目标检测(Object Detection)
目标检测基本概念+Yolo介绍
原文地址:https://www.yuque.com/huoxiangshouxiangwanghuo/xg3nah/giwl7l
目标检测(Object Detection)
在计算机视觉众多的技术领域中,目标检测(Object Detection)也是一项非常基础的任务,图像分割、物体追踪、关键点检测等通常都要依赖于目标检测。
在目标检测时,由于每张图像中物体的数量、大小及姿态各有不同,也就是非结构化的输出,这是与图像分类非常不同的一点,并且物体时常会有遮挡截断,所以物体检测技术也极富挑战性,从诞生以来始终是研究学者最为关注的焦点领域之一。
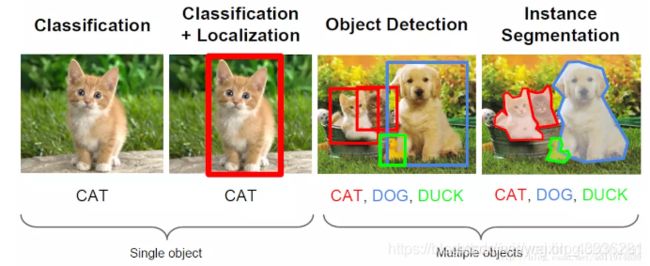
在计算机视觉中,图像分类、目标检测和图像分割都属于最基础、也是目前发展最为迅速的3个领域,我们可以看一下这几个任务之间的区别。
- 图像分类:输入图像往往仅包含一个物体,目的是判断每张图像是什么物体,是图像级别的任务,相对简单,发展也最快。
- 目标检测:输入图像中往往有很多物体,目的是判断出物体出现的位置与类别,是计算机视觉中非常核心的一个任务。 ·
- 图像分割:输入与物体检测类似,但是要判断出每一个像素属于哪一个类别,属于像素级的分类。图像分割与物体检测任务之间有很多联系,模型也可以相互借鉴。
目标检测发展历程
在利用深度学习做物体检测之前,传统算法对于目标检测通常分为3个阶段:区域选取、特征提取和体征分类。

- 区域选取:首先选取图像中可能出现物体的位置,由于物体位置、大小都不固定,因此传统算法通常使用滑动窗口(Sliding Windows)算法,但这种算法会存在大量的冗余框,并且计算复杂度高。

- 特征提取:在得到物体位置后,通常使用人工精心设计的提取器进行特征提取,如SIFT和HOG等。由于提取器包含的参数较少,并且人工设计的鲁棒性较低,因此特征提取的质量并不高。
- 特征分类:最后,对上一步得到的特征进行分类,通常使用如SVM、AdaBoost的分类器。
深度学习火了之后,神经网络的大量参数可以提取出鲁棒性和语义性更好的特征,并且分类器性能也更优越,从此便拉开了深度学习做目标检测的序幕。

目标检测基本概念
目标检测技术,通常是指在一张图像中检测出物体出现的位置及对应的类比,我们要求检测器输出5个value:物体类别class、bounding box左上角x坐标x、bounding box左上角y坐标y、bounding box右下角x坐标x、bounding box右下角y坐标y。
边界框(Bounding Box)
检测任务需要同时预测物体的类别和位置。类别好说,就是一个数字,比如我们可以用1代表dog,2代表bicycle,3代表truck。物体的位置通常使用边界框(Bounding Box)来表示,边界框是一个正好能包含物体的矩形框,可以由矩形左上角的x和y轴坐标与右下角的x和y轴坐标确定。图片坐标的原点在左上角,x轴向右为正方向,y轴向下为正方向。
一般来说这些数据在我们训练的时候都会提供好,比如我们可以看一下VOC数据集中的第一个标注文件:
<annotation>
<folder>VOC2012folder>
<filename>2007_000027.jpgfilename>
<source>
<database>The VOC2007 Databasedatabase>
<annotation>PASCAL VOC2007annotation>
<image>flickrimage>
source>
<size>
<width>486width>
<height>500height>
<depth>3depth>
size>
<segmented>0segmented>
<object>
<name>personname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>174xmin>
<ymin>101ymin>
<xmax>349xmax>
<ymax>351ymax>
bndbox>
<part>
<name>headname>
<bndbox>
<xmin>169xmin>
<ymin>104ymin>
<xmax>209xmax>
<ymax>146ymax>
bndbox>
part>
<part>
<name>handname>
<bndbox>
<xmin>278xmin>
<ymin>210ymin>
<xmax>297xmax>
<ymax>233ymax>
bndbox>
part>
<part>
<name>footname>
<bndbox>
<xmin>273xmin>
<ymin>333ymin>
<xmax>297xmax>
<ymax>354ymax>
bndbox>
part>
<part>
<name>footname>
<bndbox>
<xmin>319xmin>
<ymin>307ymin>
<xmax>340xmax>
<ymax>326ymax>
bndbox>
part>
object>
annotation>
它对应的图像如下所示:

我们可以通过编写一个函数来将读取的标注文件中bounding box的坐标绘制到image上,这样我们就能更加清晰的看出标注文件和image之间的关联了。
def plotBox(x, img, color=None, label=None, line_thickness=None):
# Plots one bounding box on image img
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
image = transforms.functional.to_pil_image(inputs)
width = int(targets["annotation"]["size"]["width"])
height = int(targets["annotation"]["size"]["height"])
image = image.resize((width, height))
image = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
for obj in targets["annotation"]["object"]:
bndbox = obj["bndbox"]
x0, y0, x1, y1 = bndbox["xmin"], bndbox["ymin"], bndbox["xmax"], bndbox["ymax"]
plotBox([x0, y0, x1, y1], image, label=obj["name"])
plt.imshow(image)
plt.show()
通常有三种格式来表示bounding box的位置:
- xyxy,即(_x_1, _y_1, _x_2, _y_2),其中(_x_1, _y_1)是bounding box左上角的坐标,(_x_2,_y_2)是bounding box右下角的坐标;
- xywh,即(x, y, w, h),其中(x, y)是bounding box左上角的坐标,w是矩形框的宽度,h是矩形框的高度;
- cxcywh,即(c_x_, c_y_, w, h),其中(x, y)是bounding box中心点的坐标,w是矩形框的宽度,h是矩形框的高度。
在检测任务中,训练数据集的标签里会给出目标物体真实边界框所对应的(_x_1,_y_1,_x_2,_y_2),这样的边界框也被称为真实框(ground truth box),我们训练出的模型会对目标物体可能出现的位置进行预测,由模型预测出的边界框则称为预测框(prediction box)。
要完成一项检测任务,我们通常希望模型能够根据输入的图片,输出一些预测的边界框,以及边界框中所包含的物体的类别或者说属于某个类别的概率,例如这种格式: [L, P, _x_1, _y_1, _x_2, _y_2],其中_L_是类别标签,_P_是物体属于该类别的概率。一张输入图片可能会产生多个预测框,我们就根据预测出的prediction box和ground truth box计算损失值来定义损失函数。
锚框(Anchor Box)
Anchor Box是学习目标检测过程中最重要且最难理解的一个概念。这个概念最初是在Faster R-CNN中提出,此后在SSD、YOLOv2、YOLOv3等优秀的目标识别模型中得到了广泛的应用。

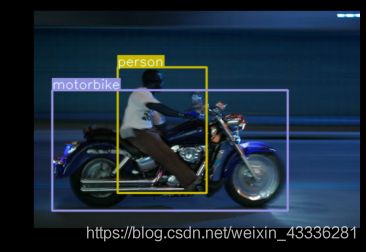
为什么提出 Anchor Box ?以往的模型一个窗口只能预测一个目标,把窗口输入到分类网络中,最终得到一个预测概率,这个概率偏向哪个类别则把窗口内的目标预测为相应的类别,例如在图中回归得到的行人概率更大,则认为这个目标为人。
那么,anchor到底是什么呢?如果我们用一句话概括——就是在图像上预设好的不同大小,不同长宽比的参照框。

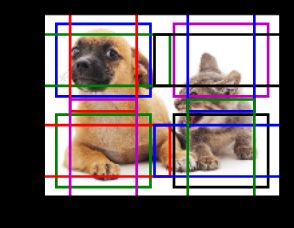
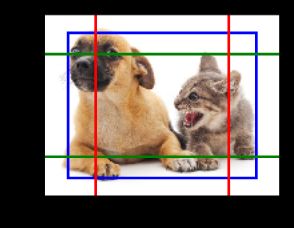
Anchor Box跟传统目标检测中使用的“Sliding Windows”差不多,只不过并不是固定死的,在输入图像中采样的时候,每个黑色方框代表图像特征提取过程中某个特征图上的特征,以每一个box为中心生成多个大小和宽高比不同的bounding box,这些边界框就是Anchor Box。
对于不同的任务,需要检测的目标也是不同的,相应Anchor的选取大小也是不一样的,比如对于自动驾驶任务中,需要检测车辆,Anchor的大小就可以选取的大一些,而对于昆虫检测任务,Anchor的大小就得选取的小一些。所以Anchor的大小是非常重要的,我们可以在训练前通过在训练集中使用K-Means聚类算法来得到适合训练集的Anchor。
评价指标
对于一个检测器,我们需要指定一定的规则来评价其好坏。目标检测模型的输出是非结构化的,事先无法得知输出物体的数量、位置、大小等,因此目标检测的评价算法就稍微复杂一些。
IoU
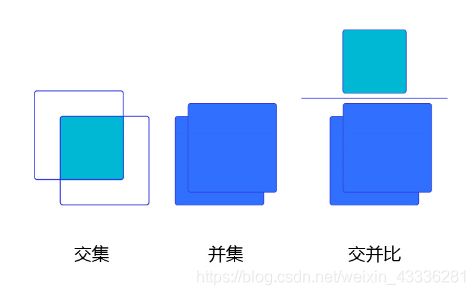
对于具体的某个事物来讲,我们可以从prediction box与ground truth box的贴合程度来判断检测的质量,通常使用IoU(Intersection of Union)来量化贴合程度,作为衡量指标。
IoU的概念来源于数学中的集合,用来描述两个集合A和B之间的关系,它等于两个集合的交集里面所包含的元素个数除以并集里面所包含的元素个数,具体的计算公式: I o U = A ∩ B A ∪ B I o U=\frac{A \cap B}{A \cup B} IoU=A∪BA∩B。
我们将用这个概念来描述两个框之间的重合度。两个框可以看成是两个像素的集合,它们的IoU等于两个框重合部分的面积除以它们合并起来的面积。下图“交集”中青色区域是两个框的重合面积,图“并集”中蓝色区域是两个框的相并面积,用这两个面积相除即可得到它们之间的IoU。
假设两个矩形框A和B的位置分别为: A : [ x a 1 , y a 1 , x a 2 , y a 2 ] B : [ x b 1 , y b 1 , x b 2 , y b 2 ] \begin{array}{l} A:\left[x_{a 1}, y_{a 1}, x_{a 2}, y_{a 2}\right] \\ B:\left[x_{b 1}, y_{b 1}, x_{b 2}, y_{b 2}\right] \end{array} A:[xa1,ya1,xa2,ya2]B:[xb1,yb1,xb2,yb2]
位置关系如 图 所示:

如果二者有相交部分,则相交部分左上角坐标为: x 1 = max ( x a 1 , x b 1 ) , y 1 = max ( y a 1 , y b 1 ) x_{1}=\max \left(x_{a 1}, x_{b 1}\right), \quad y_{1}=\max \left(y_{a1}, y_{b 1}\right) x1=max(xa1,xb1),y1=max(ya1,yb1)
相交部分右下角坐标为: x 2 = min ( x a 2 , x b 2 ) , y 2 = min ( y a 2 , y b 2 ) x_{2}=\min \left(x_{a2}, x_{b2}\right), \quad y_{2}=\min \left(y_{a2}, y_{b2}\right) x2=min(xa2,xb2),y2=min(ya2,yb2)
计算先交部分面积: intersection = max ( x 2 − x 1 , 0 ) ⋅ max ( y 2 − y 1 , 0 ) \text { intersection }=\max \left(x_{2}-x_{1},0\right) \cdot \max \left(y_{2}-y_{1},0\right) intersection =max(x2−x1,0)⋅max(y2−y1,0)
矩形框A和B的面积分别是: S A = ( x a 2 − x a 1 ) ⋅ ( y a 2 − y a 1 ) S B = ( x b 2 − x b 1 ) ⋅ ( y b 2 − y b 1 ) \begin{array}{l} S_{A}=\left(x_{a2}-x_{a1}\right) \cdot\left(y_{a2}-y_{a1}\right) \\ S_{B}=\left(x_{b2}-x_{b1}\right) \cdot\left(y_{b2}-y_{b1}\right) \end{array} SA=(xa2−xa1)⋅(ya2−ya1)SB=(xb2−xb1)⋅(yb2−yb1)
计算相并部分面积: union = S A + S B − intersection \text { union }=S_{A}+S_{B}-\text { intersection } union =SA+SB− intersection
计算IoU: I o U = intersection union I o U=\frac{\text { intersection }}{\text { union }} IoU= union intersection
def iou(box1, box2):
"""
计算两个 box 的 IoU,box 的坐标形式为 xyxy
"""
x1, y1 = max(box1[0], box2[0]), max(box1[1], box2[1])
x2, y2 = max(box1[2], box2[2]), max(box1[3], box2[3])
intersection = max(x2 - x1, 0) * max(y2 - y1, 0)
s1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
s2 = (box2[2] - box2[0]) * (box2[3] - box2[1])
union = s1 + s2 - intersection
return intersection / union
bbox1 = [100, 100, 200, 200]
bbox2 = [120, 120, 200, 200]
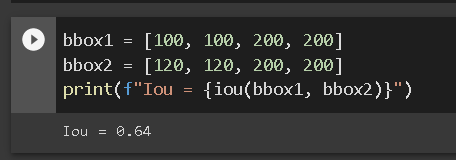
print(f"Iou = {iou(bbox1, bbox2)}")
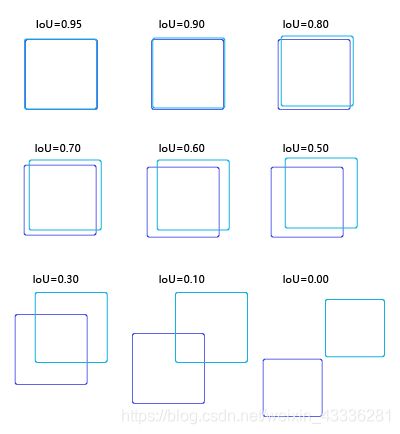
为了直观的展示交并比的大小跟重合程度之间的关系,下图示意了不同交并比下两个框之间的相对位置关系,从 IoU = 0.95 到 IoU = 0。
对于IoU而言,我们通常会选取一个阈值,比如0.5,来确定prediction box是正确的还是错误的,当两个框的IoU大于0.5时,我们认为prediction box才是一个有效的检测,否则属于无效的匹配。
mAP
对于一个检测器,通常使用mAP(mean Average Precision)这一指标来评价一个模型的好坏,AP指的是一个类别的检测精度,mAP则是多个类别的平均精度。
评测需要每张图片的prediction和target,对于某一个实例,我们首先将所有的prediction box按照得分从高到底进行排序(因为得分越高的box对于ground truth的概率往往越大),然后从高到低遍历prediction box。
对于遍历中的某一个prediction box,计算其与该图中同一类别的所有ground truth box的IoU,并选取拥有最大IoU的ground truth作为当前prediction box的匹配对象,如果该IoU小于阈值,则将当前prediction box标记为误检框。
如果IoU大于阈值,还要看对应的ground truth box是否被访问过,如果前面已经有得分更高的prediction box与该ground truth对应了,即使现在的IoU大于阈值,也会被标记为误检框,如果没有被访问过,则将当前prediction box标记为正检框,并将该ground truth box标记为访问过,以防止后面还有prediction box与其对应。在遍历完所有的prediction box之后,我们会得到每一个prediction box的属性,即正检框和误检框。

遍历过程中,我们可以通过当前正检框的数量来计算模型的召回率(Recall),即当前一共检测出的ground truth与所有ground truth的比值。除了召回率,还有一个重要指标是准确率(Precision),即当前遍历过的预测框中,属于正检框的比值。
遍历到每一个prediction box的时候,都可以生成一个对应的Precision和Recall,这两个值可以组成一个点(P,R),将所有的点绘制成曲线,就形成了P-R曲线。

即使有了P-R曲线,评价模型仍然不直观,如果直接取曲线上的点,在哪里取都不合适,因为一般Recall高的时候Precision会很低,Precision高的时候往往Recall又很低。这时,我们直接使用积分的方式来计算P-R曲线与坐标轴围成的面积: A P = ∫ 0 1 P ( r ) d r A P=\int_{0}^{1} P(r) d r AP=∫01P(r)dr 来综合考量不同召回率下的准确率,不会对Precision和Recall有任何偏好。每个类别的AP是相互独立的,将每个类别的AP进行平均,就得到了mAP。
非极大值抑制(Non-Maximum-Suppression,NMS)
在模型预测阶段,我们先为图像生成多个锚框,并为这些锚框一一预测类别和偏移量。随后,我们根据锚框及其预测偏移量得到预测边界框。当锚框数量较多时,同一个目标上可能会输出较多相似的预测边界框。为了使结果更加简洁,我们可以移除相似的预测边界框。常用的方法叫作非极大值抑制(non-maximum suppression,NMS)。
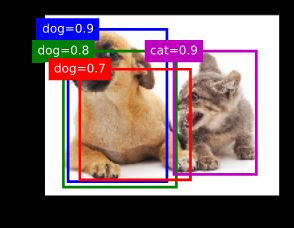
我们来描述一下非极大值抑制的工作原理。对于一个预测边界框B,模型会计算各个类别的预测概率。设其中最大的预测概率为p,该概率所对应的类别即B的预测类别。我们也将p称为预测边界框B的置信度。在同一图像上,我们将预测类别非背景的预测边界框按置信度从高到低排序,得到列表L。从L中选取置信度最高的预测边界框B1作为基准,将所有与B1的交并比大于某阈值的非基准预测边界框从L中移除。这里的阈值是预先设定的超参数。此时,L保留了置信度最高的预测边界框并移除了与其相似的其他预测边界框。 接下来,从L中选取置信度第二高的预测边界框B2作为基准,将所有与B2的交并比大于某阈值的非基准预测边界框从L中移除。重复这一过程,直到L中所有的预测边界框都曾作为基准。此时L中任意一对预测边界框的交并比都小于阈值。最终,输出列表L中的所有预测边界框。
YOLO(You Only Look Once)
You only look once(YOLO)意思是只需要浏览一次就可以识别出图中的物体的类别和位置,是一种先进的实时目标检测系统,在2016年被提出,发表在计算机视觉顶会CVPR(Computer Vision and Pattern Recognition)上,我们可以看一下YOLO可以达到什么样的效果。
原理
在开始真正coding之前,我们先了解一下YOLO的原理,我们的目的是在一张图片中找出物体,并给出它的类别和位置。目标检测是基于监督学习的,每张图片的监督信息是它所包含的N个物体,每个物体的信息有五个,分别是物体的中心位置(x,y)和它的高(h)和宽(w),最后是它的类别。
YOLO 的预测是基于整个图片的,并且它会一次性输出所有检测到的目标信息,包括类别和位置。先假设我们处理的图片是一个正方形。YOLO的第一步是分割图片,它将图片分割为 S2 个grid,每个grid的大小都是相等的,像这样:

如果物体的中心点落在某个box内,那么这个box就负责预测这个物体。具体怎么实现呢?我们要让这个 个框每个都预测出B个bounding boxs,这个bounding boxs有5个量,分别是物体的中心位置(x,y)和它的高(h)和宽(w),以及这次预测的置信度,表示这个bounding box有多大把握保证当前grid有物体。每个框框不仅只预测B个bounding boxs,它还要负责预测这个框框中的物体是什么类别的,这里的类别用one-hot编码表示,也就是说,如果我们有 个框框,每个框框的bounding boxes个数为B,分类器可以识别出C种不同的物体,那么整个image的prediction为:。

在上面的例子中,图片被分成了49个框,每个框预测2个bounding boxs,因此上面的图中有98个bounding boxs。可以看到大致上每个框里确实有两个bounding boxs。可以看到这些BOX中有的边框比较粗,有的比较细,这是置信度不同的表现,置信度高的比较粗,置信度低的比较细。
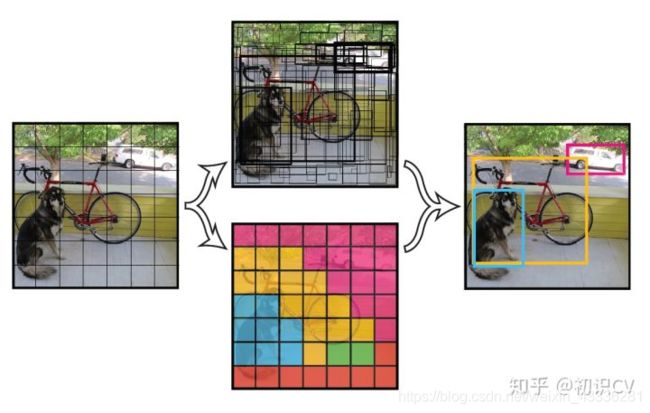
网络虽然预测出来那么多bounding box,但实际的标注文件中只有三个:狗、自行车、小汽车,其它地方都是背景。对于整个image得到的所有bounding box来说,要删除大部分,首先,在背景部分的bounding box要删除,本来这里就没有物体你算出来的也不对;其次,置信度低于阈值的要删除,我们会设置置信度阈值超参数,如果某box的置信度低于阈值我们也不考虑;最后,还会通过非极大值抑制(NMS)删除几乎重叠的bounding box,对于NMS的阈值也会设置一个超参数。
网络模型

