TensorRT自定义插件(plugin)开发(详细)
转载自:实现TensorRT自定义插件(plugin)自由! - 知乎
随着tensorRT的不断发展(v5->v6->v7),TensorRT的插件的使用方式也在不断更新。插件接口也在不断地变化,由v5版本的IPluginV2Ext,到v6版本的IPluginV2IOExt和IPluginV2DynamicExt。未来不知道会不会出来新的API,不过这也不是咱要考虑的问题,因为TensorRT的后兼容性做的很好,根本不用担心你写的旧版本插件在新版本上无法运行。
目前的plugin-API:

TensorRT插件的存在目的,主要是为了让我们实现TensorRT目前还不支持的算子,毕竟众口难调嘛,我们在转换过程中肯定会有op不支持的情况。这个时候就需要使用TensorRT的plugin去实现我们的自己的op。此时我们需要通过TensorRT提供的接口去实现自己的op,因此这个plugin的生命周期也需要遵循TensorRT的规则。
一个简单的了解
那么plugin到底长啥样,可以先看看TensorRT的官方plugin库长啥样,截止写这篇文章时,master分支是7.2版本的plugin:
https://github.com/NVIDIA/TensorRT/tree/master/plugin
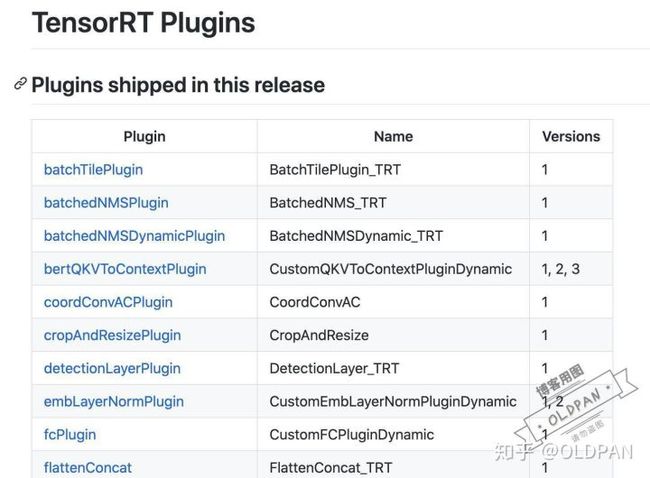
官方提供的插件已经相当多,而且TensorRT开源了plugin部分(可以让我们白嫖!)。并且可以看到其源码,通过模仿源码来学习plugin是如何写的。
如果要添加自己的算子,可以在官方的plugin库里头进行修改添加,然后编译官方的plugin库。将生成的libnvinfer_plugin.so.7替换原本的.so文件即可。或者自己写一个类似于官方plugin的组件,将名称替换一下,同样生成.so,在TensorRT的推理项目中引用这个动态链接库即可。
以下介绍中,我们需要写的IPlugin简称为插件op。
开始写插件
有兴趣的可以先看看TensorRT的官方文档,官方文档的介绍简单意骇,不过坑是少不了的..而本文的目的,就是尽量让你少趟坑。
首先按照官方plugin的排布方式,下面随便挑了个官方plugin:
准备一个自己的插件:custom.cpp和custom.h,copy并paste官方代码,名字替换成自己的。以最新的IPluginV2DynamicExt类为接口。
我们需要写两个类:
MyCustomPlugin,继承IPluginV2DynamicExt,是插件类,用于写插件具体的实现MyCustomPluginCreator,继承BaseCreator,是插件工厂类,用于根据需求创建该插件
对了,插件类继承IPluginV2DynamicExt才可以支持动态尺寸,其他插件类接口例如IPluginV2IOExt和前者大部分是相似的。
// 继承IPluginV2DynamicExt就够啦
class MyCustomPlugin final : public nvinfer1::IPluginV2DynamicExt
class MyCustomPluginCreator : public BaseCreator
MyCustomPlugin 插件类
总览:
class MyCustomPlugin final : public nvinfer1::IPluginV2DynamicExt
{
public:
MyCustomPlugin( int in_channel,
const std::vector& weight,
const std::vector& bias);
MyCustomPlugin( int in_channel,
nvinfer1::Weights const& weight,
nvinfer1::Weights const& bias);
MyCustomPlugin(void const* serialData, size_t serialLength);
MyCustomPlugin() = delete;
~MyCustomPlugin() override;
int getNbOutputs() const override;
DimsExprs getOutputDimensions(int outputIndex, const nvinfer1::DimsExprs* inputs, int nbInputs, nvinfer1::IExprBuilder& exprBuilder) override;
int initialize() override;
void terminate() override;
size_t getWorkspaceSize(const nvinfer1::PluginTensorDesc* inputs, int nbInputs, const nvinfer1::PluginTensorDesc* outputs, int nbOutputs) const override;
int enqueue(const nvinfer1::PluginTensorDesc* inputDesc, const nvinfer1::PluginTensorDesc* outputDesc,
