Self-Supervised Learning
目录
What is self-supervised learning?
What makes a "good" representation?
Contrastive Learning: SimCLR
导入包和权重
Data Augmentation
Base Encoder and Projection Head
SimCLR: Contrastive Loss
simclr_loss_naive
vectorized version
Implement the train function
Finetune a Linear Layer for Classification
Classifier
Baseline: Without Self-Supervised Learning
With Self-Supervised Learning
Comparison
What is self-supervised learning?
Modern day machine learning requires lots of labeled data. But often times it's challenging and/or expensive to obtain large amounts of human-labeled data. Is there a way we could ask machines to automatically learn a model which can generate good visual representations without a labeled dataset? Yes, enter self-supervised learning!
Self-supervised learning (SSL) allows models to automatically learn a "good" representation space using the data in a given dataset without the need for their labels. Specifically, if our dataset were a bunch of images, then self-supervised learning allows a model to learn and generate a "good" representation vector for images.
The reason SSL methods have seen a surge in popularity is because the learnt model continues to perform well on other datasets as well i.e. new datasets on which the model was not trained on!
What makes a "good" representation?
A "good" representation vector needs to capture the important features of the image as it relates to the rest of the dataset. This means that images in the dataset representing semantically similar entities should have similar representation vectors, and different images in the dataset should have different representation vectors. For example, two images of an apple should have similar representation vectors, while an image of an apple and an image of a banana should have different representation vectors.
Contrastive Learning: SimCLR
SimCLR introduces a new architecture which uses contrastive learning to learn good visual representations. Contrastive learning aims to learn similar representations for similar images and different representations for different images. As we will see in this notebook, this simple idea allows us to train a surprisingly good model without using any labels.
Specifically, for each image in the dataset, SimCLR generates two differently augmented views of that image, called a positive pair. Then, the model is encouraged to generate similar representation vectors for this pair of images. See below for an illustration of the architecture (Figure 2 from the paper).

训练步骤:
- Given an image x, SimCLR uses two different data augmentation schemes t and t' to generate the positive pair of images ̃ and ̃.
- is a basic encoder net that extracts representation vectors from the augmented data samples, which yields ℎ and ℎ, respectively.
- A small neural network projection head maps the representation vectors to the space where the contrastive loss is applied. The goal of the contrastive loss is to maximize agreement between the final vectors =(ℎ) and =(ℎ).
After training is completed, we throw away the projection head and only use and the representation ℎ to perform downstream tasks, such as classification. You will get a chance to finetune a layer on top of a trained SimCLR model for a classification task and compare its performance with a baseline model (without self-supervised learning).
导入包和权重
Pretrained weights (trained for ~18 hours on CIFAR-10) for the SimCLR model. Download pretrained model weights to be used later.
# URL=http://downloads.cs.stanford.edu/downloads/cs231n/pretrained_simclr_model.pth
# FILE=pretrained_model/pretrained_simclr_model.pth
# Setup cell.
%pip install thop
import torch
import os
import importlib
import pandas as pd
import numpy as np
import torch.optim as optim
import torch.nn as nn
import random
from torchvision import transforms
from thop import profile, clever_format
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
import matplotlib.pyplot as plt
%matplotlib inline
%load_ext autoreload
%autoreload 2
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)Data Augmentation
def compute_train_transform(seed=123456):
"""
This function returns a composition of data augmentations to a single training image.
"""
random.seed(seed)
torch.random.manual_seed(seed)
# Transformation that applies color jitter with brightness=0.4, contrast=0.4, saturation=0.4, and hue=0.1
color_jitter = transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)
