算力理解MIPS/DMIPS/MFLOPS/TOPS
参考:各种芯片简述以及算力解释
不要太较真自动驾驶算力(TOPS)
文章目录
- 一、CPU计算性能指标
-
- 1. MIPS
- 2. DMIPS(干石MIPS)
- 3. FLOPS/MFLOPS/GFLOPS/TFLOPS/PFLOPS/EFLOPS
- 二、算力
- 三、跑分
-
- 1. CoreMark跑分如何得来?
- 2. CoreMark测试
一、CPU计算性能指标
现在随着计算机使用了多级流水线结构,取指、译码、执行等并行方式,单纯使用频率确定性能不太合理,所以采用计算性能来测定CPU性能比较合理,主要有MIPS,DMIPS和FLOPS三个主要概念。
1. MIPS
MIPS(Million Instructions Per Second):字面理解为百万条指令/秒,即每秒执行百万级指令数。这是衡量CPU速度的一个指标。像是一个Intel 80386 电脑可以每秒处理3百万到5百万机器语言指令,即我们可以说80386是3到5MIPS的CPU。MIPS只是衡量CPU性能的指标。
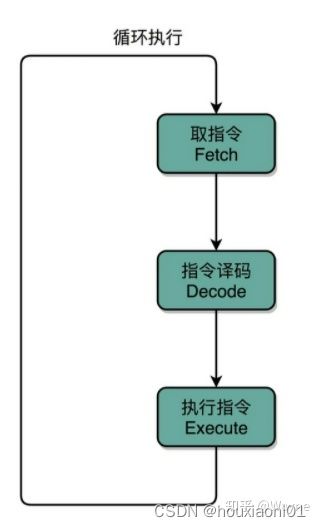
CPU执行指令
程序编译和运行过程中,代码会经过编译器转化成机器可以理解的指令。CPU每个指令周期分为取指令、指令译码、指令执行三个过程,只有在指令执行时才真正有效,在取指令和指令译码时,CPU时间是白白浪费的,而同样的运算在不同架构不同指令集需要的指令数也不一样。
除了 Instruction Cycle 这个指令周期,在 CPU 里面我们还会提到另外两个常见的 Cycle。一个叫 Machine Cycle,机器周期或者 CPU 周期。CPU 内部的操作速度很快,但是访问内存的速度却要慢很多。每一条指令都需要从内存里面加载而来,所以我们一般把从内存里面读取一条指令的最短时间,称为 CPU 周期。
还有一个是Clock Cycle,也就是时钟周期以及我们机器的主频。一个 CPU 周期,通常会由几个时钟周期累积起来。一个 CPU 周期的时间,就是这几个 Clock Cycle 的总和。
对于一个指令周期来说,我们取出一条指令,然后执行它,至少需要两个 CPU 周期。取出指令至少需要一个 CPU 周期,执行至少也需要一个 CPU 周期,复杂的指令则需要更多的 CPU 周期。
从上图可以看出,时钟周期是固定的,但是每个指令执行用时不同,所以需要提高CPU执行效率。
当前提升CPU性能的方法有:流水线技术、流水线冒险/预测、超标量Superscalar、超长指令字设计VLIW、单指令多数据流SIMD等技术(将来慢慢介绍)。尤其是SIMD 技术,是一种“指令级并行”的加速方案,或者说是一种“数据并行”的加速方案。在处理向量计算的情况下,同一个向量的不同维度之间的计算是相互独立的。而CPU 里的寄存器,又能放得下多条数据。于是,我们可以一次性取出多条数据,交给 CPU 并行计算。

但是,因为各个架构的CPU指令集各不相同,所以作为一家厂商的前后代产品对比也许还行,不同厂商之间的对比就比较难看出端倪了。所以有了DMIPS。
2. DMIPS(干石MIPS)
就是赫(chou)赫(ming)有(zhao)名(zhu)的Dhrystone MIPS。Dhrystone是测量处理器运算能力的最常见基准程序之一,常用于处理器的 整型运算性能 的测量。Dhrystone是一种整数运算测试程序。
Dhrystone的解释如下:
A short synthetic benchmark program by Reinhold Weicker [email protected], [email protected], intended to be representative of system (integer) programming. It is available in ADA, Pascal and C.The current version is Dhrystone 2.1. The author says, “Relying on MIPS V1.1 (the result of V1.1) numbers can be hazardous to your professional health.”