const void* const* inputs, void* const* outputs,
void* workspace,
cudaStream_t stream) override;
size_t getSerializationSize() const override;
void serialize(void* buffer) const override;
bool supportsFormatCombination(int pos, const nvinfer1::PluginTensorDesc* inOut, int nbInputs, int nbOutputs) override;
const char* getPluginType() const override;
const char* getPluginVersion() const override;
void destroy() override;
nvinfer1::IPluginV2DynamicExt* clone() const override;
void setPluginNamespace(const char* pluginNamespace) override;
const char* getPluginNamespace() const override;
DataType getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const override;
void attachToContext(cudnnContext* cudnn, cublasContext* cublas, nvinfer1::IGpuAllocator* allocator) override;
void detachFromContext() override;
void configurePlugin(const nvinfer1::DynamicPluginTensorDesc* in, int nbInputs,
const nvinfer1::DynamicPluginTensorDesc* out, int nbOutputs) override;
private:
int _in_channel;
std::vector weight;
std::vector bias;
float* weight;
float* bias;
bool _initialized;
const char* mPluginNamespace;
std::string mNamespace;
};
成员变量
如果你的插件有weights(类似于conv操作的weight和bias),有参数(类似于conv中的kernel-size、padding),在类中则需要定义为成员变量,为private类型:
以MyCustomPlugin为例,假设我们的这个MyCustomPlugin有两个权重weight和bias以及一个参数in_channel(这个权重和参数没有啥意义,纯粹,纯粹为了演示):
private:
int _in_channel; // 参数
std::vector _weight; // 权重,在cpu空间存放
std::vector _bias; // 偏置权重,在cpu空间存放
float* _d_weight; // 权重,在GPU空间存放
float* _d_bias;
bool _initialized;
cudnnHandle_t _cudnn_handle;
const char* mPluginNamespace;
std::string mNamespace;
构造函数和析构函数
构造函数一般设置为三个。
第一个用于在parse阶段,PluginCreator用于创建该插件时调用的构造函数,需要传递权重信息以及参数。
第二个用于在clone阶段,复制这个plugin时会用到的构造函数。
第三个用于在deserialize阶段,用于将序列化好的权重和参数传入该plugin并创建爱你哦。
以我们的MyCustomPlugin为例:
MyCustomPlugin(int in_channel, nvinfer1::Weights const& weight, nvinfer1::Weights const& bias);
MyCustomPlugin(float in_channel, const std::vector& weight, const std::vector& bias);
MyCustomPlugin(void const* serialData, size_t serialLength);
析构函数则需要执行terminate,terminate函数就是释放这个op之前开辟的一些显存空间:
MyCustomPlugin::~MyCustomPlugin()
{
terminate();
}
注意需要把默认构造函数删掉:
MyCustomPlugin() = delete;
getNbOutputs
插件op返回多少个Tensor,比如MyCustomPlugin这个操作只输出一个Tensor(也就是一个output),所以直接return 1:
// MyCustomPlugin returns one output.