train_transform = transforms.Compose([
# Step 1: Randomly resize and crop to 32x32.
transforms.RandomResizedCrop(32),
# Step 2: Horizontally flip the image with probability 0.5
transforms.RandomHorizontalFlip(0.5),
# Step 3: With a probability of 0.8, apply color jitter (you can use "color_jitter" defined above.
transforms.RandomApply([color_jitter], 0.8),
# Step 4: With a probability of 0.2, convert the image to grayscale
transforms.RandomGrayscale(0.2),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
return train_transform
测试一下
from PIL import Image
import torchvision
from torchvision.datasets import CIFAR10
def rel_error(x,y):
return np.max(np.abs(x - y) / (np.maximum(1e-8, np.abs(x) + np.abs(y))))
def test_data_augmentation(correct_output=None):
train_transform = compute_train_transform(seed=2147483647)
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=2, shuffle=False, num_workers=2)
dataiter = iter(trainloader)
images, labels = dataiter.next()
img = torchvision.utils.make_grid(images)
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
output = images
print("Maximum error in data augmentation: %g"%rel_error( output.numpy(), correct_output.numpy()))
# Should be less than 1e-07.
test_data_augmentation(answers['data_augmentation'])Base Encoder and Projection Head
The base encoder extracts representation vectors for the augmented samples. The SimCLR paper found that using deeper and wider models improved performance and thus chose ResNet to use as the base encoder. The output of the base encoder are the representation vectors ℎ=(̃) and ℎ=(̃).
The projection head is a small neural network that maps the representation vectors ℎ and ℎ to the space where the contrastive loss is applied. The paper found that using a nonlinear projection head improved the representation quality of the layer before it. Specifically, they used a MLP with one hidden layer as the projection head .
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models.resnet import resnet50
class Model(nn.Module):
def __init__(self, feature_dim=128):
super(Model, self).__init__()
self.f = []
for name, module in resnet50().named_children():
if name == 'conv1':
module = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
if not isinstance(module, nn.Linear) and not isinstance(module, nn.MaxPool2d):
self.f.append(module)
# encoder
self.f = nn.Sequential(*self.f)
# projection head
self.g = nn.Sequential(nn.Linear(2048, 512, bias=False),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Linear(512, feature_dim, bias=True))
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.g(feature)
return F.normalize(feature, dim=-1), F.normalize(out, dim=-1)
SimCLR: Contrastive Loss
The contrastive loss is computed based on the outputs =(ℎ) and =(ℎ). A mini-batch of training images yields a total of 2 data-augmented examples. The loss is the normalized temperature-scaled cross entropy loss and aims to maximize the agreement of and relative to all other augmented examples in the batch:

where ∈{0,1} is an indicator function that outputs 1 if ≠ and 0 otherwise. is a temperature parameter that determines how fast the exponentials increase.
sim(,)=⋅ / |||||||| is the (normalized) dot product between vectors and . The higher the similarity between and , the larger the dot product is, and the larger the numerator becomes. The denominator normalizes the value by summing across and all other augmented examples in the batch. The range of the normalized value is (0,1), where a high score close to 1 corresponds to a high similarity between the positive pair (,) and low similarity between and other augmented examples in the batch. The negative log then maps the range (0,1) to the loss values (inf,0).
The total loss is computed across all positive pairs (,) in the batch. Let =[1,2,...,2] include all the augmented examples in the batch, where 1... are outputs of the left branch, and +1...2 are outputs of the right branch. Thus, the positive pairs are (,+) for ∀∈[1,].
Then, the total loss is:

simclr_loss_naive
def simclr_loss_naive(out_left, out_right, tau):
"""Compute the contrastive loss L over a batch (naive loop version).
Input:
- out_left: NxD tensor; output of the projection head g(), left branch in SimCLR model.
- out_right: NxD tensor; output of the projection head g(), right branch in SimCLR model.
(out_left[k], out_right[k]) form a positive pair for all k=0...N-1.
- tau: scalar value, temperature parameter that determines how fast the exponential increases.
Returns:
- A scalar value; the total loss across all positive pairs in the batch.
