自监督学习(SSL)Self-Supervised Learning
目录
监督、无监督、半监督、弱监督、自监督学习
核心思想
前置任务Pretext Tasks
视图预测 View Prediction (Cross modal-based)
下游任务
分析前置任务的有效性
对 Kernels 和 特征图进行可视化
最近相邻撷取
选择
主要方法
主流分类
generative methods
contrastive methods
2022年,预训练何去何从?
监督、无监督、弱监督、半监督、自监督学习
有监督:用有标签的数据训练;
无监督:用无标签的数据训练;
弱监督:用包含噪声的有标签数据训练。
半监督:同时用有标签和无标签的数据进行训练。
最近非常火热,此领域的发展也非常迅速,
先前通常是两阶段的训练,
先用(较小规模的)有标签数据训练一个Teacher模型,
再用(较大规模的)无标签数据预测伪标签,作为Student模型的训练数据;
目前已经有很多直接end-to-end地训练,大大减少半监督训练的工作;
自监督:在无标注数据上训练,
通过一些方法让模型学习到数据的inner representation,再接下游任务,例如加一个mlp作为分类器等。
但接了下游任务之后还是需要在特定的有标签数据上finetune,只是有时候可以选择把前面的层完全固定,只finetune后面接的网络的参数。

评测自监督学习的能力,主要是通过 Pretrain-Fintune 的模式。
监督的 Pretrain - Finetune 流程:
1.从大量的有标签数据上进行训练,得到预训练的模型,
2.对于新的下游任务(Downstream task),我们将学习到的参数(比如输出层之前的层的参数)进行迁移,在新的有标签任务上进行「微调」,从而得到一个能适应新任务的网络。
自监督的 Pretrain - Finetune 流程:
1.从大量无标签数据中通过 pretext 训练网络(自动在数据中构造监督信息),得到预训练的模型
2.对于新的下游任务,和监督学习一样,迁移学习到的参数后微调即可。
所以自监督学习的能力主要由下游任务的性能来体现。
supervised learning 的特点:
- 对于每一张图片,机器预测一个 category 或者是 bounding box
- 训练数据都是人工标注的
- 每个样本只能提供非常少的信息(比如 1024 个 categories 只有 10 bits 的信息)
self-supervised learning 的特点:
- 对于一张图片,机器可以预测任何的部分(自动构建监督信号)
- 对于视频,可以预测未来的帧
- 每个样本可以提供很多的信息
核心思想
Self-Supervised Learning
1.用无标签数据将先参数从无训练到初步成型, Visual Representation。
2.再根据下游任务 (Downstream Tasks) 的不同去用带标签的数据集把参数训练到完全成型,
那这时用的数据集量就不用太多了,因为参数经过了第1阶段就已经训练得差不多了。
第一个阶段不涉及任何下游任务,就是拿着一堆无标签的数据去预训练,没有特定的任务,这个话用官方语言表达叫做:in a task-agnostic way。
第二个阶段涉及下游任务,就是拿着一堆带标签的数据去在下游任务上 Fine-tune,这个话用官方语言表达叫做:in a task-specific way。
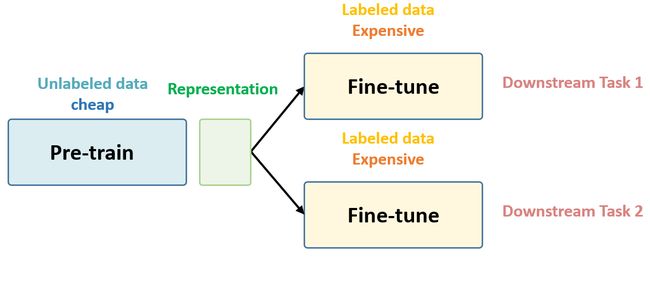
涉及领域
Self-Supervised Learning 不仅是在NLP领域,在CV, 语音领域也有很多经典的工作,它可以分成3类:Data Centric, Prediction (也叫 Generative) 和 Contrastive。
浅层捕获一些低级特征,如边缘、拐角和纹理,而较深层捕获与任务相关的高级特征。因此,在受监督的下游任务训练阶段,只是转移了前几层的视觉特征。
前置任务Pretext Tasks
前置任务的本质是:模型可以学习到数据本身的一些转换(数据转换之后依然被认作是原数据,转换后到数据和原数据处于同一嵌入空间),同时模型可以判别其他不同的数据样本。
但是前置任务本身是一把双刃剑,某个特定的前置任务可能对某些问题有利,对其他问题
原始图片被当作一种anchor,其增强的图片被当作正样本(positive sample),然后其余的图片被当作负样本。
大多数的前置任务可以被分为四类:
- 颜色变换:原图,高斯噪声,高斯模糊,颜色失真
- 几何变换:原图,裁剪、旋转、翻转
- 基于上下文的任务:
拼图(空间):原图被当作anchor,分割成小图片,打乱后的图片被当作正样本,其余图片被当作负样本
时序(时间):
一个视频中的帧被当作正样本,其余视频被当作负样本。
或者 随机抽样一个长视频中的两个片段,或者对每个视频片段做几何变换。
一对正样本是两个增强的来自同一个视频的视频片段
- 基于交叉模式的任务
视图预测 View Prediction (Cross modal-based)
视图预测任务一般用在数据本身拥有多个视图的情况下。
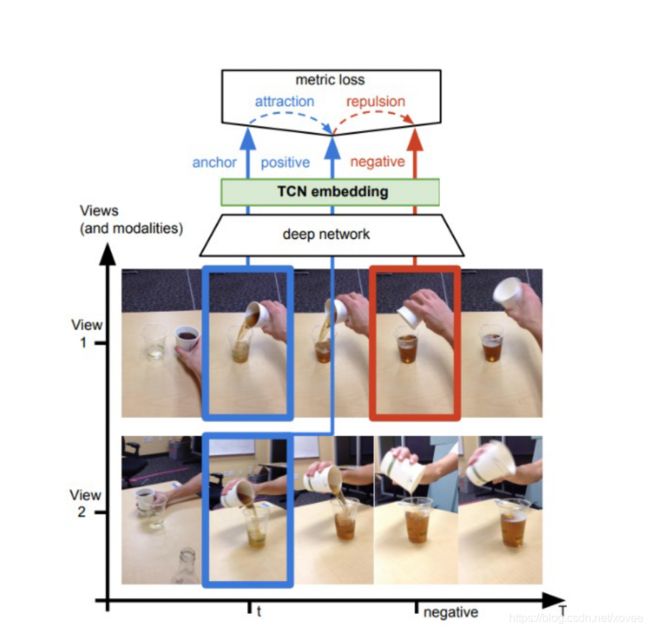
在 [23] 中,anchor和它的正样本图片来自同时发生的视角下,它们在嵌入空间中应当尽可能地近,与来自时间线中其他位置的负样本图片尽可能地远。
在 [24] 中,一个样本的多视角被当作正样本(intra-sampling),其余的inter-sampling当作负样本。
下游任务
下游任务聚焦于具体的应用,在优化下游任务的时候,模型利用到了前置任务优化时期所学到的知识。这些任务可以是分类、检测、分割、预测等
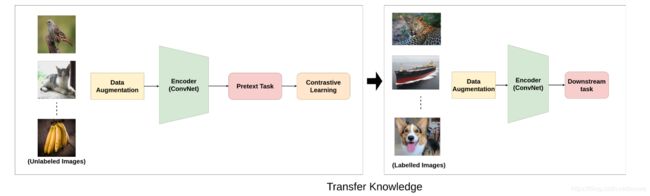
迁移学习
分析前置任务的有效性
常见的下游高级视觉任务:
Semantic Segmentation(语义分割):为图像中每个像素分配语义标签的任务。
Object Detection(目标检测):在图像中定位目标位置别识别其类别的任务。
Image Classification(图像分类):识别每个图像中对象类别的任务,通常每个图像只能使用一个类别标签。将自监督学习模型应用于每个图象上来提取特征,然后用这些特征训练一个分类器(如SVM),将分类器在测试集上的表现与自监督模型进行比较,来评估所学特征的质量。
Human Action Recognition(人体行为识别):识别视频中的人们在做什么,以获取预定义动作类别的列表。通常用于从视频中学习到的特征的质量。
为了测试自监督学习中学习到的特征对下游任务的效果,一些方法,例如
- kernel visualization
- feature map visualization
- nearsest-neighbor based approaches
除了以上对所学特征进行定量的评估之外,还有一些定性可视化的方法对自监督学习的特征进行评估(Qualitative Evaluation):
Kernel Visualization: 定性的可视化通过前置任务学习的第一个卷积层的内核,并比较监督模型的内核。通过比较监督学习模型和自监督学习模型内核的相似性,来评估其有效性。
Feature Map Visualization: 可视化特征图来显示网络的关注区域,较大的激活表示神经网络更关注图像中的相应区域,通常对特征图进行定性可视化,并与监督模型进行比较。
Nearest Neighbor Retrieval: 通常具有相似外观的图像在特征空间中更靠近。最近邻方法用于从自监督学习模型学习的特征的特征空间中找到前K个最近的邻居。
对 Kernels 和 特征图进行可视化
在这里,第一个卷积层的特征的kernels(分别来自于自监督训练和监督训练)被用来做比较。
类似地,不同层的 attention maps 也可以被用来测试模型的有效性。

AlexNet所训练的 attention map
最近相邻撷取
一般来说,相同类的样本在隐藏空间中的位置应该相近。对一个输入的样本,使用最近相邻方法,可以在数据集中使用 top-K 抽取来分析自监督学习的模型是否有效。
将学习到参数用作预训练模型,然后对下游高级任务进行微调,这种迁移学习的能力可以证明所学特征的泛化能力。
选择
1、Shotcuts: 根据自己的数据和任务特点设计辅助任务,常常有事半功倍的效果。比如对于镜头检测任务来说,获取成像色差、镜头畸变以及暗角等信息来构造辅助任务是比较有效的
2、辅助任务的复杂度选择: 之前人们的实验结果表明,辅助任务并不是越复杂越有效,比如图像重组任务中,最优的patch数为9,patch太多会导致每个patch特征过少,并且相邻patch间的差异性不大,导致模型的学习效果并不好
3、模糊性: 模糊性是指设计的辅助任务的标签必须是唯一确定的,不然会给网络学习引入噪声,影响模型性能。比如在动作预测中,这个半蹲的动作就具有二义性,因为其下个状态有可能是蹲下,也有可能是正在站起,标签不具有唯一性
主要方法
1. 基于上下文(Context based)
2. 基于时序(Temporal Based)
3. 基于对比(Contrastive Based)
主流分类
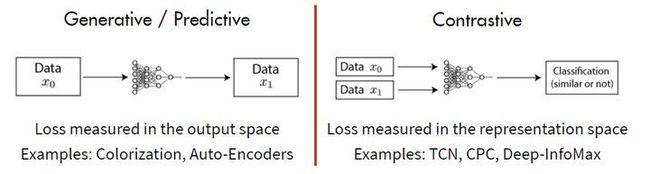
generative methods
能重建=>则能提取好的特征表达
eg:MAE、BERT
contrastive methods
在特征空间上对不同的输入进行分辨
图一:对比学习的直观理解:让原图片和增强的图片变近,让原图片和其他图片变远。
最近,自监督学习结合了生成模型和对比模型的特点:从大量无标签数据中学习表示。
一种流行的方式是设计各种前置任务(pretext task)来让模型从伪标签中来学习特征。例如图像修复、图像着色、拼图、超分辨率、视频帧预测、视听对应等。这些前置任务被证明可以学习到很好的表示。
图二:对比自监督学习训练范式
参考链接:
自监督学习 | (1) Self-supervised Learning入门_CoreJT的博客-CSDN博客_自监督学习
自监督学习 | (2) 一文读懂 Self-Supervised Learning_CoreJT的博客-CSDN博客
对比自监督学习综述 - A Survey of Contrastive Self-Supervised Learning_Xovee的博客-CSDN博客_自监督对比学习
自监督学习(Self-supervised Learning)_乐乐lelele的博客-CSDN博客_自监督学习
有监督、半监督、无监督、弱监督、自监督的定义和区别_dwqy11的博客-CSDN博客_半监督和弱监督
[23] Sermanet et al., Time-contrastive networks: Self-supervised learning from video, 2017.
[24] Tao et al., Self-supervised video representation learning using inter-intra contrastive framework, 2020.