其实这是出自Dhrystone Benchmark。你们不是说各家CPU性能没法比较吗,那我搞一个统一的小程序,在你们各家的CPU上都跑一遍,看看每秒能跑多少次,然后做个运算(除以1757),谁家数字高谁家CPU就牛逼哄哄横眉冷对仰天大笑不就行了。
看上去是很美的设想,但是是有问题的:
- 说是测试CPU性能,但其实测试的时候还是无法脱离系统的,比如OS/Compiler/Library等等。如果测试的时候采用了针对干石优化过的Compiler和Library,那自然分就更高了。(简单来说就是好作弊)
- 只能测试1级缓存。无法反应L2,L3的真实情况。
虽然问题多多,毕竟大家现在也没有什么更好的测(zuo)试(bi)办法,而且DMIPS确实也比较知名,所以也就这么一直留用下来了。
ARM处理器比较 Cortex-A 系列
| Core | Architecture | bits | I-Cache | D-Cache | DMIPS/MHz |
|---|---|---|---|---|---|
| ARM11 | v7-A | 32 | 4-64K | 4-64K | 1.25 |
| Cortex-A5 | ARMv7-A | 32 | 4-64K | 4-64K | 1.57 |
| Cortex-A7 | ARMv7-A | 32 | 8-64K | 8-64K | 1.9 |
| Cortex-A8 | ARMv7-A | 32 | 16-32K | 16-32K | 2.0 |
| Cortex-A9 | ARMv7-A | 32 | 16-64K | 16-64K | 2.5 |
| Cortex-A12 | ARMv7-A | 32 | - | - | 3.5 |
| Cortex-A15 | ARMv7-A | 32 | 32K | 32K | 3.4 |
| Cortex-A17 | ARMv7-A | 32 | 32-64K | 32K | 3.2 |
| Cortex-A32 | ARMv8-A | 32 | 8-64K | 8-64K | 2.3 |
| Cortex-A35 | ARMv8-A | 32/64 | 8-64K | 8-64K | 2.5 |
| Cortex-A53 | ARMv8-A | 32/64 | 8-64K | 8-64K | 2.3 |
| Cortex-A55 | ARMv8.2-A | 32/64 | 64K | 64K | 2.7 |
| Cortex-A57 | ARMv8-A | 32/64 | 48K | 32K | 4.1 |
| Cortex-A72 | ARMv8-A | 32/64 | 48K | 32K | 4.7 |
| Cortex-A73 | ARMv8-A | 32/64 | 64K | 32-64k | 4.8 |
| Cortex-A75 | ARMv8.2-A | 32/64 | 64K | 64k | 5.2 |
| Cortex-A76 | ARMv8.2-A | 32/64 | 64K | 64k | - |
ARM处理器比较 Cortex-M 系列
| Core | Architecture | bits | DMIPS/MHz |
|---|---|---|---|
| Cortex-M0 | ARMv6M | 32 | 0.9~0.99 |
| Cortex-M3 | ARMv6M | 32 | 1.25~1.5 |
| Cortex-M4 | ARMv6M | 32 | 1.25~1.52 |
| Cortex-M7 | ARMv7-M | 32 | 2.14/2.55/3.23 |
MIPS/MHz 表示 CPU 在多少MHz的运行速度下可以执行多少个MIPS,如10MIPS/MHz,表示如果CPU运行在1MHz的频率下,每秒可执行一千万条指令,如果CPU运行在5MHz的频率下,每秒可执行五千万条指令。 MIPS/MHz可以很好的反映CPU的运行速度。
所以1.25DMips/MHz就表示1秒每MHZ的速度能执行1.25M个Dhrystone指令。