"""
N = out_left.shape[0] # total number of training examples
# Concatenate out_left and out_right into a 2*N x D tensor.
out = torch.cat([out_left, out_right], dim=0) # [2*N, D]
total_loss = 0
for k in range(N): # loop through each positive pair (k, k+N)
z_k, z_k_N = out[k], out[k+N]
sum_k, sum_k_N = 0, 0
for i in range(2*N):
sum_k += torch.exp(sim(z_k, out[i])/tau)
sum_k_N += torch.exp(sim(z_k_N, out[i])/tau)
sum_k -= torch.exp(sim(z_k, z_k)/tau)
sum_k_N -= torch.exp(sim(z_k_N, z_k_N)/tau)
loss_k = -torch.log(torch.exp(sim(z_k, z_k_N) / tau) / sum_k)
loss_k_N = -torch.log(torch.exp(sim(z_k_N, z_k) / tau) / sum_k_N)
total_loss += loss_k + loss_k_N
# In the end, we need to divide the total loss by 2N, the number of samples in the batch.
total_loss = total_loss / (2*N)
return total_loss
def sim(z_i, z_j):
"""Normalized dot product between two vectors.
Inputs:
- z_i: 1xD tensor.
- z_j: 1xD tensor.
Returns:
- A scalar value that is the normalized dot product between z_i and z_j.
"""
norm_dot_product = np.dot(z_i, z_j) / (torch.linalg.norm(z_i) * torch.linalg.norm(z_j))
return norm_dot_productvectorized version
def sim_positive_pairs(out_left, out_right):
"""Normalized dot product between positive pairs.
Inputs:
- out_left: NxD tensor; output of the projection head g(), left branch in SimCLR model.
- out_right: NxD tensor; output of the projection head g(), right branch in SimCLR model.
Each row is a z-vector for an augmented sample in the batch.
The same row in out_left and out_right form a positive pair.
Returns:
- A Nx1 tensor; each row k is the normalized dot product between out_left[k] and out_right[k].
"""
pos_pairs = None
left_norm = out_left / torch.linalg.norm(out_left, dim=1, keepdim=True)
right_norm = out_right / torch.linalg.norm(out_right, dim=1, keepdim=True)
mul = torch.mm(left_norm, right_norm.T)
# 取mu1的对角线,因为只有对角线才是left_norm和right_norm对应行相乘
pos_pairs = torch.diag(mul).view(-1, 1)
return pos_pairs
def compute_sim_matrix(out):
"""Compute a 2N x 2N matrix of normalized dot products between all pairs of augmented examples in a batch.
Inputs:
- out: 2N x D tensor; each row is the z-vector (output of projection head) of a single augmented example.
There are a total of 2N augmented examples in the batch.
Returns:
- sim_matrix: 2N x 2N tensor; each element i, j in the matrix is the normalized dot product between out[i] and out[j].
"""
out_norm = out / torch.linalg.norm(out, dim=1, keepdim=True)
sim_matrix = torch.mm(out_norm, out_norm.T)
return sim_matrix
def simclr_loss_vectorized(out_left, out_right, tau, device='cuda'):
"""Compute the contrastive loss L over a batch (vectorized version).
Inputs and output are the same as in simclr_loss_naive.
"""
N = out_left.shape[0]
# Concatenate out_left and out_right into a 2*N x D tensor.
out = torch.cat([out_left, out_right], dim=0) # [2N, D]
# Compute similarity matrix between all pairs of augmented examples in the batch.
sim_matrix = compute_sim_matrix(out) # [2N, 2N]
# Step 1: Use sim_matrix to compute the denominator value for all augmented samples.
exponential = torch.exp(sim_matrix / tau) # shape: 2N x 2N
# This binary mask zeros out terms where k=i.
mask = (torch.ones_like(exponential, device=device) - torch.eye(2 * N, device=device)).to(device).bool()
# 没有GPU就使用下面这一行
# mask = (torch.ones_like(exponential) - torch.eye(2 * N)).bool()
# We apply the binary mask.
exponential = exponential.masked_select(mask).view(2 * N, -1) # [2N, 2N-1]
# Compute the denominator values for all augmented samples. 分母
denom = torch.sum(exponential, axis = 1) # shape: 2N
# Step 2: Compute similarity between positive pairs.
# You can do this in two ways:
sim_pairs = sim_positive_pairs(out_left, out_right) # N x 1
sim_pairs = torch.cat([sim_pairs, sim_pairs], dim=0) # 2N x 1
# Step 3: Compute the numerator value for all augmented samples.
numerator = torch.exp(sim_pairs / tau) # 2N x 1
# Step 4: Now that you have the numerator and denominator for all augmented samples, compute the total loss.
loss = torch.mean(-torch.log(numerator / denom)) # numerator / denom: 2N x 2N
return lossImplement the train function
Run the following cells to load in the pretrained weights and continue to train a little bit more. This part will take ~10 minutes and will output to pretrained_model/trained_simclr_model.pth.
