np.savetxt()将代码中数据存到本地(复数or十进制or字符串)
python存储代码中数据到本地txt文件、读取本地txt中数据并转换为array类型
使用np.savetxt()存数据到本地,使用np.loadtxt()从本地文件读取。
其中np.savetxt()和np.loadtxt()函数可配置的参数如下:
numpy.savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='# ', encoding=None)
numpy.loadtxt(fname, dtype=<type 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0)
先说明将数据存到本地文件的函数numpy.savetxt()的使用说明,示例代码如下:
import numpy as np
x = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12]]
np.savetxt(r'test.txt', x)
参数都使用默认值,存数结果如下所示:

fmt参数:控制数据格式
可以看到,文件中的数据小数点后保留太多位,使得数据看起来很凌乱,可以使用格式控制参数‘fmt’进行控制,比如小数点后保留3位。
np.savetxt(r'test.txt', x, fmt='%.3e')
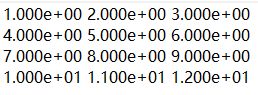
但数据后面还跟着‘e+00’字符,可将此字符串去掉,以浮点数存储,fmt=’%.3f’;也可以整数格式存储,fmt=’%d’。
np.savetxt(r'test.txt', x, fmt='%.3f') # 保留3位小数
np.savetxt(r'test.txt', x, fmt='%d') # 整数

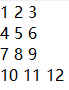
格式控制–数据对齐问题
可以看到上图中第4行的11和12与上一行的8和9发生错位,不够美观,通过设置数据长度进行调整。
np.savetxt(r'test.txt', x, fmt='%5d')

数据长度比较短,看的不太明显,换一个数据长度:
x = [[1, 2, 3],
[44, 55, 66],
[777, 888, 999],
[1110, 1111, 1112]]
np.savetxt(r'test.txt', x, fmt='%5d', delimiter='|') # delimiter='|',后面会提到用法

但是看起来数据还是没有对齐,此外空格不太好区分,所以使用0作为占位符,竖线作为分隔符。如果使用0作为占位符,可以看到此时数据已经对齐,只是如何使得文件中的数据看起来对齐,暂时还不清楚,哪位大佬知道可以评论一下。
np.savetxt(r'test.txt', x, fmt='%05d', delimiter='|')

如果直接使用3个数据格式控制符fmt=’%05d%05d%05d’,则分隔符竖线’|'无法显示。
np.savetxt(r'test.txt', x, fmt='%05d%05d%05d', delimiter='|')

delimiter参数:每列数据之间的分割符号,默认为空格
可以用任何字符或字符串进行分割,例如使用竖线 ‘|’ 分割,百分号 ‘%’ 分割,任意字符串‘abc’分割。
np.savetxt(r'test.txt', x, fmt='%d', delimiter='|')
np.savetxt(r'test.txt', x, fmt='%d', delimiter='%%')
np.savetxt(r'test.txt', x, fmt='%d', delimiter='abc')

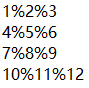

newline参数:每行数据之间的分割符,默认换行
随便使用一个字符串‘-|-’作为行分割符,其中列数据之间使用默认的空格作为分割符。
np.savetxt(r'test.txt', x, fmt='%d', newline='-|-')
![]()
header和footer参数:在文件头和文件尾增加的说明语句。
np.savetxt(r'test.txt', x, fmt='%d', header='this is begin of arrry data!', footer='this is end of arrry data!')

comments参数:注释时使用的字符或者字符串
注释符默认为python的注释符‘# ’,注意#号后面有个空格,可以参照上图,this与#号之间有个明显的空格。可以使用任何字符或者字符串作为分割符,使用双斜杠‘//’或者字符串‘abc ’作为注释符号,如下所示:
np.savetxt(r'test.txt', x, fmt='%d', header='this is begin of arrry data!', footer='this is end of arrry data!', comments='//')
np.savetxt(r'test.txt', x, fmt='%d', header='this is begin of arrry data!', footer='this is end of arrry data!', comments='abc ')


参考
numpy官网对savetxt()的描述