超标量处理器: 是指在一颗处理器内核中实现了指令级并行的一类并行运算。在这里就是 DMIPS/MHz 大于 1 的处理器,即做到了每个CPU时钟 可以执行 一条以上的 指令。
比如 ARM Cortex-A53 架构为 2.3DMIPS/MHz,那么可以计算出:
双核 A53 架构,主频为 1.6GHz 的 CPU,DMIPS 为:2 * 1600MHz * 2.3 DMIPS/MHz = 7360 DMIPS;
四核 A53 架构,主频为 1.6GHz 的 CPU,DMIPS为:4 * 1600MHz * 2.3 DMIPS/MHz = 14720 DMIPS;
我们来算下 NXP i.mx8 QuadMax ,ARM(2*A72+4*A53) ,4 核 A53 架构,主频为 1.2 GHz 的 CPU,DMIPS 为:4 * 1200 MHz * 2.3 DMIPS/MHz = 11040DMIPS;2 核 A72 架构,主频为 1.6 GHz 的 CPU,DMIPS 为:2 * 1600MHz * 4.7 DMIPS/MHz = 15040 DMIPS;最终 IMX8Q 的 CPU 计算性能 15040+11040=26080,所以是 26K DMIPS。
3. FLOPS/MFLOPS/GFLOPS/TFLOPS/PFLOPS/EFLOPS
上面的干石(Dhrystone)测试的是整数运算性能,而与之相对的还有 湿石(Whetstone),用来测试浮点运算性能。这个单位就是FLOPS。一般也用来指CPU算力。
FLOPS:每秒浮点运算次数(Floating Point Operations Per Second,FLOPS),又称为每秒峰值速度。
浮点运算在科研领域大量使用,现在的CPU除了支持整数运算,一般还支持浮点运算,有专门的浮点运算单元(FPU),FLOPS测量的就是处理器的浮点运算能力,实际上就是FPU的执行速度。而最常用来测量FLOPS的基准程式(benchmark)之一,就是Linpack。
FLOPS的计算公式如下:
浮点运算能力 = 处理器核数 * 每周期浮点运算次数 * 处理器主频
除了FLOPS,还有MFLOPS、GFLOPS、TFLOPS、PFLOPS、EFLOPS等单位,它们之间的换算关系如下。
- MFLOPS:megaFLOPS,每秒10^6次浮点运算,相当于每秒一百万次浮点运算
- GFLOPS:gigaFLOPS,每秒10^9次浮点运算,相当于每秒十亿次浮点运算
- TFLOPS:teraFLOPS,每秒10^12次浮点运算,相当于每秒一万亿次浮点运算
- PFLOPS:petaFLOPS,每秒10^15次浮点运算,相当于每秒一千万亿次浮点运算
- EFLOPS:exaFLOPS,每秒10^18次浮点运算,相当于每秒一百亿亿次浮点运算
1TFlops=1024GFlops,即1T=1024G。
二、算力
芯片算力是描述处理器进行运算,对数据进行操作的能力的指标。字面上理解,芯片算力越大,每秒能够进行的运算次数就越多,执行计算任务就越快。
算力的基本单位有:
- TOPS:Tera/Trillion Operations Per Second,1TOPS代表处理器每秒钟可进行一万亿次(10^12)操作,是
指GPU的乘积累加矩阵处理器的运算能力。 - GOPS:Giga Operations Per Second,1GOPS代表处理器每秒钟可进行十亿次(10^9)操作。
- MOPS:Million Operation Per Second,1MOPS代表处理器每秒钟可进行一百万次(10^6)操作。
TOPS同GOPS与MOPS可以换算,都代表每秒钟能处理的次数,单位不同而已。
这里给出一些神经网络所需要的算力:
Alexnet网络处理224x224的图像,需要1.4GOPS
resnet-152处理224x224的图像,需要22.6GOPS
但是,需要强调的是芯片算力是与运算精度紧密相关的,抛开运算精度去谈芯片的算力是毫无意义的。
芯片的运算精度有int8,int16等,对于大部分神经网络任务int8已经满足要求。

