【深度学习】Transformer、Self-Attention (注意力) 原理解读
【参考:transformer的细节到底是怎么样的? - 知乎】待看
【参考:The Illustrated Transformer 可视化理解Transformer结构 - 知乎】 极其清晰,浅显易懂,必看
代码 http://nlp.seas.harvard.edu/2018/04/03/attention.html
【参考:Attention机制详解(二)——Self-Attention与Transformer - 知乎】QKV的计算过程
【参考:熬了一晚上,我从零实现了Transformer模型,把代码讲给你听 - 知乎】代码待回顾
【参考:超详细图解Self-Attention - 知乎】 必读 浅显易懂
公式解读
词向量之间相关度高表示什么?是不是在一定程度上(不是完全)表示,在关注词A的时候,应当给予词B更多的关注?
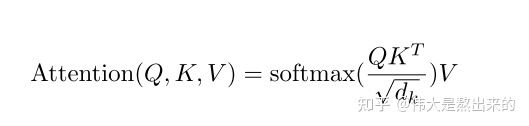
【参考:Transformer - Attention is all you need 论文解读- 知乎】浅显易懂
self-attention计算句子中的每个词都和其他词的关联,从而帮助模型更好地理解上下文语义
计算self-attention的分数值,该分数值决定了当我们在某个位置encode一个词时,对输入句子的其他部分的关注程度

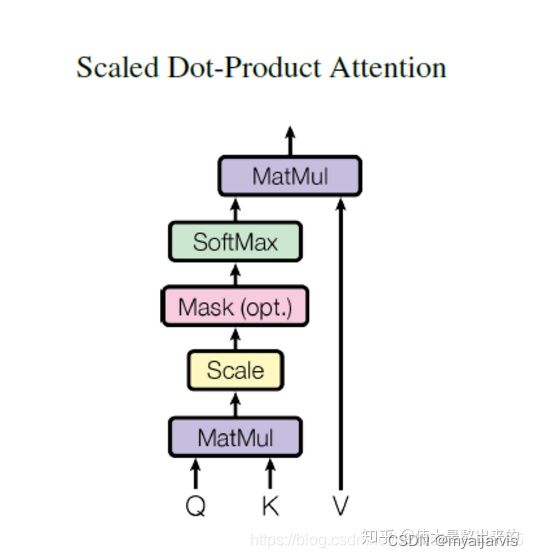
【参考:[深度学习] 自然语言处理 — Self-Attention 基本介绍_魔都Vincent的博客-CSDN博客】
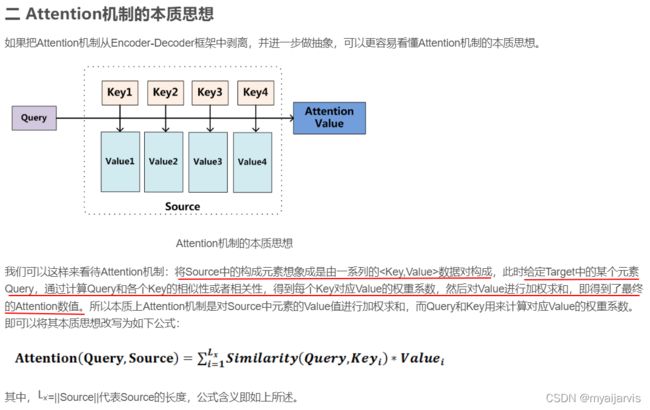
Q,K,V
【参考:深度学习attention机制中的Q,K,V分别是从哪来的? - 知乎】
https://www.zhihu.com/question/325839123/answer/1903376265 评论区
解释地太清楚啦。我画蛇添足地做个比喻帮助理解:
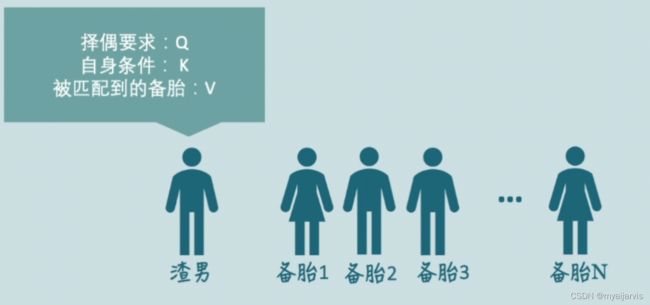
假如一个男生B,面对许多个潜在交往对象B1,B2,B3…,他想知道自己谁跟自己最匹配,应该把最多的注意力放在哪一个上。那么他需要这么做:
1、他要把自己的实际条件用某种方法表示出来,这就是Value;
2、他要定一个自己期望对象的标准,就是Query;
3、别人也有期望对象标准的,他要给出一个供别人参考的数据,当然不能直接用自己真实的条件,总要包装一下,这就是Key;
4、他用自己的标准去跟每一个人的Key比对一下(Q*K),当然也可以跟自己比对,然后用softmax求出权重,就知道自己的注意力应该放在谁身上了,有可能是自己哦
从零解读…transformer模型
【参考:汉语自然语言处理-从零解读碾压循环神经网络的transformer模型- 注意力机制-位置编码-attention is all you need_哔哩哔哩_bilibili】 讲得非常好