int MyCustomPlugin::getNbOutputs() const
{
return 1;
}
initialize
初始化函数,在这个插件准备开始run之前执行。
主要初始化一些提前开辟空间的参数,一般是一些cuda操作需要的参数(例如conv操作需要执行卷积操作,我们就需要提前开辟weight和bias的显存),假如我们的算子需要这些参数,则在这里需要提前开辟显存。
需要注意的是,如果插件算子需要开辟比较大的显存空间,不建议自己去申请显存空间,可以使用Tensorrt官方接口传过来的workspace指针来获取显存空间。因为如果这个插件被一个网络调用了很多次,而这个插件op需要开辟很多显存空间,那么TensorRT在构建network的时候会根据这个插件被调用的次数开辟很多显存,很容易导致显存溢出。
getOutputDataType
返回结果的类型,一般来说我们插件op返回结果类型与输入类型一致:
nvinfer1::DataType InstanceNormalizationPlugin::getOutputDataType(
int index, const nvinfer1::DataType* inputTypes, int nbInputs) const
{
ASSERT(inputTypes && nbInputs > 0 && index == 0);
return inputTypes[0];
}
getWorkspaceSize
这个函数需要返回这个插件op需要中间显存变量的实际数据大小(bytesize),这个是通过TensorRT的接口去获取,是比较规范的方式。
我们需要在这里确定这个op需要多大的显存空间去运行,在实际运行的时候就可以直接使用TensorRT开辟好的空间而不是自己去申请显存空间。
size_t MyCustomPlugin::getWorkspaceSize(const nvinfer1::PluginTensorDesc* inputs, int nbInputs, const nvinfer1::PluginTensorDesc* outputs, int nbOutputs) const
{
// 计算这个op前向过程中你认为需要的中间显存数量
size_t need_num;
return need_num * sizeof(float);
}
enqueue
实际插件op的执行函数,我们自己实现的cuda操作就放到这里(当然C++写的op也可以放进来,不过因为是CPU执行,速度就比较慢了),与往常一样接受输入inputs产生输出outputs,传给相应的指针就可以。
int enqueue(const nvinfer1::PluginTensorDesc* inputDesc, const nvinfer1::PluginTensorDesc* outputDesc,
const void* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream){
// 假如这个fun是你需要的中间变量 这里可以直接用TensorRT为你开辟的显存空间
fun = static_cast(workspace);
}
需要注意的是,如果我们的操作需要一些分布在显存中的中间变量,可以通过传过来的指针参数workspace获取,上述代码简单说明了一下使用方法。
再多说一句,我们默认写的.cu是fp32的,TensorRT在fp16运行模式下,运行到不支持fp16的插件op时,会自动切换到fp32模式,等插件op运行完再切换回来。
getOutputDimensions
TensorRT支持Dynamic-shape的时候,batch这一维度必须是explicit的,也就是说,TensorRT处理的维度从以往的三维[3,-1,-1]变成了[1,3,-1,-1]。最新的onnx-tensorrt也必须设置explicit的batchsize,而且这个batch维度在getOutputDimensions中是可以获取到的。
在旧版的IPluginV2类中,getOutputDimensions的定义如下:
virtual Dims getOutputDimensions(int index, const Dims* inputs, int nbInputDims) TRTNOEXCEPT = 0;
而在新版的IPluginV2DynamicExt类中定义如下:
virtual DimsExprs getOutputDimensions(int outputIndex, const DimsExprs* inputs, int nbInputs, IExprBuilder& exprBuilder) = 0;
我们要做的就是在这个成员函数中根据输入维度推理出模型的输出维度,需要注意的是,虽然说输出维度 是由输入维度决定,但这个输出维度其实“内定”的(也就是在计算之前就算出来了)。如果咱的插件op的输出维度需要通过实际运行计算得到,那么这个函数就无法满足咱了。
set/getPluginNamespace
为这个插件设置namespace名字,如果不设置则默认是"",需要注意的是同一个namespace下的plugin如果名字相同会冲突。
PluginFieldCollection
这个是成员变量,也会作为getFieldNames成员函数的返回类型。PluginFieldCollection的主要作用是传递这个插件op所需要的权重和参数,在实际的engine推理过程中并不使用,而在parse中会用到(例如caffe2trt、onnx2trt)。
当使用这些parse去解析这个op的时候,这个op的权重和参数会经历Models --> TensorRT engine --> TensorRT runtime这个过程。
举个例子,在onnx-tensorrt中,我们用过DEFINE_BUILTIN_OP_IMPORTER去注册op,然后通过parse解析onnx模型,根据注册好的op去一个个解析构建模型,假如我们定义的op为my_custom_op,在DEFINE_BUILTIN_OP_IMPORTER(my_custom_op)会这样实现:
DEFINE_BUILTIN_OP_IMPORTER(mycustom_op)
{
ASSERT(inputs.at(0).is_tensor(), ErrorCode::kUNSUPPORTED_NODE);
...