NOTE: Don't worry about logs such as '[WARN] Cannot find rule for ...'. These are related to another module used in the notebook. You can verify the integrity of your code changes through our provided prompts and comments.
训练函数
# utils.py
from tqdm import tqdm
def train(model, data_loader, optimizer, epoch, epochs, batch_size=32, temperature=0.5, device='cuda'):
"""Trains the model defined in ./model.py with one epoch.
Inputs:
- model: Model class object as defined in ./model.py.
- data_loader: torch.utils.data.DataLoader object; loads in training data. You can assume the loaded data has been augmented.
- optimizer: torch.optim.Optimizer object; applies an optimizer to training.
- epoch: integer; current epoch number.
- epochs: integer; total number of epochs.
- batch_size: Number of training samples per batch.
- temperature: float; temperature (tau) parameter used in simclr_loss_vectorized.
- device: the device name to define torch tensors.
Returns:
- The average loss.
"""
model.train()
total_loss, total_num, train_bar = 0.0, 0, tqdm(data_loader)
for data_pair in train_bar:
x_i, x_j, target = data_pair
x_i, x_j = x_i.to(device), x_j.to(device)
_, out_left = model.forward(x_i)
_, out_right = model.forward(x_j)
loss = simclr_loss_vectorized(out_left, out_right, temperature)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_num += batch_size
total_loss += loss.item() * batch_size
train_bar.set_description('Train Epoch: [{}/{}] Loss: {:.4f}'.format(epoch, epochs, total_loss / total_num))
return total_loss / total_num加载数据和数据处理函数
class CIFAR10Pair(CIFAR10):
"""CIFAR10 Dataset.
"""
def __getitem__(self, index):
img, target = self.data[index], self.targets[index]
img = Image.fromarray(img)
x_i = None
x_j = None
if self.transform is not None:
x_i = self.transform(img)
x_j = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return x_i, x_j, target
def compute_test_transform():
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
return test_transform
[点击并拖拽以移动]
训练
# Do not modify this cell.
feature_dim = 128
temperature = 0.5
k = 200
batch_size = 64
epochs = 1
temperature = 0.5
percentage = 0.5
pretrained_path = './pretrained_model/pretrained_simclr_model.pth'
# Prepare the data.
train_transform = compute_train_transform()
train_data = CIFAR10Pair(root='data', train=True, transform=train_transform, download=True)
train_data = torch.utils.data.Subset(train_data, list(np.arange(int(len(train_data)*percentage))))
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True, drop_last=True)
test_transform = compute_test_transform()
memory_data = CIFAR10Pair(root='data', train=True, transform=test_transform, download=True)
memory_loader = DataLoader(memory_data, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=True)
test_data = CIFAR10Pair(root='data', train=False, transform=test_transform, download=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=True)
# Set up the model and optimizer config.
model = Model(feature_dim)
model.load_state_dict(torch.load(pretrained_path, map_location='cpu'), strict=False)
model = model.to(device)
flops, params = profile(model, inputs=(torch.randn(1, 3, 32, 32).to(device),))
flops, params = clever_format([flops, params])
print('# Model Params: {} FLOPs: {}'.format(params, flops))
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-6)
c = len(memory_data.classes)
# Training loop.
results = {'train_loss': [], 'test_acc@1': [], 'test_acc@5': []} #<< -- output
if not os.path.exists('results'):
os.mkdir('results')
best_acc = 0.0
for epoch in range(1, epochs + 1):
train_loss = train(model, train_loader, optimizer, epoch, epochs, batch_size=batch_size, temperature=temperature, device=device)
results['train_loss'].append(train_loss)
test_acc_1, test_acc_5 = test(model, memory_loader, test_loader, epoch, epochs, c, k=k, temperature=temperature, device=device)
results['test_acc@1'].append(test_acc_1)
results['test_acc@5'].append(test_acc_5)
