TransE算法原理与案例
文章目录
- TransE
-
- 知识图谱基础
- 知识表示
- 算法描述
- 代码分析
- 数据
TransE
知识图谱基础
三元组(h,r,t)
知识表示
即将实体和关系向量化,embedding
算法描述
思想:一个正确的三元组的embedding会满足:h+r=t
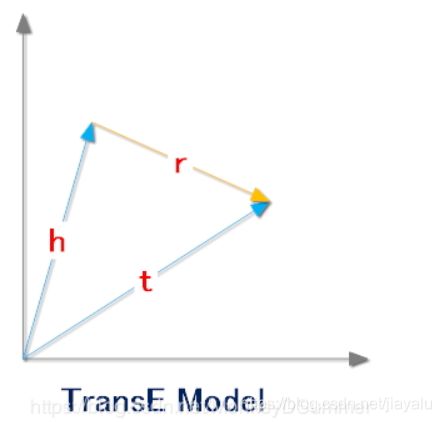
定义距离d表示向量之间的距离,一般取L1或者L2,期望正确的三元组的距离越小越好,而错误的三元组的距离越大越好。为此给出目标函数为:


梯度求解:

代码分析
- 定义类:
参数:
目标函数的常数——margin
学习率——learningRate
向量维度——dim
实体列表——entityList(读取文本文件,实体+id)
关系列表——relationList(读取文本文件,关系 + id)
三元关系列表——tripleList(读取文本文件,实体 + 实体 + 关系)
损失值——loss
距离公式——L1
- 向量初始化
规定初始化维度和取值范围(TransE算法原理中的取值范围)
涉及的函数:
init:随机生成值
norm:归一化
- 训练向量
getSample——随机选取部分三元关系,Sbatch
getCorruptedTriplet(sbatch)——随机替换三元组的实体,h、t中任意一个被替换,但不同时替换。
update——更新
L2更新向量的推导过程:

python 函数
uniform(a, b)#随机生成a,b之间的数,左闭右开。
求向量的模,var = linalg.norm(list)
"""
@version: 3.7
@author: jiayalu
@file: trainTransE.py
@time: 22/08/2019 10:56
@description: 用于对知识图谱中的实体、关系基于TransE算法训练获取向量
数据:三元关系
实体id和关系id
结果为:两个文本文件,即entityVector.txt和relationVector.txt 实体 [array向量]
"""
from random import uniform, sample
from numpy import *
from copy import deepcopy
class TransE:
def __init__(self, entityList, relationList, tripleList, margin = 1, learingRate = 0.00001, dim = 10, L1 = True):
self.margin = margin
self.learingRate = learingRate
self.dim = dim#向量维度
self.entityList = entityList#一开始,entityList是entity的list;初始化后,变为字典,key是entity,values是其向量(使用narray)。
self.relationList = relationList#理由同上
self.tripleList = tripleList#理由同上
self.loss = 0
self.L1 = L1
def initialize(self):
'''
初始化向量
'''
entityVectorList = {}
relationVectorList = {}
for entity in self.entityList:
n = 0
entityVector = []
while n < self.dim:
ram = init(self.dim)#初始化的范围
entityVector.append(ram)
n += 1
entityVector = norm(entityVector)#归一化
entityVectorList[entity] = entityVector
print("entityVector初始化完成,数量是%d"%len(entityVectorList))
for relation in self. relationList:
n = 0
relationVector = []
while n < self.dim:
ram = init(self.dim)#初始化的范围
relationVector.append(ram)
n += 1
relationVector = norm(relationVector)#归一化
relationVectorList[relation] = relationVector
print("relationVectorList初始化完成,数量是%d"%len(relationVectorList))
self.entityList = entityVectorList
self.relationList = relationVectorList
def transE(self, cI = 20):
print("训练开始")
for cycleIndex in range(cI):
Sbatch = self.getSample(3)
Tbatch = []#元组对(原三元组,打碎的三元组)的列表 :{((h,r,t),(h',r,t'))}
for sbatch in Sbatch:
tripletWithCorruptedTriplet = (sbatch, self.getCorruptedTriplet(sbatch))
# print(tripletWithCorruptedTriplet)
if(tripletWithCorruptedTriplet not in Tbatch):
Tbatch.append(tripletWithCorruptedTriplet)
self.update(Tbatch)
if cycleIndex % 100 == 0:
print("第%d次循环"%cycleIndex)
print(self.loss)
self.writeRelationVector("E:\pythoncode\knownlageGraph\\transE-master\\relationVector.txt")
self.writeEntilyVector("E:\pythoncode\knownlageGraph\\transE-master\\entityVector.txt")
self.loss = 0
def getSample(self, size):