const std::string pluginName = "CUSTOM-OP";
const std::string pluginVersion = "001";
// 这个f保存这个op需要的权重和参数,从onnx模型中获取
std::vector f;
f.emplace_back("in_channel", &in_channel, nvinfer1::PluginFieldType::kINT32, 1);
f.emplace_back("weight", kernel_weights.values, nvinfer1::PluginFieldType::kFLOAT32, kernel_weights.count());
f.emplace_back("bias", bias_weights.values, nvinfer1::PluginFieldType::kFLOAT32, bias_weights.count);
// 这个从将plugin工厂中获取该插件,并且将权重和参数传递进去
nvinfer1::IPluginV2* plugin = importPluginFromRegistry(ctx, pluginName, pluginVersion, node.name(), f);
RETURN_FIRST_OUTPUT(ctx->network()->addPluginV2(tensors.data(), tensors.size(), *plugin));
}
进入importPluginFromRegistry函数内部,可以发现参数通过fc变量通过createPlugin传递给了plugin:
nvinfer1::IPluginV2* importPluginFromRegistry(IImporterContext* ctx, const std::string& pluginName,
const std::string& pluginVersion, const std::string& nodeName,
const std::vector& pluginFields)
{
const auto mPluginRegistry = getPluginRegistry();
const auto pluginCreator
= mPluginRegistry->getPluginCreator(pluginName.c_str(), pluginVersion.c_str(), "ONNXTRT_NAMESPACE");
if (!pluginCreator)
{
return nullptr;
}
// 接受传进来的权重和参数信息 传递给plugin
nvinfer1::PluginFieldCollection fc;
fc.nbFields = pluginFields.size();
fc.fields = pluginFields.data();
return pluginCreator->createPlugin(nodeName.c_str(), &fc);
}
上述步骤中,会提供pluginName和pluginVersion初始化MyCustomPluginCreator,其中createPlugin成员函数是我们需要编写的(下文会说)。
configurePlugin
配置这个插件op,判断输入和输出类型数量是否正确。官方还提到通过这个配置信息可以告知TensorRT去选择合适的算法(algorithm)去调优这个模型。
但自动调优目前还没有尝试过,我们一般自己写的plugin执行代码都是定死的,所谓的调优步骤可能更多地针对官方的op。
下面的plugin中configurePlugin函数仅仅是简单地确认了下输入和输出以及类型。
void MyCustomPluginDynamic::configurePlugin(
const nvinfer1::DynamicPluginTensorDesc *inputs, int nbInputs,
const nvinfer1::DynamicPluginTensorDesc *outputs, int nbOutputs) {
// Validate input arguments
assert(nbOutputs == 1);
assert(nbInputs == 2);
assert(mType == inputs[0].desc.type);
}
clone
这玩意儿干嘛的,顾名思义,就是克隆嘛,将这个plugin对象克隆一份给TensorRT的builder、network或者engine。这个成员函数会调用上述说到的第二个构造函数:
MyCustomPlugin(float in_channel, const std::vector& weight, const std::vector& bias);
将要克隆的plugin的权重和参数传递给这个构造函数。
IPluginV2DynamicExt* MyCustomPlugin::clone() const
{
//
auto plugin = new MyCustomPlugin{_in_channel, _weight, _bias};
plugin->setPluginNamespace(mPluginNamespace);
return plugin;
}
clone成员函数主要用于传递不变的权重和参数,将plugin复制n多份,从而可以被不同engine或者builder或者network使用。
getSerializationSize
返回序列化时需要写多少字节到buffer中。
size_t MyCustomPlugin::getSerializationSize() const
{
return (serialized_size(_in_channel) +
serialized_size(_weight) +
serialized_size(_bias)
);
}
supportsFormatCombination
TensorRT调用此方法以判断pos索引的输入/输出是否支持inOut[pos].format和inOut[pos].type指定的格式/数据类型。
如果插件支持inOut[pos]处的格式/数据类型,则返回true。 如果是否支持取决于其他的输入/输出格式/数据类型,则插件可以使其结果取决于inOut[0..pos-1]中的格式/数据类型,该格式/数据类型将设置为插件支持的值。 这个函数不需要检查inOut[pos + 1..nbInputs + nbOutputs-1],pos的决定必须仅基于inOut[0..pos]。
bool MyCustomPlugin::supportsFormatCombination(
int pos, const nvinfer1::PluginTensorDesc* inOut, int nbInputs, int nbOutputs)
{
// 假设有一个输入一个输出
assert(0 <= pos && pos < 2);
const auto *in = inOut;
const auto *out = inOut + nbInputs;
switch (pos) {
case 0:
return in[0].type == DataType::kFLOAT &&
