固定效应模型
一、面板数据优点
1. 可以解决遗漏变量的问题:遗漏变量由于不可观测的个体差异或“异质性”造成的,如果这种个体差异“不随时间而改变”,则面板数据提供了解决遗漏变量问题的又一利器。
2. 提供更多个体动态行为的信息:由于面板数据同时有横截面与时间两个维度,优势它可以解决单独的截面数据或时间序列数据所不能解决的问题。
3. 样本容量较大:由于同时有截面维度与时间维度,通常面板数据的样本容量更大,从而可以提高估计的精确度。
估计面板数据长假定个体的回归方程拥有相同的斜率,但可以有不同的截距,以此来捕捉异质性。
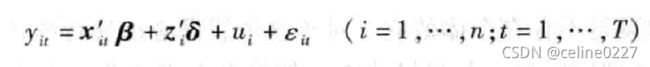
扰动项由![]() 两部分构成,不可观测随机变量
两部分构成,不可观测随机变量 代表个体异质性的截距项,
代表个体异质性的截距项,![]() 为随个体与时间而改变的扰动项。假设
为随个体与时间而改变的扰动项。假设![]() 为独立同分布且与不相关。
为独立同分布且与不相关。
如果与某个解释变量相关,则进一步称为固定效应模型;如果与所有解释变量均不相关,则称为随机变量模型 。
二、混合回归
如果个体都拥有完全一样的回归方程,则方程可以写成

不包括常数项,就可以吧所有的数据放在一起,像对待横截面数据那样进行OLS回归。对于面板数据虽然可以假设所有的扰动项之间相互独立,但同一个体在不同时期的扰动项之间往往存在自相关。对标准误的估计应该使用聚类稳健的标准误,而所谓的聚类,就是每个个体不同时期的所有观测值所组成。同一聚类的观测值允许存在相关性,不同聚类的观测值则不相关。
混合回归的基本假设是不存在个体效应。混合回归也被成为“总体平均估计量”可以理解为把个体效应都给平均掉了。
三、个体固定效应模型


组内离差——![]() 被称为“组内估计量”
被称为“组内估计量”
(1)即使个体特征与解释变量![]() 相关,只要使用组内估计量,就可以得到一致估计。
相关,只要使用组内估计量,就可以得到一致估计。
(2)![]() 无法估计不随时间变化的变量的影响。
无法估计不随时间变化的变量的影响。
(3)扰动项与各期解释变量均不相关,是比较强的假定。
LSDV(Least Square Dummy Variable Model):如果在原方程中引入(n-1)个虚拟变量(如果没有截距项则引入n个虚拟变量)来代表不同的个体,可以得到相同的结果。但如果做完LSDV后删除不显著的个体虚拟变量则结果不一致。
LSDV的优点是能够得到对个体异质性的估计;缺点是如果n很大,则需要在方程中引入多个虚拟变量。
四、时间固定效应
个体固定效应模型解决了不随时间而变但随个体而异的遗漏变量问题,引入时间固定效应,则可以解决不随个体而变但随时间而变的遗漏变量问题。


