容器异常退出,它就始终保持 Running 状态,哪怕即使 restartPolicy=Never。只有当所有容器也异常退出之后,这个 Pod 才会进入 Failed 状态。
基础操作
解决kubectl自动补全问题
[root@master ~]# yum install -y bash-completion [root@master ~]# locate bash_completion /usr/share/bash-completion/bash_completion [root@master ~]# source /usr/share/bash-completion/bash_completion
[root@master ~]# source <(kubectl completion bash)
kubectl常用命令
增:run、expose、create
删:delete
改:edit、apply、replace、patch、set
查:get、describe、explain
集群节点管理:cordon、uncordon、drain
部署管理:rollout、scale、autoscale
容器操作:logs、attach、exec、cp、port-forward
kubectl run busybox --image=busybox -it /bin/sh
attach只有在容器也有bash进程才能进入交互
exec在容器不是bash进程时也能进入交互
kubectl scale
kubectl scale --current-replicas=1 --replicas=3 deployment/nginx
kubectl autoscale
kubectl autoscale deployment nginx --min=4 --max=6
运行一个Nginx副本
kubectl run nginx --image='nginx:latest' --image-pull-policy='IfNotPresent' --replicas=1 --port=9000
kubectl attach
用于取得pod 中容器的实时信息,可以持续不断实时的取出消息。像tail -f /var/log/messages 动态查看日志的作用**
kubectl logs 是一次取出所有消息,像cat /etc/passwd
kubectl edit 修改服务端口
[root@master ~]# kubectl edit service nginx
service “nginx” edited
[root@master ~]# kubectl get service #改完端口立马生效
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 10.254.0.1 443/TCP 17h
nginx 10.254.108.59 80:31002/TCP 25m
lable标签操作
查看pod标签信息
[root@VM_8_17_centos ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
my-nginx 1/1 Running 0 75m env=test
my-nginx1 1/1 Running 0 35m env=pro,tier=front
my-nginx2 1/1 Running 0 43m env=test,tier=front
my-nginx3 1/1 Running 0 35m env=test
下⾯我们尝试过过滤front
[root@VM_8_17_centos ~]# kubectl get pod --show-labels -l tier=front
NAME READY STATUS RESTARTS AGE LABELS
my-nginx1 1/1 Running 0 52s env=test,tier=front
my-nginx2 1/1 Running 0 9m5s env=test,tier=front
我们把其中⼀个Pod作为更新为线上环境。
[root@VM_8_17_centos ~]# kubectl label pod my-nginx1 env=pro --overwrite
pod/my-nginx1 labeled
[root@VM_8_17_centos ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
my-nginx 1/1 Running 0 48m env=test
my-nginx1 1/1 Running 0 8m24s env=pro,tier=front
my-nginx2 1/1 Running 0 16m env=test,tier=front
my-nginx3 1/1 Running 0 8m23s env=test,tier=backend
导出yaml文件
kubectl get deploy,sts,svc,configmap,secret app-name -o yaml --export > default.yaml
通过json格式查看服务信息
[root@master ~]# kubectl get service hostnames -o json
污点
污点设置
1、查看污点
kubectl describe nodes nodename |grep Taints
2、设置污点
kubectl taint node node名 key=value:污点三个可选值
NoSchedule : 一定不被调度
PreferNoSchedule : 尽量不被调度
NoExecute : 不会调度,并且还会驱逐Node已有Pod
例如:kubectl taint node nodename key=value:NoSchedule
3、删除污点
kubectl taint nodes nodename key:NoSchedule-
4、添加配置文件yaml
spec:
spec:
tolerations: #容忍
- key: key #这个是设置污点的key
value: value #这个是设置污点的values
effect: NoSchedule #这个是污点类型
对于tolerations属性的写法:
其中的key、value、effect 与Node的Taint设置需保持一致, 还有以下几点说明:
1、如果operator的值是Exists,则value属性可省略。
2、如果operator的值是Equal,则表示其key与value之间的关系是equal(等于)。
3、如果不指定operator属性,则默认值为Equal。
另外,还有两个特殊值:
1、空的key 如果再配合Exists 就能匹配所有的key与value ,也是是能容忍所有node的所有Taints。
2、空的effect 匹配所有的effect。
滚动更新
控制字段
maxUnavailable: [0%, 100%] 向下取整,比如10个副本,5%的话==0.5个,但计算按照0个;
maxSurge: [0%, 100%] 向上取整,比如10个副本,5%的话==0.5个,但计算按照1个;
平滑发布建议配置
maxUnavailable == 0
maxSurge == 1
这是我们生产环境提供给用户的默认配置。即“一上一下,先上后下”最平滑原则:1个新版本pod ready(结合readiness)后,才销毁旧版本pod。****此配置适用场景是平滑更新、保证服务平稳,但也有缺点,就是“太慢”了。
快速发布建议配置
如果期望副本数是10,期望能有至少80%数量的副本能稳定工作,所以:maxUnavailable = 2,maxSurge = 2 (可自定义,建议与maxUnavailable保持一致)
发布示例
maxUnavailable = 1
maxSurge = 1
可以看到是先删除一个旧版本,待新版本创建并且running再删除一个旧版本。
汇总滚动更新命令
创建一个app:
kubectl create deployment nginx --image=nginx:1.11
创建service
kubectl expose deployment nginx --port=80 --type=NodePort
扩缩容:
kubectl scale deployment nginx --replicas=5
修改镜像,滚动更新:
kubectl set image deployment nginx nginx=nginx:1.10
或者
kubectl edit deployment/nginx
查看更新状态:
kubectl rollout status deployment nginx
终止升级
kubectl rollout pause deployment/nginx
继续升级
kubectl rollout resume deployment/nginx
回滚
kubectl rollout undo deployment/nginx
回滚到指定版本
kubectl rollout undo deployment/nginx --to-revision=2
查看滚动版本:
kubectl rollout history deployment nginx
查看信息:
kubectl describe deployment/nginx
Kubernetes 零宕机滚动更新
https://www.qikqiak.com/post/zero-downtime-rolling-update-k8s/
https://cloud.tencent.com/developer/article/1587653
集群信息
查看所有API接口
可通过 kubectl api-versions 和 kubectl api-resources 查询 Kubernetes API 支持的 API 版本以及资源对象。
查看命名空间
kubectl get --raw /api/v1/namespaces
Rancher
搭建高可用Rancher
https://www.jianshu.com/p/a628b36f330e?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
新增filebeat
复制一份模板配置
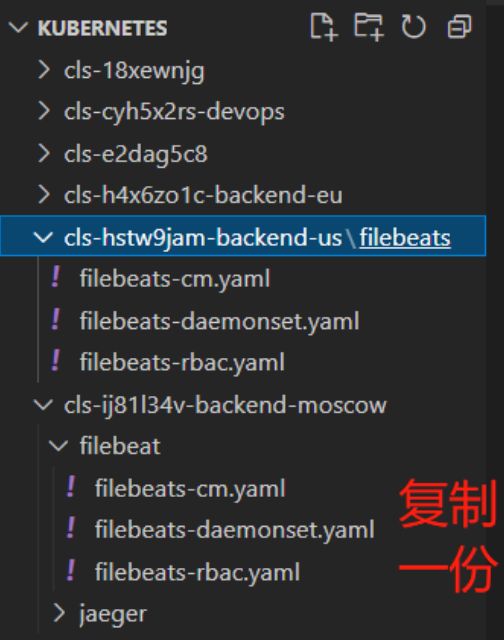
修改配置
修改coding中的filebeats-cm.yaml配置的kafka的IP地址
启动filebeat
kubectl create -f filebeats-cm.yaml
kubectl create -f filebeats-rbac.yaml
kubectl create -f filebeats-daemonset.yaml
问题处理
跨节点不能互通
要清除iptables规则,这个是最新遇到的坑,什么检查都对,但是ping就是不通,使用如下命令执行删除防火墙规则,注意不是关闭防火墙就万事大吉哦,我以前也这么想的,不清除防火墙规则关闭是没用的,因为Kubernetes依赖iptables所以是不会被关闭的。
执行以下命令清除iptables规则,只在node上操作即可(其实前面两个命令就已经实现了连通性)
[root@node2 ~]# iptables -P INPUT ACCEPT
[root@node2 ~]# iptables -P FORWARD ACCEPT #其实就这两句
[root@master ~]# cat /proc/sys/net/ipv4/ip_forward #其实就这两句
不能拷贝
通过kubectl cp拷贝Pod中的文件到本地
[root@master ~]# kubectl cp mysql-2261771434-03jct:/etc/hosts /tmp/hosts
error: unexpected EOF #意外的终止了
#排错方法
[root@master ~]# kubectl cp --help
# Requires that the 'tar' binary is present in your container #想要使用kubectl cp你的容器实例中必须有tar 库
# image. If 'tar' is not present, 'kubectl cp' will fail. #如果镜像中tar命令不存在,那么拷贝会失败
#安装mysql pod中的tar命令
[root@node2 ~]# docker exec -it 2f4b76876793 /bin/bash #node2中进入到MySQL容器
bash-4.2# yum -y install tar #安装好后就可以完成以上拷贝任务
[root@master ~]# kubectl cp mysql-2261771434-03jct:/etc/hosts /tmp/hosts
#注:拷贝是双向的,可以拷贝出来,也可以拷贝进去替换掉