in[0].format == nvinfer1::TensorFormat::kLINEAR;
case 1:
return out[0].type == in[0].type &&
out[0].format == nvinfer1::TensorFormat::kLINEAR;
}
}
serialize
把需要用的数据按照顺序序列化到buffer里头。
void MyCustomPlugin::serialize(void *buffer) const
{
serialize_value(&buffer, _in_channel);
serialize_value(&buffer, _weight);
serialize_value(&buffer, _bias);
}
attachToContext
如果这个op使用到了一些其他东西,例如cublas handle,可以直接借助TensorRT内部提供的cublas handle:
void MyCustomPlugin::attachToContext(cudnnContext* cudnnContext, cublasContext* cublasContext, IGpuAllocator* gpuAllocator)
{
mCublas = cublasContext;
}
MyCustomPluginCreator 插件工厂类
总览:
class MyCustomPluginCreator : public BaseCreator
{
public:
MyCustomPluginCreator();
~MyCustomPluginCreator() override = default;
const char* getPluginName() const override; // 不介绍
const char* getPluginVersion() const override; // 不介绍
const PluginFieldCollection* getFieldNames() override; // 不介绍
IPluginV2DynamicExt* createPlugin(const char* name, const nvinfer1::PluginFieldCollection* fc) override;
IPluginV2DynamicExt* deserializePlugin(const char* name, const void* serialData, size_t serialLength) override;
private:
static PluginFieldCollection mFC;
static std::vector mPluginAttributes;
std::string mNamespace;
};
构造函数
创建一个空的mPluginAttributes初始化mFC。
MyCustomPluginCreator::MyCustomPluginCreator()
{
mPluginAttributes.emplace_back(PluginField("in_channel", nullptr, PluginFieldType::kFLOAT32, 1));
mPluginAttributes.emplace_back(PluginField("weight", nullptr, PluginFieldType::kFLOAT32, 1));
mPluginAttributes.emplace_back(PluginField("bias", nullptr, PluginFieldType::kFLOAT32, 1));
mFC.nbFields = mPluginAttributes.size();
mFC.fields = mPluginAttributes.data();
}
createPlugin
这个成员函数作用是通过PluginFieldCollection去创建plugin,将op需要的权重和参数一个一个取出来,然后调用上文提到的第一个构造函数:
MyCustomPlugin(int in_channel, nvinfer1::Weights const& weight, nvinfer1::Weights const& bias);
去创建plugin。
MyCustomPlugin示例:
IPluginV2DynamicExt* MyCustomPlugin::createPlugin(const char* name, const nvinfer1::PluginFieldCollection* fc)
{
int in_channel;
std::vector weight;
std::vector bias;
const PluginField* fields = fc->fields;
for (int i = 0; i < fc->nbFields; ++i)
{
const char* attrName = fields[i].name;
if (!strcmp(attrName, "in_channel"))
{
ASSERT(fields[i].type == PluginFieldType::kINT32);
in_channel= *(static_cast(fields[i].data));
}
else if (!strcmp(attrName, "weight"))
{
ASSERT(fields[i].type == PluginFieldType::kFLOAT32);
int size = fields[i].length;
h_weight.reserve(size);
const auto* w = static_cast(fields[i].data);
for (int j = 0; j < size; j++)
{
h_weight.push_back(*w);
w++;
}
}
else if (!strcmp(attrName, "bias"))
{
ASSERT(fields[i].type == PluginFieldType::kFLOAT32);
int size = fields[i].length;
h_bias.reserve(size);
const auto* w = static_cast(fields[i].data);
for (int j = 0; j < size; j++)
{
h_bias.push_back(*w);
w++;
}
}
}
Weights weightWeights{DataType::kFLOAT, weight.data(), (int64_t) weight.size()};
Weights biasWeights{DataType::kFLOAT, bias.data(), (int64_t)_bias.size()};
MyCustomPlugin* obj = new MyCustomPlugin(in_channel, weightWeights, biasWeights);
obj->setPluginNamespace(mNamespace.c_str());
return obj;
}