在某些情况下,还使用 TOPS/W 来作为评价处理器运算能力的一个性能指标,TOPS/W 用于度量在1W功耗的情况下,处理器能进行多少万亿次操作。
注意:
TOPS说的只是GPU算力。TOPS只说明每秒万亿次操作,要结合了数据类型精度(INT8,FP16等)才能与FLOPS转换。
首先算力和你使用的计算芯片有关系,如果你的算法大部分是标量计算,那这个值没有意义,当下我们所说的TOPS高算力实际都只是GPU的乘积累加矩阵运算算力。普遍意义上,CPU对应标量计算,GPU对应矢量或者说向量计算。我们可以将标量视为零阶张量,矢量视为一阶张量,那么矩阵就是二阶张量。
目前TOPS的物理计算单位是积累加运算(英语:Multiply Accumulate, MAC)是在微处理器中的特殊运算。实现此运算操作的硬件电路单元,被称为“乘数累加器”。这种运算的操作,是将乘法的乘积结果b*c和累加器a的值相加,再存入累加器a的操作:
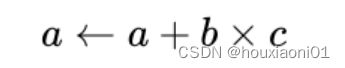
三、跑分
在嵌入式处理器领域最为知名和常见测试CPU性能的就是:Dhrystone 和 CoreMark。
-
CoreMark是用来衡量嵌入式系统中中心处理单元(CPU,或叫做微控制器MCU)性能的标准。
-
DMIPS:Dhrystone Million Instructions executed Per Second。用来计算同一秒内系统的处理能力,它的单位以百万来计算,也就是(MIPS)。主要用于测整数计算能力。
1. CoreMark跑分如何得来?
CoreMark是用来衡量CPU性能的标准。该标准于2009年由EEMBC组织的Shay Gla-On提出,并且试图将其发展成为工业标准,从而代替陈旧的Dhrystone标准。
与Dhrystone一样,CoreMark小巧,便携,易于理解,免费,并且显示单个数字基准分数。与Dhrystone不同,CoreMark具有特定的运行和报告规则,旨在避免Dhrystone的问题。
CoreMark跑分是通过运行C语言代码得出来的分数。主要包含如下的运算法则:列举(寻找并排序),数学矩阵操作(普通矩阵运算)和状态机(用来确定输入流中是否包含有效数字),最后还包括CRC(循环冗余校验)。
也就是说CoreMark是使用一套用C语言编辑的测试代码,我们通过运行这套代码就能测试你MCU的性能。
2. CoreMark测试
CPU性能测试——CoreMark篇
痞子衡嵌入式:微控制器CPU性能测试基准(EEMBC-CoreMark)
GD32移植CoreMark实现性能测评
Dhrystone howto
示例:全志D1平台 CoreMark 跑分测试
PC端编译 coremark.exe 可执行文件,编译参数如下:
/home/houxiaoni/WorkSpace/Allwinner/tina-d1-h/prebuilt/gcc/linux-x86/riscv/toolchain-thead-glibc/riscv64-glibc-gcc-thead_20200702/bin/riscv64-unknown-linux-gnu-gcc -O2 -Iriscv64 -Iposix -I. -DFLAGS_STR=\""-O2 -DPERFORMANCE_RUN=1 -lrt"\" -DITERATIONS=0 -DPERFORMANCE_RUN=1 core_list_join.c core_main.c core_matrix.c core_state.c core_util.c posix-rv/core_portme.c -o ./coremark.exe -lrt
小机端执行结果:

可以看到,D1 在 13.747 秒内完成了 40000 次迭代,因此跑分结果为 40000/13.747 = 2909.725758 CoreMark,单位主频的分数为 2909.725758 CoreMark/1008MHz ≈ 2.8866 CoreMark/MHz。
参考《全志D1(玄铁C906)运行coremark》