自动求导autograd.grad的学习 包含torch和tensorflow对jacobi的支持
可以确定的是:
1.pytorch采用动态计算图机制,默认的tensor requires_grad这个参数为False,只有自己设为True,到时才会计算这个tensor的梯度。
2."现在的版本中已经不需要用Variable来实现自动求导."这句话不对,至少我在kaggle里测试,如果不用Variable还是会出错:
现在确实不需要Variable了。
3.如果输出为张量,需要指定grad_outputs,并且强制要求该参数和被微分的对象size一致,见下面torch源码的截图:
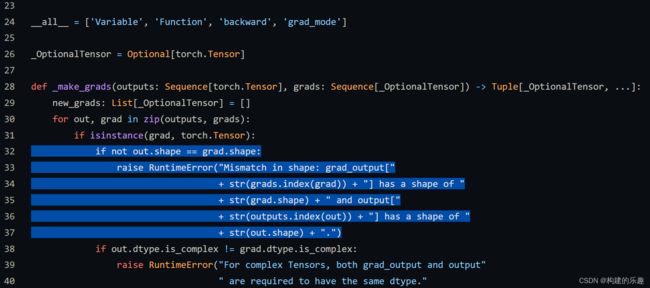
grad_outputs (sequence of Tensor): The "vector" in the Jacobian-vector product.
Usually gradients w.r.t. each output. None values can be specified for scalar
Tensors or ones that don't require grad. If a None value would be acceptable
for all grad_tensors, then this argument is optional. Default: None.
不报错的代码(使用Variable):
from torch.autograd import Variable
a = Variable(torch.ones((10,3,10,10),dtype=torch.float32),requires_grad = True)
a.require_grad=True
b=torch.mul(a,a)+a
# print(b)
b.require_grad=True
gg=grad(b,a,grad_outputs=torch.ones(b.size()))[0]
print(gg)
# grad = compute_grad_element_wise(b,a)
报错的代码(不使用Variable)
from torch.autograd import Variable
# a = Variable(torch.ones((10,3,10,10),dtype=torch.float32),requires_grad = True)
a = torch.ones((10,3,10,10),dtype=torch.float32)
a.require_grad=True
b=torch.mul(a,a)+a
# print(b)
b.require_grad=True
gg=grad(b,a,grad_outputs=torch.ones(b.size()))[0]
print(gg)
# grad = compute_grad_element_wise(b,a)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_35/877673165.py in
6 # print(b)
7 b.require_grad=True
----> 8 gg=grad(b,a,grad_outputs=torch.ones(b.size()))[0]
9 print(gg)
10 # grad = compute_grad_element_wise(b,a)
/opt/conda/lib/python3.7/site-packages/torch/autograd/__init__.py in grad(outputs, inputs, grad_outputs, retain_graph, create_graph, only_inputs, allow_unused)
226 return Variable._execution_engine.run_backward(
227 outputs, grad_outputs_, retain_graph, create_graph,
--> 228 inputs, allow_unused, accumulate_grad=False)
229
230
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
有一点,这样用是会报错的。
m=output_tensor[:,[0],:,:]
n=input_tensor[:,[0],:,:]
grad_tensor=grad(m,n,grad_outputs=torch.ones(m.size()))[0]
也就是说,切了片以后的m和n是不在计算图内的。
此外,如果在requires_grad=True之后采用in-place操作(看下面参考文献),也会报错:
RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation.
报错的代码
a = Variable(torch.ones((10,3,10,10),dtype=torch.float32),requires_grad = True)
# a = torch.ones((10,3,10,10),dtype=torch.float32)
a.require_grad=True
b=torch.mul(a,a)+a
# print(b)
a[:,0,:,:]+=b[:,0,:,:]
b.require_grad=True
以下代码段报错:One of the differentiated Tensors appears to not have been used in the graph
import torch
from torch.autograd import Variable
a =torch.ones((10,3,10,10),dtype=torch.float32)
# a = torch.ones((10,3,10,10),dtype=torch.float32)
a.requires_grad=True
b=torch.mul(a,a)+a
# print(b)
# a[:,0,:,:]+=b[:,0,:,:]
d=torch.zeros((1))
# d[:,:,:,:]=a[:,1:,:,:]
# m=b[0,0,0,1]
d[0]=b[0,0,0,1]
# print('...........')
# print(d.requires_grad)
# m
# t=a[0,0,0,0]
# d[:,:,:,:]=d
# a.permute(0,2,3,1)
mask = torch.zeros_like(a)
# mask[0,0,0,1]=1
# mask.requires_grad=True
# gg=grad(b,a,grad_outputs=torch.ones(b.size()))[0]
# print(gg)
# mygrad=mygrad*mask
# print(mygrad)
# print(mask)
# print(mask.requires_grad)
# print(mygrad.requires_grad)
a=a.flatten()
d=d.flatten()
mygrad = compute_grad_element_wise(d,a)
mygrad
# mygrad_grad=torch.zeros_like(mygrad)
# mygrad_grad[0,0,0,0]=mygrad[0,0,0,0]
# # compute_grad_element_wise(mygrad_grad[1],mygrad)
# compute_grad_element_wise(mygrad[1],mygrad)
原因:错在对a进行flatten操作,而不在对d。对a flatten相当于沿着a这个叶子创建了另一计算图的分支,而且也将其命名为a,而这个分支并未与d有梯度上的上下游关系。因此会报错。解决办法:不要将其命名为a.需要有一个清晰的认识,那就是d只能对它的上游求导,并且这个上游必须是“原原本本的”上游,即不能有诸如flatten操作等等,否则就会视为一个从这个上游衍生出来的新的跟d不相关的分支,导致出现以上的错误。
有关什么是in-place见参考文献。
就我看来,torch计算梯度还是不方便。比如上面讲到,不能关于计算图中Tensor的切片直接求梯度(例如:grad(a[0],b[0],…),这样就会报错——注意,grad(a[0],b,…)是没有问题的,即输出允许切片,但输入不允许),计算完每次梯度后还需手动清零,否则会梯度累加,也不能对待计算梯度的tensor进行in-place操作。。。很多亟待改进之处。
最麻烦的地方是,torch.autograd.grad虽然允许输出为张量并关于输入的张量求梯度,但它做了一些限制:
具体就是,它要求必须通过grad_outputs(见本文开头)指定输出张量的分量对输入张量的梯度的权重v(v的形状和y相同),并利用这个权重对每个输出分量关于输入计算出的梯度张量累加,最后得到的梯度张量和关于求导的张量的形状是一致的。
具体讲,y张量对x张量求导(grad(y,x,…)),最后的梯度张量是y中每个元素对x张量求导形成的梯度张量按照v加权的和,形状和x张量的形状是一样的。
这件事在深度学习引擎上很容易理解,你把y想成是网络的损失,实际人家这个引擎就是方便你计算y的每个分量对参数张量x的梯度之加权和(不同种类的损失加权嘛,重要性不一样,比如正则化项和回归损失项),从而方便后续的神经网络优化。
但是这个出于方便的特性放在PINN上就太不方便了。
事实上,我想做PINN,其中需要用张量的某部分分量对另一张量的另外的部分分量求导数,这就非常麻烦。
就在今天找到了一个更好的办法,采用这个文档里提到的办法即可。这个文档还是非常好的。
2022-06-16
今天发现torch grad出现新的参数 is_grad_batched,这个允许不加权单独计算
tensorflow对jacobi的支持
https://tensorflow.google.cn/guide/advanced_autodiff#jacobians
似乎比torch要好一些,torch目前的api是将函数作为参数输入求jacobi,但tensorflow直接用输出作为参数求jacobi
感谢花时间阅读,望批评指正!
参考文献
https://github.com/zhongpenggeo/Blogs/blob/73b46d1e6072dff3600541b5cccd29a5de2a43cf/CS/DL/PyTorch/Autograd%E2%80%94%E2%80%94%E5%A4%9A%E5%85%83%E4%B8%8E%E9%AB%98%E9%98%B6.md
https://zhuanlan.zhihu.com/p/51385110
https://zhuanlan.zhihu.com/p/474947864
自动求导的原理讲的不错
什么是in-place操作
in-place操作使用它的禁忌
讲解Jacobi-vector与pytorch自动微分技术的一篇好文章
讲解torch引擎层次上怎么实现自动微分的一个好的技术系列
pytorch autograd官方文档