Highly Efficient Salient Object Detection with 100K Parameters论文解读
ECCV2020
Paper: http://mftp.mmcheng.net/Papers/20EccvSal100k.pdf
Code: https://github.com/MCG-NKU/SOD100K
主要创新点
- We propose a flexible convolutional module, namely gOctConv, to efficiently utilize both in-stage and cross-stages multi-scale features for SOD task, while reducing the representation redundancy by a novel dynamic weight decay scheme. 通用八度卷积模块----可以有效地利用阶段内和跨阶段的多尺度特征进行SOD任务,同时通过一种新颖的动态权重衰减方案来减少特征表示的冗余性。
- Utilizing gOctConv, we build an extremely light-weighted SOD model, namely CSNet, which achieves comparable performance with ∼ 0.2% parameters (100k) of SOTA large models on popular SOD benchmarks. 构造轻量级网络,参数量只有100K。
SOD任务需要为每个图像像素生成准确的预测分数,因此既需要大尺度的高层次特征表示来正确定位突出的物体,也需要精细的低层次表示来精确细化边界。构建超轻量级的SOD模型有两个主要的挑战:首先,当高层次特征的低频性满足了显著性特征图的高输出分辨率时,可能会出现严重的重冗余。其次,SOTA SOD模型通常依靠ImageNet预训练的主干网络架构来提取特征,而这本身就很耗费资源。
Generalized OctConv
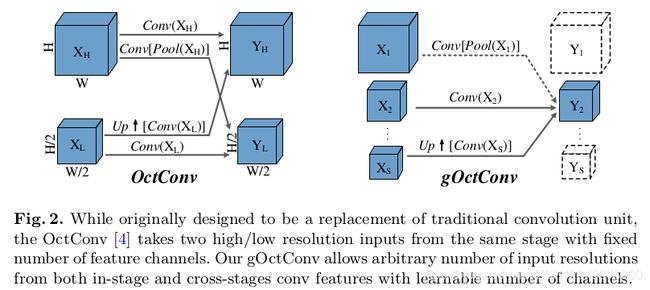
OctConv: (Paper: https://export.arxiv.org/pdf/1904.05049)
核心原理就是利用空间尺度化理论将图像高频低频部分分开,下采样低频部分,可以大大降低参数量,并且可以完美的嵌入到神经网络中。降低了低频信息的冗余。
(传入的data是分高频和低频数据的。OctCon是训练四个卷积核,分别为hh,hl,lh,ll)
高频分量,是指不经过高斯滤波的原始通道(或图像);
低频分量,是指经过t=2的高斯滤波得到的通道(或图像)------------冗余的
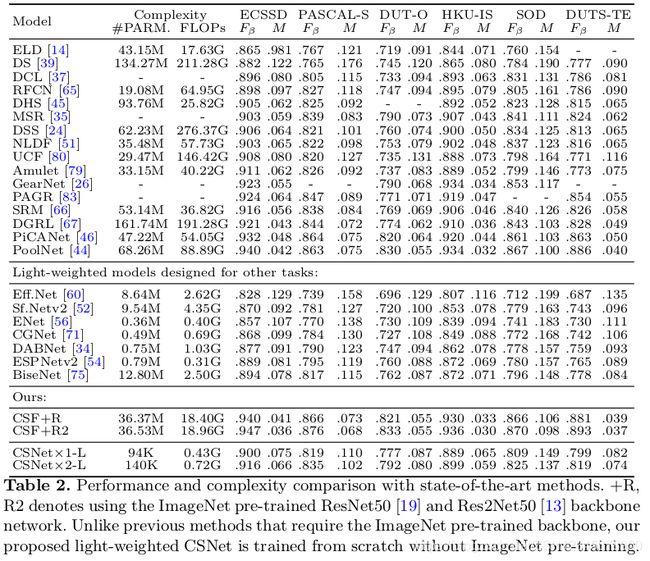
比较好的blog: https://www.cnblogs.com/RyanXing/p/10720182.html
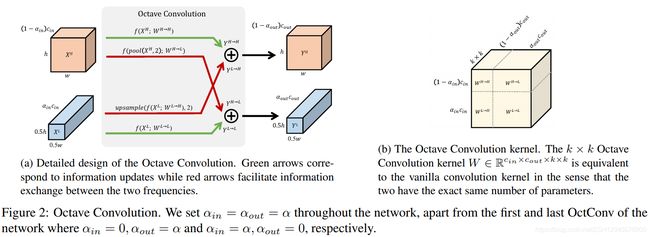
原来的OctConv:1)仅利用OctConv中的低和高分辨率两个尺度不足以完全减少SOD任务中的冗余问题,而SOD任务比分类任务需要更强大的多尺度表示能力。2)在OctConv中,每个scale的通道数是手动选择的,因为SOD任务需要的类别信息较少,因此需要为模型进行大量的调整。
gOctConv改进:1)支持任意输入和输出尺寸,多尺度表示; 2)内阶段和跨阶段的特征都可表示; 3)通过动态权重衰减和剪枝策略,可以学到不同尺度的通道信息;4)如果考虑大复杂度的灵活性,可以不用跨尺寸的特征交互。
Light-weighted Model
该轻量级网络由特征提取器和跨阶段融合部分组成,可以同时处理多个尺度的特征。特征提取器与提出的层级多尺度块(即ILBlock)堆叠在一起,并根据特征图的分辨率分为4个阶段,每个阶段分别具有3、4、6和4个ILBlock。由gOctConv组成的跨阶段融合部分处理来自特征提取器各阶段的特征,以获得高分辨率输出。
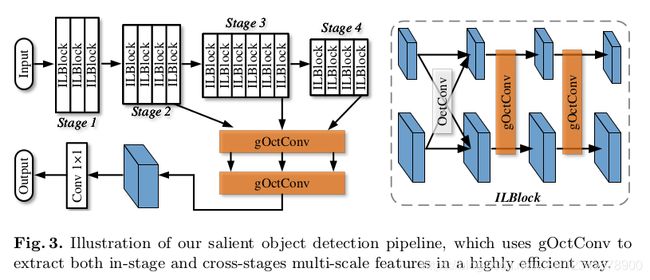
层级多尺度块(In-layer Multi-scale Block,ILBlock)-----增强了阶段性特征的多尺度表示,gOctConvs被用来引入ILBlock内的多尺度。原本的OctConv需要大约60%的FLOPs才能达到与标准卷积相似的性能,这对于我们设计一个高轻量级模型的目标来说是不够的。为了节省计算成本,在每一层中都没有必要使用不同尺度的交互特征。因此,本文方法应用gOctConv消除跨尺度操作,使每个输入通道对应于具有相同分辨率的输出通道。在每个尺度内利用深度运算来进一步节省计算成本。与原始的OctConv相比,gOctConv的这个实例只需要1/channel的FLOPs。ILBlock由一个原始的OctConv和两个3×3的gOctConv组成,如图3所示。原始的OctConv与两个尺度的特征进行交互,gOctConvs在每个尺度内提取特征。一个区块内的多尺度特征被单独处理,交替进行内交互。每一次卷积之后都要进行BatchNorm和PRelu。最初,随着分辨率的降低,将ILBlocks的通道大致翻倍,除了最后两个阶段的通道数相同。
