数据挖掘实验——python实现朴素贝叶斯分类
朴素贝叶斯分类实验
一.实验目的
1.了解朴素贝叶斯算法基本原理;
2.能够使用朴素贝叶斯算法对数据进行分类
二.实验内容
利用贝叶斯算法或者决策树算法进行数据分类操作 数据集:汽车评估数据集
关于朴素贝叶斯原理和案例可以看西瓜书详解:https://zhuanlan.zhihu.com/p/79527876
数据集:
import pandas as pd
data = pd.read_csv("car.csv")
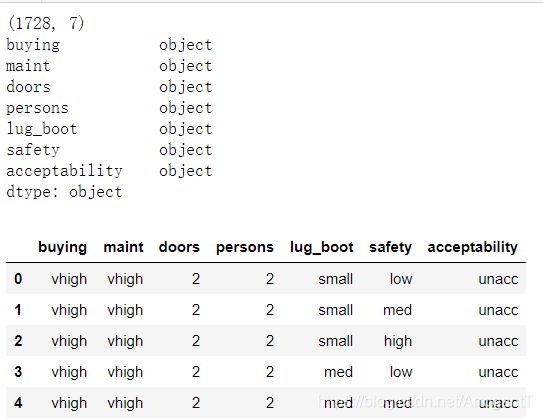
print(data.shape) #行数列数
print(data.dtypes) #所有列的数据类型
data.head()
# 输出各列的唯一值
m=[]
for i in data:
m.append(list(set(data[i].values.tolist())))
print(list(set(data[i].values.tolist())))

# 标注字典
Dict01={'low':1,'med':2,'high':3, 'vhigh':4}
Dict2={'2':0, '3':1, '4':2, '5more':3}
Dict3={'2':0, '4':1,'more':2}
Dict4={'small':0,'med':1, 'big':2}
Dict5={'low':0,'med':1,'high':2}
Dict6={'unacc':0, 'acc':1, 'good':2, 'vgood':3}
L=[Dict01,Dict01,Dict2,Dict3,Dict4,Dict5,Dict6]
# 获取列名
columns=data.columns.tolist()
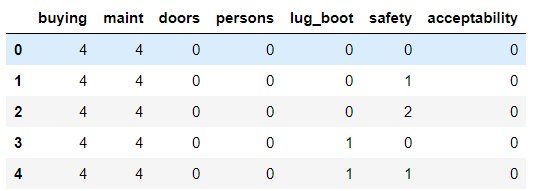
# 数据标注
for i in range(len(columns)):
data[columns[i]] = data[columns[i]].map(L[i])
data.head()
加上预测完整代码:
import pandas as pd
data = pd.read_csv("car.csv")
# 标注字典
Dict01={'low':1,'med':2,'high':3, 'vhigh':4}
Dict2={'2':0, '3':1, '4':2, '5more':3}
Dict3={'2':0, '4':1,'more':2}
Dict4={'small':0,'med':1, 'big':2}
Dict5={'low':0,'med':1,'high':2}
Dict6={'unacc':0, 'acc':1, 'good':2, 'vgood':3}
L=[Dict01,Dict01,Dict2,Dict3,Dict4,Dict5,Dict6]
# 获取列名
columns=data.columns.tolist()
# 数据标注
for i in range(len(columns)):
data[columns[i]] = data[columns[i]].map(L[i])
# 预测
predict=[1,0,2,1,1,0]
# 返回类别标签
labels=['unacc','acc','good','vgood']
classes = list(set(data.iloc[:,-1].tolist()))
result=[]
for i in range(len(classes)):
test_result=[]
test_data1=data[data['acceptability']==classes[i]]
P1=test_data1.shape[0]/data.shape[0]
print("原数据集第"+str(i)+"类的概率:",P1)
for j in range(len(predict)):
test_data2=test_data1[test_data1[columns[j]]==predict[j]]
if test_data2.shape[0]==0:
P2=1
else:
P2 = test_data2.shape[0]/test_data1.shape[0]
print("在第"+str(i)+"类的条件下"+"X"+str(j)+"的概率:",P2)
test_result.append(P2)
print(test_result)
multiply = 1.0
for k in test_result:
multiply *=k
pro = multiply/P1
print("属于第"+str(i)+"类的概率:",pro)
result.append(pro)
print("\n")
print("属于各类的概率:",result)
max_index = result.index(max(result,key = abs))
print("测试结果:属于"+labels[max_index]+"\t概率为:"+str(result[max_index]))
预测结果:
