CentOS7安装Spark3.3.0 ON YARN集群并整合HIVE, Spark-On-HIVE
CentOS7安装Spark3.3.0 ON YARN集群并整合HIVE, Spark-On-HIVE
- 1.下载bin压缩包
- 2. 测试local模式
- 2 安装python3
- 3. Spark On Yarn 模式 的环境搭建
-
- 3.1 修改 spark-env.sh 文件
- 3.2 修改hadoop的yarn-site.xml
- 3.3 Spark设置历史服务地址
- 3.4 设置日志级别
- 3.5 配置依赖spark jar包
- 3.6 spark application ON YARN 测试
- 4. SparkSQL整合Hive
-
- 4.1 将hive-site.xml拷贝到spark安装路径conf目录
- 4.2 将mysql的连接驱动包拷贝到spark的jars目录下
- 4.3 修改 hive/conf/hive-site.xml,开启hive的metadata服务
- 4.4. 测试Sparksql整合Hive
最近在学习Spark,在此记录一下Spark3.3.0集群在CentOS7的安装。
集群:
node1 192.168.88.100
node2 192.168.88.101
node3 192.168.88.102
1.下载bin压缩包
注意: Spark3.3.0的环境依赖Java 8/11/17, Scala 2.12/2.13, Python 3.7+、 R 3.5+等, 根据情况自行下载安装。
- 在spark的downloads页面下载spark-3.3.0-bin-hadoop3.tgz压缩包.
- 将下载好的压缩包上传到服务器node1的 /export/software/ 目录下。(可根据情况自行调整,也可以通过wget直接在服务器下载)
- 解压并设置软连接
tar -zxvf spark-3.3.0-bin-hadoop3.tgz -C /export/server/
cd /export/server/
ln -s spark-3.3.0-bin-hadoop3 spark
进入Spark目录可看到有以下文件
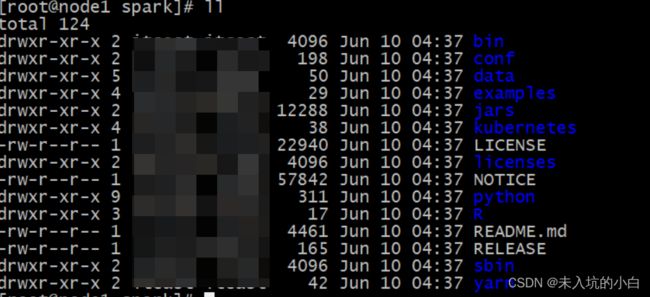
bin: 可执行脚本.
conf: 配置文件.
data: 示例程序使用数据.
examples: 示例程序
jars: 依赖的jar包
python: python API包
sbin: 集群管理命令
yarn: 整合yarn相关内容
2. 测试local模式
Spark的local模式, 开箱即用, 直接启动bin目录下的spark-shell脚本
cd /export/server/spark/bin
./spark-shell.sh
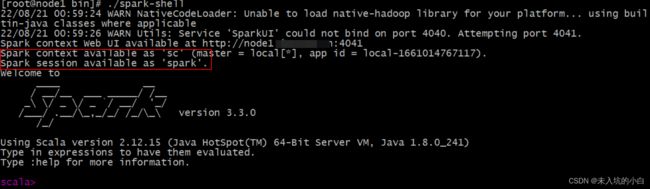
说明: 在spark-shell命令行中
sc:SparkContext实例对象:
spark:SparkSession实例对象
●Spark-shell说明:
1.直接使用./spark-shell
表示使用local 模式启动,在本机启动一个SparkSubmit进程
2.还可指定参数 --master,如:
spark-shell --master local[N] 表示在本地模拟N个线程来运行当前任务
spark-shell --master local[] 表示使用当前机器上所有可用的资源
3.不携带参数默认就是
spark-shell --master local[]
4.后续还可以使用–master指定集群地址,表示把任务提交到集群上运行,如
./spark-shell --master spark://node01:7077,node02:7077
5.退出spark-shell
使用 :quit (快捷键 ctrl + D)
2 安装python3
由于CenOS7自带的python版本是2.X版本的,3台服务器都需要安装python3,安装python3是为了后面的pyspark,具体安装python3参考此博客。
我安装目前最新版python3.10.6
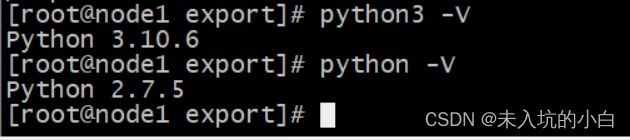
安装完毕后输入 python3 -V
python3 -V
会有以下界面(注意: 别覆盖CenOS7自带的python2.7.5版本, 因为yum命令需要python2的!)
安装python3完毕后,回到/spark/bin目录,输入
cd /export/server/spark/bin
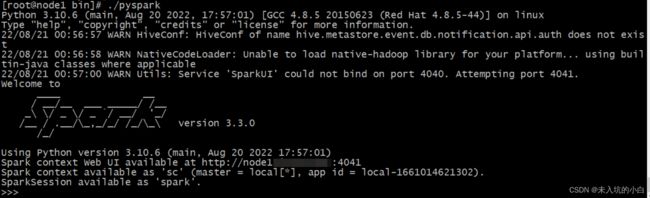
./pyspark
会出现类似spark-shell的界面,只不过spark-shell的界面是scala语言的,pyspark是python的shell界面.
3. Spark On Yarn 模式 的环境搭建
经过以上测试,spark-shell与pyspark都没问题,下面开始搭建Spark On Yarn:
3.1 修改 spark-env.sh 文件
注意: 每台服务器的spark-env.sh 都要修改,为方便,最好在node1修改后分发到node2和node3,我这里是spark先在node1上安装spark,配置完成后统一将spark分发到node2和node3。
cd /export/server/spark/conf
cp spark-env.sh.template spark-env.sh
vim /export/server/spark/conf/spark-env.sh
往文件中添加Hadoop的配置文件路径以及Yarn的配置文件路径:
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
3.2 修改hadoop的yarn-site.xml
注意: 与以上3.1一样,每台服务器的yarn-site.xml 都要修改,为方便,最好在node1修改后分发到node2和node3。
cd /export/server/hadoop-3.3.0/etc/hadoop/
vim /export/server/hadoop-3.3.0/etc/hadoop/yarn-site.xml
添加以下配置:
yarn.resourcemanager.hostname
node1
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.resource.memory-mb
20480
yarn.scheduler.minimum-allocation-mb
2048
yarn.nodemanager.vmem-pmem-ratio
2.1
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
yarn.log.server.url
http://node1:19888/jobhistory/logs
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
3.3 Spark设置历史服务地址
注意: 每台服务器的spark-defaults.sh 都要修改,为方便,最好在node1修改后分发到node2和node3,我这里是spark先在node1上安装spark,配置完成后统一将spark分发到node2和node3。
cd /export/server/spark/conf
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
添加以下内容
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/sparklog/
spark.eventLog.compress true
spark.yarn.historyServer.address node1:18080
spark.yarn.jars hdfs://node1:8020/spark/jars/*
3.4 设置日志级别
注意: 每台服务器的log4j.properties 都要修改,为方便,最好在node1修改后分发到node2和node3,我这里是spark先在node1上安装spark,配置完成后统一将spark分发到node2和node3。
cd /export/server/spark/conf
cp log4j.properties.template log4j.properties
vim log4j.properties
修改以下内容
rootLogger.level = WARN
rootLogger.appenderRef.stdout.ref = console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}:%m%n
3.5 配置依赖spark jar包
当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将依赖Spark相关jar包上传到YARN 集群中,为了节省网络IO时间和存储空间,将Spark相关jar包上传到HDFS目录中,设置属性告知Spark Application应用。
以下命令需要启动 hdfs,为方便,我直接应用start-all.sh
start-all.sh
Hadoop启动后,将spark的jar包上传到指定目录。
hadoop fs -mkdir -p /spark/jars/
hadoop fs -put /export/server/spark/jars/* /spark/jars/
将spark 分发到node2和node3上
cd /export/server/
scp -r spark root@node2:$PWD
scp -r spark root@node3:$PWD
Spark Application运行在YARN上,配置完成。
3.6 spark application ON YARN 测试
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit --master yarn --conf "spark.pyspark.driver.python=/export/server/python3/bin/python3" --conf "spark.pyspark.python=/export/server/python3/bin/python3" ${SPARK_HOME}/examples/src/main/python/pi.py 10
启动报错了,看到报错先别慌,看看报错信息:
22/08/20 19:05:15 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/08/20 19:06:46 ERROR SparkContext: Error initializing SparkContext.
java.io.FileNotFoundException: File does not exist: hdfs://node1:8020/sparklog
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1757)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1750)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1765)
at org.apache.spark.deploy.history.EventLogFileWriter.requireLogBaseDirAsDirectory(EventLogFileWriters.scala:77)
at org.apache.spark.deploy.history.SingleEventLogFileWriter.start(EventLogFileWriters.scala:221)
at org.apache.spark.scheduler.EventLoggingListener.start(EventLoggingListener.scala:83)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:612)
at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:58)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:238)
at py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
at py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.lang.Thread.run(Thread.java:748)
22/08/20 19:06:46 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to send shutdown message before the AM has registered!
22/08/20 19:06:46 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request executors before the AM has registered!
Traceback (most recent call last):
File "/export/server/spark-3.3.0-bin-hadoop3/examples/src/main/python/pi.py", line 32, in <module>
.getOrCreate()
File "/export/server/spark/python/lib/pyspark.zip/pyspark/sql/session.py", line 269, in getOrCreate
File "/export/server/spark/python/lib/pyspark.zip/pyspark/context.py", line 483, in getOrCreate
File "/export/server/spark/python/lib/pyspark.zip/pyspark/context.py", line 197, in __init__
File "/export/server/spark/python/lib/pyspark.zip/pyspark/context.py", line 282, in _do_init
File "/export/server/spark/python/lib/pyspark.zip/pyspark/context.py", line 402, in _initialize_context
File "/export/server/spark/python/lib/py4j-0.10.9.5-src.zip/py4j/java_gateway.py", line 1585, in __call__
File "/export/server/spark/python/lib/py4j-0.10.9.5-src.zip/py4j/protocol.py", line 326, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling None.org.apache.spark.api.java.JavaSparkContext.
: java.io.FileNotFoundException: File does not exist: hdfs://node1:8020/sparklog
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1757)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1750)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1765)
at org.apache.spark.deploy.history.EventLogFileWriter.requireLogBaseDirAsDirectory(EventLogFileWriters.scala:77)
at org.apache.spark.deploy.history.SingleEventLogFileWriter.start(EventLogFileWriters.scala:221)
at org.apache.spark.scheduler.EventLoggingListener.start(EventLoggingListener.scala:83)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:612)
at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:58)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:238)
at py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
at py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.lang.Thread.run(Thread.java:748)
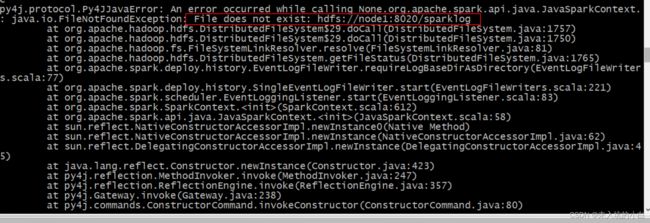
此报错的原因是在HDFS上无SparkLog目录,因此需要在HDFS新建SparkLog目录
hadoop fs -mkdir hdfs://node1:8020/sparklog
然后再次执行以上命令:

至此,spark ON yarn 配置成功!
4. SparkSQL整合Hive
因为hive的hiveserver2服务走的MapReduce,现在需求需要通过thriftserver走内存,所以现在需要整合spark on hive,现有服务器已经有了hive3.1.2,我就偷个懒直接拿来用了,嘿嘿。
4.1 将hive-site.xml拷贝到spark安装路径conf目录
我这里的hive版本是3.1.2;到hive官网上下载apache-hive-3.1.2-bin.tar.gz后,修改 hive/conf/hive-site.xml文件:
javax.jdo.option.ConnectionURL
jdbc:mysql://node1:3306/metastore?createDatabaseIfNotExist=true&useSSL=f
alse
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
XXXXXX
hive.server2.thrift.bind.host
node1
hive.metastore.uris
thrift://node1:9083
hive.metastore.event.db.notification.api.auth
false
hive.zookeeper.quorum
node1,node2,node3
hbase.zookeeper.quorum
node1,node2,node3
hive.server2.enable.doAs
false
然后在node1执行以下命令将hive-site.xml 拷贝到node1、node2、node3这三台服务器的spark安装路径的conf目录:
cd /export/server/hive/conf/
cp hive-site.xml /export/server/spark/conf/
scp hive-site.xml root@node2:/export/server/spark/conf/
scp hive-site.xml root@node3:/export/server/spark/conf/
4.2 将mysql的连接驱动包拷贝到spark的jars目录下
查看node1的/export/server/hive/lib目录有无mysql-connector-java-5.1.32.jar,若无(因为我服务器本来就安装好了hive,我现在整合spark on hive),则需要上传到/export/server/hive/lib目录中,然后在node1执行以下命令将连接驱动包拷贝到spark的jars目录下,三台机器都要进行拷贝;
cd /export/server/hive/lib
cp mysql-connector-java-5.1.32.jar /export/server/spark/jars/
scp mysql-connector-java-5.1.32.jar root@node2:/export/server/spark/jars/
scp mysql-connector-java-5.1.32.jar root@node3:/export/server/spark/jars/
4.3 修改 hive/conf/hive-site.xml,开启hive的metadata服务
1.修改 hive/conf/hive-site.xml新增如下配置:
hive.metastore.uris
thrift://node1:9083
- 后台启动 Hive MetaStore服务
注意: hive需要配置环境变量
nohup hive --service metastore &
4.4. 测试Sparksql整合Hive
1.Spark-sql方式测试
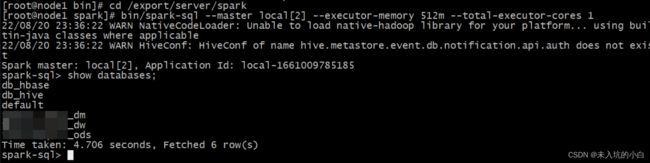
先启动hadoop集群,在启动spark集群,确保启动成功之后node1执行命令,指明master地址、每一个executor的内存大小、一共所需要的核数、mysql数据库连接驱动:
cd /export/server/spark
bin/spark-sql --master local[2] --executor-memory 512m --total-executor-cores 1
连接成功后可以通过show databases; 查看hive中存在的库,如下后缀为_dm、_dw、_ods三个库就是我hive中原来就存在的库。
2. spark-shell 方式测试
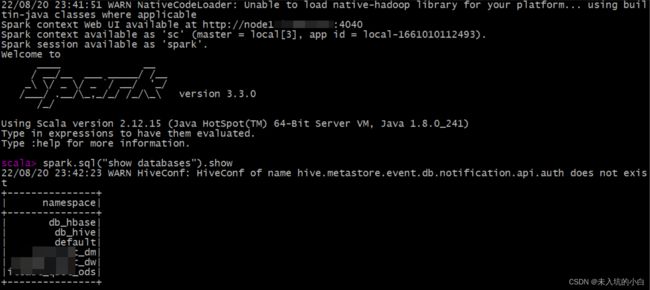
bin/spark-shell --master local[3]
22/08/20 23:41:51 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://node1:4040
Spark context available as 'sc' (master = local[3], app id = local-1661010112493).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.3.0
/_/
Using Scala version 2.12.15 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.sql("show databases").show
至此,完成Spark on hive 的集成!可以愉快的在spark上写SQL了,可以通过开启hive的metadata服务和spark的thrift服务,然后通过navicat、dbeaver、pycharm、idea等工具连接到hive。具体开启spark的thrift服务如下:
cd /export/server/spark/sbin/
./start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10000 \
--hiveconf hive.server2.thrift.bind.host=node1\
--master local[2]
启动完成后,可以通过jps -m命令看是否有SparkSubmit进程,如下:
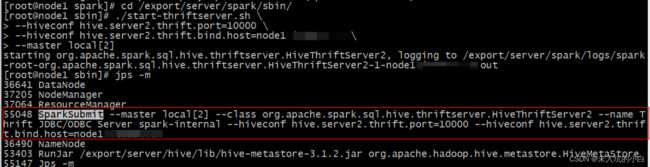
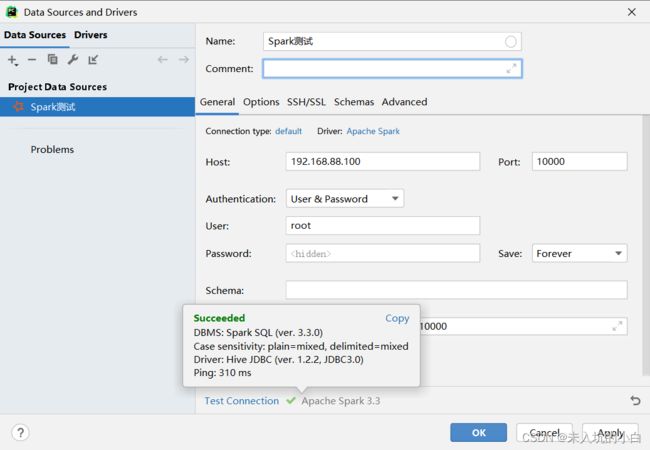
然后通过idea等连接到spark,我以pycharm为例:
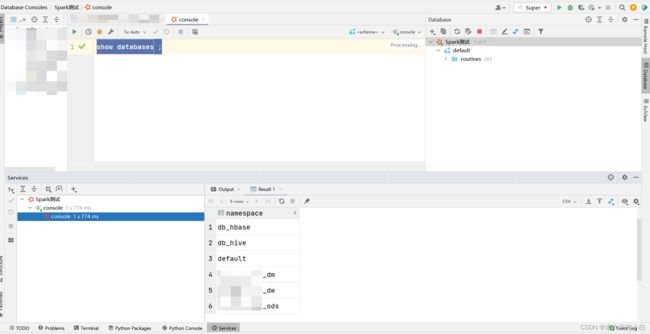
至此,大功告成!!!可以愉快的SQL啦~~