五、 行业固定效应
在实证论文中我们通常可以看到文章没有做个体的固定效应,而是做了行业的固定效应。因为控制个体固定效应相当于为每一个个体(公司)都设置不同的截距项,而行业固定效应只需要为每一个行业设置不同的截距项,自然模型的要求低了很多。
对于同时控制个体和行业
控制个体时是随个体变化,不随时间变化的,所以,当你考虑其他不随时间变量的因素(行业、省份、区域、企业性质、银行所有制性质等)时,其实他们的信息都在个体中反应出来了,所以再设置不随时间变化的变量时,就是多余的了。(这里的主要原因是:若个体固定效应模型是采用Within回归(xtreg , fe),它会将不随时点变化的量都减去了,所以,如果模型中不随时点变化的虚拟变量(包括个体固定效应项)的属个数如果大于N(无截距项情形;有截距项就是N-1个),它只能估计出前N个,其他的都不在模型中;若是采用LSDV法估计个体固定效应模型(reg i.number),是设置了N-1个虚拟变量实现的,如果再往模型里加不随时点变化的虚拟变量(如行业、区域等),模型是会将它们排除在模型里面的。)所以,一些文献关于,在有个体固定效应的基础上,考虑控制(行业、省份、区域、企业性质、银行所有制性质等)这类不随时间变化的因素的影响时,不知道他们是如何控制的。
除时间FE,其他非时变的FE均可由个体FE线性表出,这就意味着如果模型中控制多个非时变的FE,其他FE总能被个体FE表出,即存在多重共线性的问题,这样的FE将被omitted。因此,许多论文不会在模型中同时控制个体FE和行业FE。
然而,这并不是说同时控制个体FE和行业FE是不可行的。一种特殊情况是,如果企业所属行业发生变更(如环境规制政策实施前后,部分制造业企业选择变更行业以规避政策的不利影响或套取政策红利,虽然后一种情况比较少),在这种情况下行业FE将不再是非时变的了,因此行业FE就不会再被个体FE线性表出。况且,就算不存在企业跨行转移的情况,也可以通过附上时变因素来规避共线性的问题。
六、交互固定效应
年份FE的同质性就是假定在同一年份某一不可观测因素(如政策冲击、经济周期等)对所有企业的结果变量y的作用方向、作用大小是一样的。但是,现实的经济冲击并不会对所有企业产生一致的同质性影响,不同企业因自身实力、价值链地位、所有者性质等的不同在面对同一经济冲击时做出的战略性反应不同,从而导致最终的结果不同。
行业FE表征企业所属行业的不可观测的典型特征对企业的同质性影响,换言之,如果怀疑行业的某些特征对行业内所有企业的y均存在影响(如金融业企业一般都比较“赚钱”),并且对行业内的不同企业的作用大小不存在明显差异,那么行业FE就可以代表这样的行业特征。行业FE假定同一行业中的样本行业特征是近似一致的。(这一假定从数据集中也可以看出来,即同一行业样本的indfe#均赋值为1(属于行业#),或者均赋值为0(不属于行业#)。其他FE同理。)
总结来说就是,控制时间FE仅仅考虑到了时间维度上的同质性经济冲击,但现实中的经济冲击将对不同类型企业产生异质性影响,为将这些不可观测的异质性冲击因素控制住,回归方程需要引入交互FE。
交互FE比单独的FE更严格,交互FE本质上包含了单个FE,引入过多的虚拟变量可能导致核心解释变量统计上不显著,甚至造成符号与预期相反,这种情况下就需要仔细斟酌一下,到底是经济系统本身就是这种运行规律?还是说过多的虚拟变量导致某些控制变量被omitted,从而影响了估计结果?切不能简单地“见Star行事”,因为某些情况下基于这样的交互FE得出的结果更能反映经济系统本身的运行规律,且不显著的回归结果某种程度上可以讨论出影响机制,增强论文的故事性,比如分样本回归。
但是,有一种情况建议使用交互FE。假设基于某个政策做一个DID,“两高一剩”行业企业treated赋值为1,其他企业赋值为0;2012年及以后post赋值为1,以前赋值为0;被解释变量是企业TFP。观察这一模型的数据结构可以发现,被解释变量是企业级别,核心解释变量是行业 - 年份级别。那么,为了控制企业级别的不可观测因素对企业TFP的影响,同时为了控制样本期间其他所有行业级别的环境规制政策对企业TFP的影响,模型就需要引入企业FE和行业 - 年份FE,至于行业代码具体细化到什么程度,这就是另外的故事了。
七、面板数据的stata命令
1. 面板数据设定
xtset panelvar timevar
xtdes //显示面板数据的结构,是否为平衡面板
xtsum //显示组内、组间与整体的统计指标
xttab varname //显示组内、组间与整体的分布频率,tab指的是tabulate
xtline varname //对每个个体分别显示该变量的时间序列图;如果希望所有个体的时间序列图叠放在一起,可加上选择项overlay2. 混合回归
reg y x1 x2 x3,vce(cluster id) //聚类标准误估计准确3. 固定效应
xtreg y x1 x2 x3,fe r
*-LSDV法的stata命令:
reg y x1 x2 x3 i.id, r
//其中r表示聚类稳健标准误,使用vce(cluster id)能达到一样的效果
i.id则表示根据变量id而生成的虚拟变量(1)如果通过LSDV法得到大多数个体虚拟变量都很显著,即认为存在个体效应,不应该使用混合回归。
(2)双向固定效应模型
xtreg y x1 x2 x3 i.year,fe r(3)交互固定效应
regife ln_w tenure, f(id year, 1) //考虑一维交互固定效应
regife ln_w tenure, a(id) f(id year, 1) //加入个体固定效应
regife ln_w tenure, a(id year) f(id year, 1) // 加入个体和时间固定效应
regife ln_w tenure, f(fid = id fyear = year, 1) //生成因子载荷和共同因子并保存在新变量fid、fyear中
regife ln_w tenure, f(id year, 1) residuals(newvar) //保存残差项eg.加入省份*年固定效应
encode province,gen(province2) //首先对字符变量解码成数值变量
regife ln_Cash_ratio1 lnnumber_in_5km $control, a(stkcd year) ife(province2 year, 1)rehdfe也可以做交互效应
reghdfe ln_w grade age ttl_exp tenure not_smsa , absorb(idcode#occ)
reghdfe lny x1 x2,absorb(i.region#i.industry i.region#i.year i.industry#i.year)
gen plus=province2*year
reghdfe ln_Cash_ratio1 lnnumber_in_5km $control, a(stkcd year plus)
(1)交互的时候要注意考虑维度限制,即自由度够不够。如果是城市面板,那用省和年交互,可能自由度才够。但是如果用城市id和year都比较大,那么会产生非常大的矩阵,自由度也不够,使得Stata无法运算
(2)加了 id#year,没加单独的;还是加了单独,都是控制year和id的特征,核心变量系数一般不会这两种选择而不同,对结果影响不大。但是如果你的 id 和 year 都比较大,那么运算速度是一个问题。
(3)regife 与 reghdfe 原理是不一样的
4. 豪斯曼检验
xtreg y x1 x2 x3,fe //固定效应估计
estimates store FE
xtreg y x1 x2 x3,re //随机效应估计
estimates store RE
hausman FE RE,constant sigmamore //豪斯曼检验
八、聚类(解决自相关问题)
加入个体层面的固定效应将使得残差项里不再包括那些不随时间变化的遗漏变量,然而,残差项的方差是否一致,是否自相关的问题都未得到解决。而聚类稳健标准误(比如你对公司聚类)则使得公司层面的异方差问题得到解决。
即固定效应的目的是解决内生性问题,为了使得系数估计无偏且一致,使得因果识别更干净。可以理解为一组控制变量。稳健标准误的目的是为了系数估计量估计的准确性,系数估计量的准确性会取决于扰动项的相关性,因此不同的标准误的形式对应着关于不同的个体之间扰动项相关性的假设
reg y1 x1 x2 x3 x4,vce(cluster state) //"state"为聚类变量的聚类稳健标准误
reg y1 x1 x2 x3 x4 //普通标准误个体变量在不同时期之间的扰动项一般会存在自相关,磨人的普通标准无计算方法假设扰动项为独立同分布的,故普通标准误的估计并不准确。
PS(只要使用了稳健标准误,就可以和异方差和平共处了)
reg y x,robust