【参考:a_journey_into_math_of_ml/transformer_1.ipynb at master · aespresso/a_journey_into_math_of_ml】

Transformer使我快乐 - bilibili
【参考:在线激情讲解transformer&Attention注意力机制(上)_哔哩哔哩_bilibili】
【参考:Transformer使我快乐(下)_哔哩哔哩_bilibili】
Q:为什么需要在求权重矩阵的时候要除以 根号 d k \sqrt{d_k} dk ?
A:在我们的两个向量维度非常大的时候,点乘结果的方差也会很大,也就是结果中的元素的差距很大,在点乘非常大的时候,softmax的梯度会趋近与0,也就是梯度消失。???
在原文中有提到,假设q和k的元素是相互独立的,维度为 d k d_k dk的随机变量,
他们的平均值为0,方差为1,那么q和k点乘的平均值为0,方差为 d k d_k dk。如果将点乘的结果进行缩放操作,也就是除以 根号 d k d_k dk,就能有效的控制方差从 d k d_k dk回到1,也就是有效控制梯度消失的问题。

对于任意相对距离k, P E ( p o s + k ) PE_{(pos+k)} PE(pos+k)都可以用 P E ( p o s ) PE_{(pos)} PE(pos)的线性函数表示。
所以两个位置的点乘能够反映他们的相对距离,从而对注意力的计算产生影响。
Transformer简明教程 - bilibili
【参考:Transformer简明教程, 从理论到代码实现到项目实战, NLP进阶必知必会._哔哩哔哩_bilibili】
只有一组Q,K,V的是单头注意力,有多组的是多头注意力
Q,K,V怎么来的?
词向量编码分别与 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV相乘得到的

Transformer的PyTorch实现_bilibili ***
【参考:Transformer的PyTorch实现_哔哩哔哩_bilibili】
【参考:Transformer详解(看不懂你来骂我)_数学家是我理想的博客-CSDN博客】
【参考:Transformer详解 - matho_ 数学家是我理想】例子丰富,动画生动
实现有点难,待定
Transformer从零详细解读_bilibili
【参考:Transformer从零详细解读_哔哩哔哩_bilibili】

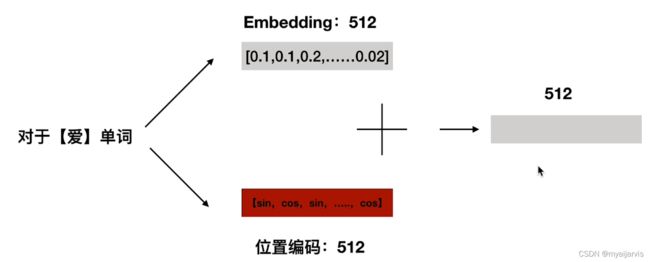


query查询序列,key待查序列,value自身含义编码序列
残差网络
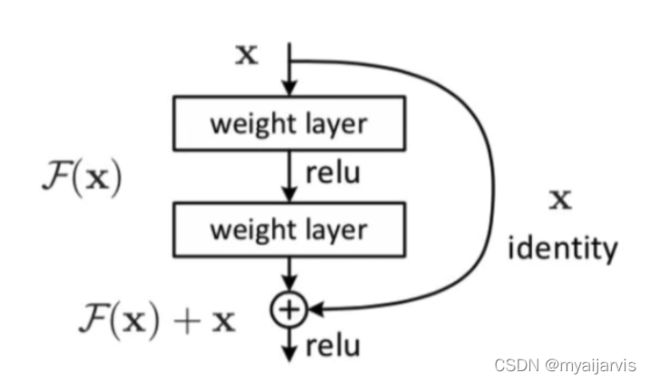
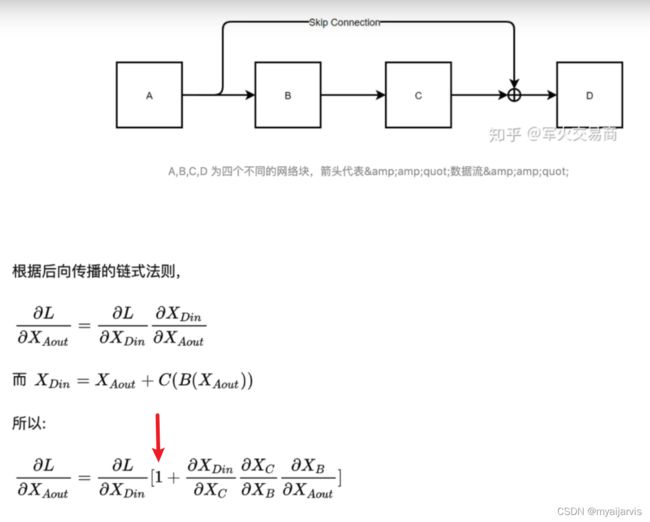
【参考:5.Batch Normal详解_哔哩哔哩_bilibili】
【参考:6.layer normal 详解——哔哩哔哩_bilibili】
为啥不用BN而使用LN 讲得非常好