Spark 3.3.0安装
一、准备安装包
1、下载地址
Downloads | Apache Spark
我们这次用的Spark 3.3.0 (Jun 16 2022) 版本
Apache Download Mirrors
2、将下载好的压缩包上传到服务器主节点的/opt/soft目录下,如果网络ok,可以直接wget下来
wget Apache Download Mirrors -P /opt/soft
3、解压并设置软连接
tar -xzvf spark-3.3.0-bin-hadoop3.tgz
ln -s spark-3.3.0-bin-hadoop3 spark-3.3.0
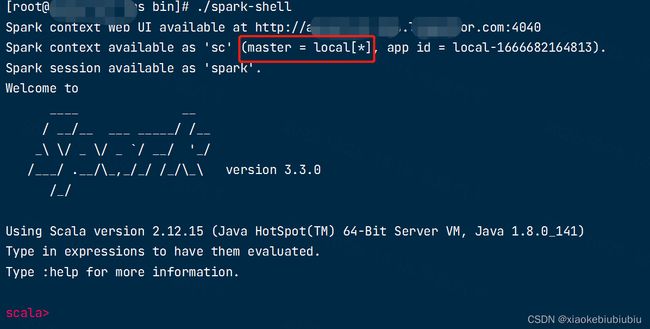
4、测试local模式
cd /opt/soft/spark-3.3.0/bin/
./spark-shell
二、环境准备
1、安装python3
可使用anaconda包(我这边用的是自己的,或者去官网下载下也是可以的)
wget http://10.x.x.2/data-images/anaconda3.tar.gz -P /opt/soft
ln -s /opt/soft/anaconda3/bin/python3 /usr/bin/python3
python3 -V
2、测试pyspark
cd /opt/soft/spark-3.3.0/bin/
./pyspark
三、Spark On Yarn 模式 的环境搭建
1、添加CDH环境配置
软链接hadoop/hive相关的配置文件到 conf目录下
cd /opt/soft/spark-3.3.0/conf
ln -s /etc/hive/conf/hdfs-site.xml hdfs-site.xml
ln -s /etc/hive/conf/mapred-site.xml mapred-site.xml
ln -s /etc/hive/conf/yarn-site.xml yarn-site.xml
ln -s /etc/hive/conf/core-site.xml core-site.xml
ln -s /etc/hive/conf/hive-env.sh hive-env.sh
ln -s /etc/hive/conf/hive-site.xml hive-site.xml
2、添加spark配置
cd /opt/soft/spark-3.3.0/conf
2.1 spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
在配置文件底部添加下面的配置
# hive metastore的版本设置为 2.1.1
spark.sql.hive.metastore.version=2.1.1
# 引用 hive2.1.1 相关的jar包
spark.sql.hive.metastore.jars=/opt/cloudera/parcels/CDH/lib/hive/lib/*
# 设置 spark提交任务默认的 yarn 队列
spark.yarn.queue=root.users -----这里我先设置到公共区
2.2 spark-env.sh
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
在配置文件底部添加下面的配置
export HADOOP_CONF_DIR=/etc/hadoop/conf # 添加 hadoop 配置文件的路径
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=39888 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://nameservice1/user/spark3/spark3log"
# 添加 spark job history 相关参数 包括 web ui的端口[端口记得先做下冲突测试] / 缓存的spark作业日志数目 / 日志的hdfs路径
2.3 log4j.properties
cp log4j.properties.template log4j.properties # 复制log4j模板, 添加 默认的log4j配置
rootLogger.level = WARN
rootLogger.appenderRef.stdout.ref = console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}:%m%n
2.4 spark-sql命令
vi /opt/soft/spark-3.3.0/bin/spark-sql
在头部添加SPARK_HOME配置,以避免使用 CDH 集群的 spark jar包
SPARK3_HOME=SPARK3_HOME=/opt/soft/spark-3.3.0
三、分发spark软件包
将/opt/soft/spark-3.3.0整包发送到各个客户端,并添加快捷命令
先压缩包,然后放到oss上
使用spug或者ansible批量执行
wget http://10.x.x.2/data-images/spark-3.3.0-dw.tar.gz -P /opt/soft
tar -xzvf /opt/soft/spark-3.3.0-dw.tar.gz -C /opt/soft
ln -s /opt/soft/spark-3.3.0/bin/pyspark /usr/bin/pyspark3
ln -s /opt/soft/spark-3.3.0/bin/spark-sql /usr/bin/spark3-sql
ln -s /opt/soft/spark-3.3.0/bin/spark-submit /usr/bin/spark3-submit
echo "export SPARK3_HOME=/opt/soft/spark-3.3.0" >> /etc/profile
echo "export PATH=$SPARK3_HOME/bin:$HBASE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$PATH" >> /etc/profile
四、spark on yarn 测试
# 进入到 spark3.0.1 的 bin目录
cd /opt/soft/spark-3.3.0/bin/
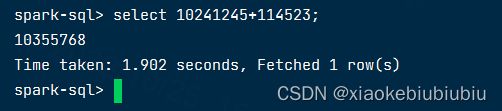
1、spark-sql测试
spark3-sql --master yarn --name spark-sql-test
--master 集群模式,on yarn
--name application的name,自定义

2、pyspark测试
3、Spark-submit测试(on yarn)
spark3-submit --master yarn --conf "spark.pyspark.driver.python=/opt/soft/anaconda3/bin/python3" --conf "spark.pyspark.python=/opt/soft/anaconda3/bin/python3" ${SPARK3_HOME}/examples/src/main/python/pi.py 10
五、spark thriftserver 使用
启动spark thriftserver
注意需要添加启动端口号的配置
cd $SPARK_3_0_1_HOME/sbin
启动thriftserver
./start-thriftserver.sh \
--master yarn \
--executor-memory 512m \
--hiveconf hive.server2.thrift.port=10005
使用spark3.0.1 自带的beeline进行连接