return sample(self.tripleList, size)
def getCorruptedTriplet(self, triplet):
'''
training triplets with either the head or tail replaced by a random entity (but not both at the same time)
:param triplet:
:return corruptedTriplet:
'''
i = uniform(-1, 1)
if i < 0: # 小于0,打坏三元组的第一项
while True:
entityTemp = sample(self.entityList.keys(), 1)[0]
if entityTemp != triplet[0]:
break
corruptedTriplet = (entityTemp, triplet[1], triplet[2])
else: # 大于等于0,打坏三元组的第二项
while True:
entityTemp = sample(self.entityList.keys(), 1)[0]
if entityTemp != triplet[1]:
break
corruptedTriplet = (triplet[0], entityTemp, triplet[2])
return corruptedTriplet
def update(self, Tbatch):
copyEntityList = deepcopy(self.entityList)
copyRelationList = deepcopy(self.relationList)
for tripletWithCorruptedTriplet in Tbatch:
headEntityVector = copyEntityList[
tripletWithCorruptedTriplet[0][0]] # tripletWithCorruptedTriplet是原三元组和打碎的三元组的元组tuple
tailEntityVector = copyEntityList[tripletWithCorruptedTriplet[0][1]]
relationVector = copyRelationList[tripletWithCorruptedTriplet[0][2]]
headEntityVectorWithCorruptedTriplet = copyEntityList[tripletWithCorruptedTriplet[1][0]]
tailEntityVectorWithCorruptedTriplet = copyEntityList[tripletWithCorruptedTriplet[1][1]]
headEntityVectorBeforeBatch = self.entityList[
tripletWithCorruptedTriplet[0][0]] # tripletWithCorruptedTriplet是原三元组和打碎的三元组的元组tuple
tailEntityVectorBeforeBatch = self.entityList[tripletWithCorruptedTriplet[0][1]]
relationVectorBeforeBatch = self.relationList[tripletWithCorruptedTriplet[0][2]]
headEntityVectorWithCorruptedTripletBeforeBatch = self.entityList[tripletWithCorruptedTriplet[1][0]]
tailEntityVectorWithCorruptedTripletBeforeBatch = self.entityList[tripletWithCorruptedTriplet[1][1]]
if self.L1:
distTriplet = distanceL1(headEntityVectorBeforeBatch, tailEntityVectorBeforeBatch,
relationVectorBeforeBatch)
distCorruptedTriplet = distanceL1(headEntityVectorWithCorruptedTripletBeforeBatch,
tailEntityVectorWithCorruptedTripletBeforeBatch,
relationVectorBeforeBatch)
else:
distTriplet = distanceL2(headEntityVectorBeforeBatch, tailEntityVectorBeforeBatch,
relationVectorBeforeBatch)
distCorruptedTriplet = distanceL2(headEntityVectorWithCorruptedTripletBeforeBatch,
tailEntityVectorWithCorruptedTripletBeforeBatch,
relationVectorBeforeBatch)
eg = self.margin + distTriplet - distCorruptedTriplet
if eg > 0: # [function]+ 是一个取正值的函数
self.loss += eg
if self.L1:
tempPositive = 2 * self.learingRate * (
tailEntityVectorBeforeBatch - headEntityVectorBeforeBatch - relationVectorBeforeBatch)
tempNegtative = 2 * self.learingRate * (
tailEntityVectorWithCorruptedTripletBeforeBatch - headEntityVectorWithCorruptedTripletBeforeBatch - relationVectorBeforeBatch)
tempPositiveL1 = []
tempNegtativeL1 = []
for i in range(self.dim): # 不知道有没有pythonic的写法(比如列表推倒或者numpy的函数)?