# Save statistics.
if test_acc_1 > best_acc:
best_acc = test_acc_1
torch.save(model.state_dict(), './pretrained_model/trained_simclr_model.pth')Finetune a Linear Layer for Classification
将SimCLR模型的projection head部分去除,末尾附上线性层,完成简单的分类任务 。All layers before the linear layer are frozen, and only the weights in the final linear layer are trained.
Classifier
定义了一个Classifier模型,以resnet50为蓝底,在末尾附加了一层线性层作分类用
class Classifier(nn.Module):
def __init__(self, num_class):
super(Classifier, self).__init__()
# Encoder.
self.f = Model().f # resnet50
# Classifier.
self.fc = nn.Linear(2048, num_class, bias=True)
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.fc(feature)
return out用于训练的函数
def train_val(model, data_loader, train_optimizer, epoch, epochs, device='cuda'):
is_train = train_optimizer is not None
model.train() if is_train else model.eval()
loss_criterion = torch.nn.CrossEntropyLoss()
total_loss, total_correct_1, total_correct_5, total_num, data_bar = 0.0, 0.0, 0.0, 0, tqdm(data_loader)
with (torch.enable_grad() if is_train else torch.no_grad()):
for data, target in data_bar:
data, target = data.to(device), target.to(device)
out = model(data)
loss = loss_criterion(out, target)
if is_train:
train_optimizer.zero_grad()
loss.backward()
train_optimizer.step()
total_num += data.size(0)
total_loss += loss.item() * data.size(0)
prediction = torch.argsort(out, dim=-1, descending=True)
total_correct_1 += torch.sum((prediction[:, 0:1] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
total_correct_5 += torch.sum((prediction[:, 0:5] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
data_bar.set_description('{} Epoch: [{}/{}] Loss: {:.4f} ACC@1: {:.2f}% ACC@5: {:.2f}%'
.format('Train' if is_train else 'Test', epoch, epochs, total_loss / total_num,
total_correct_1 / total_num * 100, total_correct_5 / total_num * 100))
return total_loss / total_num, total_correct_1 / total_num * 100, total_correct_5 / total_num * 100Baseline: Without Self-Supervised Learning
特征提取使用的是resnet50的权重
# Do not modify this cell.
feature_dim = 128
temperature = 0.5
k = 200
batch_size = 128
epochs = 10
percentage = 0.1
train_transform = compute_train_transform()
train_data = CIFAR10(root='data', train=True, transform=train_transform, download=True)
trainset = torch.utils.data.Subset(train_data, list(np.arange(int(len(train_data)*percentage))))
train_loader = DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=16, pin_memory=True)
test_transform = compute_test_transform()
test_data = CIFAR10(root='data', train=False, transform=test_transform, download=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=16, pin_memory=True)
model = Classifier(num_class=len(train_data.classes)).to(device)
for param in model.f.parameters():
param.requires_grad = False # 不训练
flops, params = profile(model, inputs=(torch.randn(1, 3, 32, 32).to(device),))
flops, params = clever_format([flops, params])
print('# Model Params: {} FLOPs: {}'.format(params, flops))
optimizer = optim.Adam(model.fc.parameters(), lr=1e-3, weight_decay=1e-6)
no_pretrain_results = {'train_loss': [], 'train_acc@1': [], 'train_acc@5': [],
'test_loss': [], 'test_acc@1': [], 'test_acc@5': []}
best_acc = 0.0
for epoch in range(1, epochs + 1):
train_loss, train_acc_1, train_acc_5 = train_val(model, train_loader, optimizer, epoch, epochs, device='cuda')
no_pretrain_results['train_loss'].append(train_loss)
no_pretrain_results['train_acc@1'].append(train_acc_1)
no_pretrain_results['train_acc@5'].append(train_acc_5)
test_loss, test_acc_1, test_acc_5 = train_val(model, test_loader, None, epoch, epochs)
no_pretrain_results['test_loss'].append(test_loss)
no_pretrain_results['test_acc@1'].append(test_acc_1)
no_pretrain_results['test_acc@5'].append(test_acc_5)
if test_acc_1 > best_acc:
best_acc = test_acc_1
# Print the best test accuracy.
print('Best top-1 accuracy without self-supervised learning: ', best_acc)With Self-Supervised Learning
特征提取使用的权重是训练好的SimCLR模型的权重
feature_dim = 128
temperature = 0.5
k = 200
batch_size = 128
epochs = 10
percentage = 0.1
pretrained_path = './pretrained_model/trained_simclr_model.pth'
train_transform = compute_train_transform()
train_data = CIFAR10(root='data', train=True, transform=train_transform, download=True)
trainset = torch.utils.data.Subset(train_data, list(np.arange(int(len(train_data)*percentage))))
train_loader = DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=16, pin_memory=True)
test_transform = compute_test_transform()
test_data = CIFAR10(root='data', train=False, transform=test_transform, download=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=16, pin_memory=True)
model = Classifier(num_class=len(train_data.classes))
model.load_state_dict(torch.load(pretrained_path, map_location='cpu'), strict=False)
model = model.to(device)
for param in model.f.parameters():
param.requires_grad = False
flops, params = profile(model, inputs=(torch.randn(1, 3, 32, 32).to(device),))
flops, params = clever_format([flops, params])
print('# Model Params: {} FLOPs: {}'.format(params, flops))
optimizer = optim.Adam(model.fc.parameters(), lr=1e-3, weight_decay=1e-6)
pretrain_results = {'train_loss': [], 'train_acc@1': [], 'train_acc@5': [],
'test_loss': [], 'test_acc@1': [], 'test_acc@5': []}
best_acc = 0.0
for epoch in range(1, epochs + 1):
train_loss, train_acc_1, train_acc_5 = train_val(model, train_loader, optimizer, epoch, epochs)
pretrain_results['train_loss'].append(train_loss)
pretrain_results['train_acc@1'].append(train_acc_1)
pretrain_results['train_acc@5'].append(train_acc_5)
test_loss, test_acc_1, test_acc_5 = train_val(model, test_loader, None, epoch, epochs)
pretrain_results['test_loss'].append(test_loss)
pretrain_results['test_acc@1'].append(test_acc_1)
pretrain_results['test_acc@5'].append(test_acc_5)
if test_acc_1 > best_acc:
best_acc = test_acc_1
# Print the best test accuracy. You should see a best top-1 accuracy of >=70%.
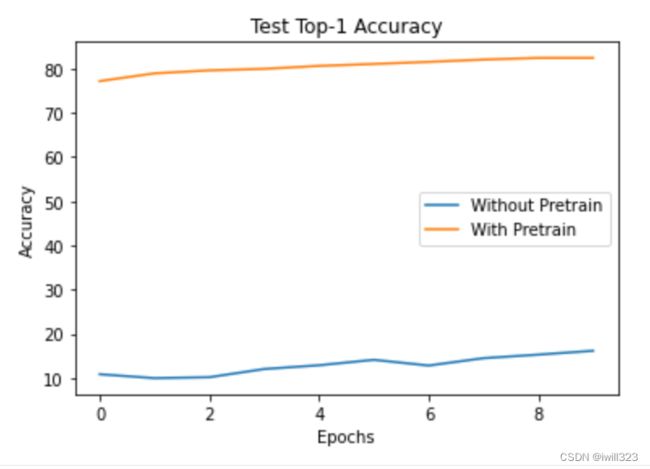
print('Best top-1 accuracy with self-supervised learning: ', best_acc)Comparison
You will get to see for yourself the power of self-supervised learning and how the learned representation vectors improve downstream task performance.
plt.plot(no_pretrain_results['test_acc@1'], label="Without Pretrain")
plt.plot(pretrain_results['test_acc@1'], label="With Pretrain")
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.title('Test Top-1 Accuracy')
plt.legend()
plt.show()