跨层级融合(Cross-stages Fusion)为了保持高输出分辨率,常规方法在特征提取器的高层级上保持高特征分辨率,不可避免地增加了计算冗余。相反,本文的方法仅使用gOctConvs从特征提取器的各个阶段融合多尺度特征,并生成高分辨率输出。作为效率和性能之间的折衷,使用了来自最后三个阶段的特征。gOctConv中1×1卷积将具有与每个阶段的最后一个卷积不同尺度的特征作为输入,并进行跨阶段卷积以输出具有不同尺度的特征。为了在粒度级别上提取多尺度特征,特征的每个尺度都由一组具有不同扩展率的并行卷积处理。然后将特征发送到另一个gOctConv 1×1卷积以生成最高分辨率的特征。另一个标准1×1卷积输出了显著性图的预测结果,还获得了gOctConvs的可学习通道。
class PallMSBlock(nn.Module):
def __init__(self,in_channels, out_channels, alpha=[0.5,0.5], bias=False):
super(PallMSBlock, self).__init__()
self.std_conv = False
self.convs = nn.ModuleList()
for i in range(len(alpha)):
self.convs.append(MSBlock(int(round(in_channels*alpha[i])), int(round(out_channels*alpha[i]))))
self.outbranch = len(alpha)
def forward(self, xset):
if isinstance(xset,torch.Tensor):
xset = [xset,]
yset = []
for i in range(self.outbranch):
yset.append(self.convs[i](xset[i]))
return yset
class MSBlock(nn.Module):
def __init__(self, in_channels, out_channels, dilations = [1,2,4,8,16]):
super(MSBlock,self).__init__()
self.dilations = dilations
each_out_channels = out_channels//5
self.msconv = nn.ModuleList()
for i in range(len(dilations)):
if i != len(dilations)-1:
this_outc = each_out_channels
else:
this_outc = out_channels - each_out_channels*(len(dilations)-1)
self.msconv.append(nn.Conv2d(in_channels, this_outc,3, padding=dilations[i], dilation=dilations[i], bias=False))
self.bn = nn.GroupNorm(32, out_channels)
self.prelu = nn.PReLU(out_channels)
def forward(self, x):
outs = []
for i in range(len(self.dilations)):
outs.append(self.msconv[i](x))
out = torch.cat(outs, dim=1)
del outs
out = self.prelu(self.bn(out))
return out
class CSFNet(nn.Module):
def __init__(self, num_classes=1):
super(CSFNet, self).__init__()
self.base = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 26, scale = 4)
# self.base.load_state_dict(model_zoo.load_url(model_urls['res2net50_v1b_26w_4s']))
fuse_in_channel = 256+512+1024+2048
fuse_in_split = [1/15,2/15,4/15,8/15]
fuse_out_channel = 128+256+512+512
fuse_out_split = [1/11,2/11,4/11,4/11]
self.fuse = gOctaveCBR(fuse_in_channel, fuse_out_channel, kernel_size=(1,1), padding=0,
alpha_in = fuse_in_split, alpha_out = fuse_out_split, stride = 1)