if tempPositive[i] >= 0:
tempPositiveL1.append(1)
else:
tempPositiveL1.append(-1)
if tempNegtative[i] >= 0:
tempNegtativeL1.append(1)
else:
tempNegtativeL1.append(-1)
tempPositive = array(tempPositiveL1)
tempNegtative = array(tempNegtativeL1)
else:
#根据损失函数的求梯度
tempPositive = 2 * self.learingRate * (
tailEntityVectorBeforeBatch - headEntityVectorBeforeBatch - relationVectorBeforeBatch)
tempNegtative = 2 * self.learingRate * (
tailEntityVectorWithCorruptedTripletBeforeBatch - headEntityVectorWithCorruptedTripletBeforeBatch - relationVectorBeforeBatch)
headEntityVector = headEntityVector + tempPositive#更新向量
tailEntityVector = tailEntityVector - tempPositive
relationVector = relationVector + tempPositive - tempNegtative
headEntityVectorWithCorruptedTriplet = headEntityVectorWithCorruptedTriplet - tempNegtative
tailEntityVectorWithCorruptedTriplet = tailEntityVectorWithCorruptedTriplet + tempNegtative
# 只归一化这几个刚更新的向量,而不是按原论文那些一口气全更新了
copyEntityList[tripletWithCorruptedTriplet[0][0]] = norm(headEntityVector)
copyEntityList[tripletWithCorruptedTriplet[0][1]] = norm(tailEntityVector)
copyRelationList[tripletWithCorruptedTriplet[0][2]] = norm(relationVector)
copyEntityList[tripletWithCorruptedTriplet[1][0]] = norm(headEntityVectorWithCorruptedTriplet)
copyEntityList[tripletWithCorruptedTriplet[1][1]] = norm(tailEntityVectorWithCorruptedTriplet)
self.entityList = copyEntityList
self.relationList = copyRelationList
def writeEntilyVector(self, dir):
print("写入实体")
entityVectorFile = open(dir, 'w', encoding="utf-8")
for entity in self.entityList.keys():
entityVectorFile.write(entity + " ")
entityVectorFile.write(str(self.entityList[entity].tolist()))
entityVectorFile.write("\n")
entityVectorFile.close()
def writeRelationVector(self, dir):
print("写入关系")
relationVectorFile = open(dir, 'w', encoding="utf-8")
for relation in self.relationList.keys():
relationVectorFile.write(relation + " ")
relationVectorFile.write(str(self.relationList[relation].tolist()))
relationVectorFile.write("\n")
relationVectorFile.close()
def init(dim):
return uniform(-6/(dim**0.5), 6/(dim**0.5))
def norm(list):
'''
归一化
:param 向量
:return: 向量的平方和的开方后的向量
'''
var = linalg.norm(list)
i = 0
while i < len(list):
list[i] = list[i]/var
i += 1
return array(list)
def distanceL1(h, t ,r):
s = h + r - t
sum = fabs(s).sum()
return sum
def distanceL2(h, t, r):
s = h + r - t
sum = (s*s).sum()
return sum
def openDetailsAndId(dir,sp=" "):
idNum = 0
list = []
with open(dir,"r", encoding="utf-8") as file:
lines = file.readlines()
for line in lines:
DetailsAndId = line.strip().split(sp)
list.append(DetailsAndId[0])
idNum += 1
return idNum, list
def openTrain(dir,sp=" "):
num = 0
list = []
with open(dir, "r", encoding="utf-8") as file:
lines = file.readlines()
for line in lines:
triple = line.strip().split(sp)
if(len(triple)<3):
continue
list.append(tuple(triple))
num += 1
return num, list
if __name__ == '__main__':
dirEntity = "E:\pythoncode\ZXknownlageGraph\TransEgetvector\entity2id.txt"
entityIdNum, entityList = openDetailsAndId(dirEntity)
dirRelation = "E:\pythoncode\ZXknownlageGraph\TransEgetvector\\relation2id.txt"
relationIdNum, relationList = openDetailsAndId(dirRelation)
dirTrain = "E:\pythoncode\ZXknownlageGraph\TransEgetvector\\train.txt"
tripleNum, tripleList = openTrain(dirTrain)
# print(tripleNum, tripleList)
print("打开TransE")
transE = TransE(entityList,relationList,tripleList, margin=1, dim = 128)
print("TranE初始化")
transE.initialize()
transE.transE(1500)
transE.writeRelationVector("E:\pythoncode\ZXknownlageGraph\TransEgetvector\\relationVector.txt")
transE.writeEntilyVector("E:\pythoncode\ZXknownlageGraph\TransEgetvector\\entityVector.txt")
数据
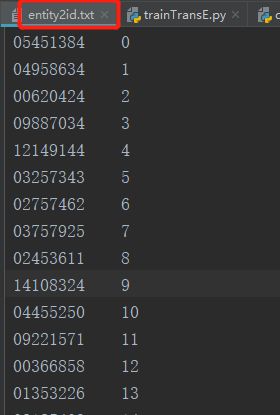
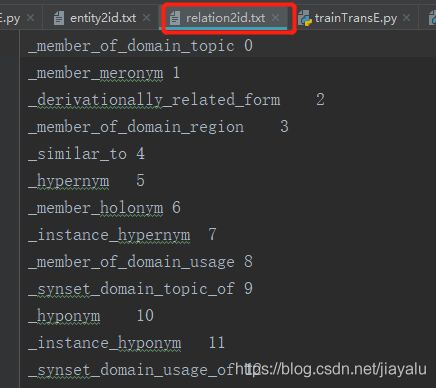
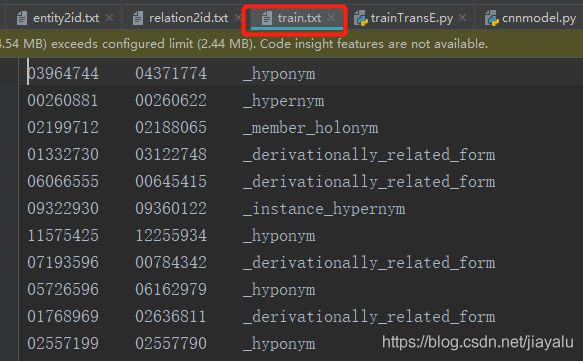
结果向量