deserializePlugin
这个函数会被onnx-tensorrt的一个叫做TRT_PluginV2的转换op调用,这个op会读取onnx模型的data数据将其反序列化到network中。
一些官方插件的注意事项
使用官方插件会遇到些小问题。
topk问题
官方的topk插件最多支持k<=3840。否则会报:
[TensorRT] ERROR: Parameter check failed at: ../builder/Layers.cpp::TopKLayer::3137, condition: k > 0 && k <= MAX_TOPK_K
相关问题:https://github.com/tensorflow/tensorflow/issues/31671
batchednms问题
官方的batchednms最大支持的topk为4096,太大也会崩溃。不过可以修改源代码实现突破这个数值,但仍然有bug:
void (*kernel[])(const int, const int, const int, const int, const float,
const bool, const bool, float *, T_SCORE *, int *,
T_SCORE *, int *, bool) = {
P(1), P(2), P(3), P(4), P(5), P(6), P(7), P(8), P(9), P(10),
P(11), P(12), P(13), P(14), P(15), P(16)
};
关于plugin的注册
简单说下plugin的注册流程。
在加载NvInferRuntimeCommon.h头文件的时候会得到一个getPluginRegistry,这里类中包含了所有已经注册了的IPluginCreator,在使用的时候我们通过getPluginCreator函数得到相应的IPluginCreator。
注册插件有两种方式,第一种可以看官方的plugin代码。
extern "C" {
bool initLibNvInferPlugins(void* logger, const char* libNamespace)
{
initializePlugin(logger, libNamespace);
initializePlugin(logger, libNamespace);
initializePlugin(logger, libNamespace);
...
return true;
}
其中initializePlugin函数执行了addPluginCreator函数:
template
void initializePlugin(void* logger, const char* libNamespace)
{
PluginCreatorRegistry::getInstance().addPluginCreator(logger, libNamespace);
}
addPluginCreator函数又执行了getPluginRegistry()->registerCreator对pluginCreator进行了注册,这样就完成注册任务了:
void addPluginCreator(void* logger, const char* libNamespace)
{
...
if (mRegistryList.find(pluginType) == mRegistryList.end())
{
bool status = getPluginRegistry()->registerCreator(*pluginCreator, libNamespace);
if (status)
{
mRegistry.push(std::move(pluginCreator));
mRegistryList.insert(pluginType);
verboseMsg = "Plugin creator registration succeeded - " + pluginType;
}
else
{
errorMsg = "Could not register plugin creator: " + pluginType;
}
}
else
{
verboseMsg = "Plugin creator already registered - " + pluginType;
}
...
}
另一种注册可以直接通过REGISTER_TENSORRT_PLUGIN来注册:
//!
//! \brief Return the plugin registry
//!
// 在加载`NvInferRuntimeCommon.h`头文件的时候会得到一个`getPluginRegistry`
extern "C" TENSORRTAPI nvinfer1::IPluginRegistry* getPluginRegistry();
namespace nvinfer1
{
template
class PluginRegistrar
{
public:
PluginRegistrar() { getPluginRegistry()->registerCreator(instance, ""); }
private:
T instance{};
};
#define REGISTER_TENSORRT_PLUGIN(name) \
static nvinfer1::PluginRegistrar pluginRegistrar##name {}
} // namespace nvinfer1
也就是说,如果我们已经在plugin的.h文件中执行了REGISTER_TENSORRT_PLUGIN(BatchedNMSPluginCreator);就不需要再创建一个类似于官方的initLibNvInferPlugins()函数去一个一个注册了。
看到这里了,希望对大家有所帮助,觉得有收获的大爷们点个赞呀。
参考链接
https://github.com/NVIDIA/TensorRT/tree/release/7.0/plugin https://github.com/triton-inference-server/server/issues/767 https://blog.csdn.net/u010552731/article/details/106520241 https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#work_dynamic_shapes https://forums.developer.nvidia.com/t/tensorrt-5-1-6-custom-plugin-with-fp16-issue/84132/4 https://forums.developer.nvidia.com/t/tensorrt-cask-error-in-checkcaskexecerror-false-7-cask-convolution-execution/109735 https://github.com/NVIDIA/TensorRT/tree/release/7.0/samples/opensource/samplePlugin https://forums.developer.nvidia.com