self.ms = PallMSBlock(fuse_out_channel, fuse_out_channel, alpha = fuse_out_split)
self.fuse1x1 = gOctaveCBR(fuse_out_channel, fuse_out_channel, kernel_size=(1, 1), padding=0,
alpha_in = fuse_out_split, alpha_out = [1,], stride = 1)
self.cls_layer = nn.Conv2d(fuse_out_channel, num_classes, kernel_size=1)
def forward(self, x):
features = self.base(x)
fuse = self.fuse(features)
fuse = self.ms(fuse)
fuse = self.fuse1x1(fuse)
output = self.cls_layer(fuse[0])
output = F.interpolate(output, x.size()[2:], mode='bilinear', align_corners=False)
return output
def build_model():
return CSFNet()
def weights_init(m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.01)
if m.bias is not None:
m.bias.data.zero_()
Learnable channels with model compression
通过在训练过程中利用提出的动态权重衰减辅助剪枝过程,为gOctConv中的每个尺度获取可学习的通道数。 动态权重衰减可在引入稀疏性的同时保持通道之间的权重分布稳定,从而有助于剪枝消除冗余通道。
常用的正则化技巧权重衰减使CNN具有更好的泛化性能。通过权重衰减进行训练使得CNN中不重要的权重值接近于零。因此,权重衰减已被广泛用于剪枝中以引入稀疏性。权重衰减的常见实现方式是在损失函数中添加L2正则化:

多样化输出主要是由对权重的衰减项的不加区分的抑制造成的。因此,可以根据某些通道的特定特征来调整权重衰减。具体来说,在反向传播期间,衰减项会根据某些通道的特征动态变化。动态权重衰减的权重更新写为:
![]()
λ是动态权重衰减的权重, x i x_i xi表示由 w i w_i wi计算的特征,而 S ( x i ) S(x_i) S(xi)是特征的度量,根据任务可以具有多个定义。在本文中,目标是根据稳定通道之间的特征进行权重分配。因此,可以仅使用全局平均池(GAP)作为特定通道的指标:


def updateWeight(self, s=0.001):
for m in self.modules():
if isinstance(m, gOctaveCBR):
for n in list(m.modules()):
if isinstance(n, nn.BatchNorm2d):
n.weight.grad.data.add_(
s * torch.sign(n.weight.data)) # L1
# hook for dynamic weight decay #
def Oct_bn_hook(module, input, output):
all_weights = []
branches = len(output)
this_flop_weight = []
init_flop = module.baseflop * (module.expandflop**(branches - 1))
for k in range(branches):
this_flop_weight.append(init_flop)
init_flop /= module.expandflop
gap_id = 0
for name, m in module.named_modules():
# print(name)
if isinstance(m, nn.BatchNorm2d):
gap_vet = torch.nn.functional.adaptive_avg_pool2d(
output[gap_id].detach(), 1).squeeze().abs()
gap_id += 1
bn_id = int(name.split('.')[-1])
all_weights.append((this_flop_weight[bn_id] * gap_vet *
torch.pow(m.weight, 2)).sum()) #l2 reg.
# print(all_weights)
module.all_flops += 0.5 * sum(all_weights)
实验
Details: CSNet仍可以达到与基于预训练主干的大模型相当的性能。最初将学习率设置为1e-4,然后在200个epoch和250个epoch时衰减10倍。本文仅使用了随机翻转和裁剪的数据增强。gOctConvs之后的BatchNorms权重衰减,作者建议使用动态的权重衰减替代,默认权重为3,而其他权重的权重衰减默认设置为5e-3。