Yolo-V1的特征提取层借助于训练好的图像分类神经网络——GoogLeNet,这个网络先在ImageNet数据集上进行1000类分类训练,再迁移到当前标注数据集上训练,可以在不同级别的卷积神经网络中提取不同尺寸目标的信息。一般来说,图像分类神经网络前几层的神经网络代表的是局域的特征,因此可以获取尺寸比较小的物体的信息;中间几层则可以获取中等尺寸物体的信息;最后几层则可以获取大尺寸物体的信息。每个特征提取层提取得到的特征会分别送入目标选框的回归层和分类层,其中回归层负责根据输入的特征预测目标选框在图像中的位置,分类层则根据输入的特征预测目标选框代表了物体种类。
损失函数
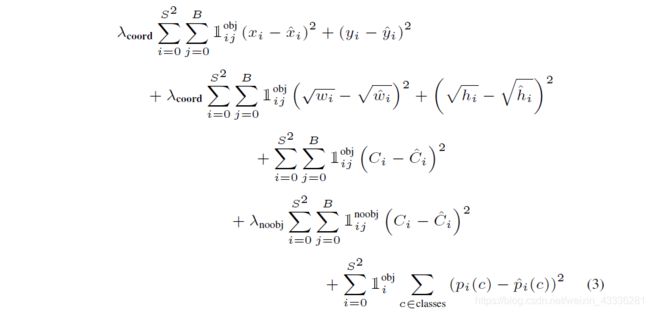
这是Yolo-V1的损失函数,相比于V2和V3版本好理解一些,我们基于它来分析一下。损失函数分为三个部分:位置大小损失,confidence损失和类别损失,计算损失的大题思路是,用预测值与真实值的差的平方求和,三部分损失加权求和得到总损失。
位置损失
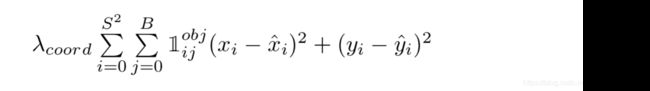
对一张图片,我们只关注负责检测标注物体的那个bbox,计算它与标注的ground truth的(x, y, w, h)值差异。
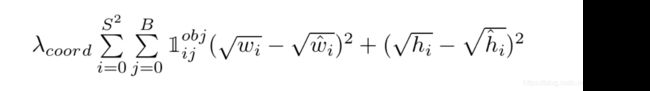
这里计算w和h时开了根号的原因在于,bbox与ground truth在w h上的相同差异,对大框的影响应该小于小框,因此不应该等同看待。比如我们有bbox1和truth1,二者的宽度分别为200和150;另外还有bbox2和truth2,二者的宽度分别为20和15。我们应该让bbox2的损失更大一些,因为按照比例来说它偏差的比较多,但是直接相减的做法会让它们的损失相同,而取根号再相减可以达到这个效果。
置信度损失
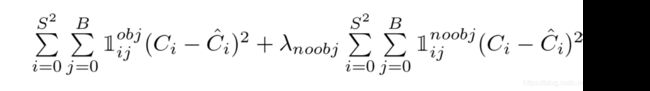
confidence用于判断这个bbox中是否含有待标注物体,因此对含有的bbox要进行惩罚,对不含有的bbox也要进行惩罚。confidence的预测值就是我们算出来的c了,而confidence的真实值是需要计算的。
对于那些不负责物体的bbox,confidence的真实值是0;对于那些负责物体的bbox,confidence的真实值是1。
分类损失
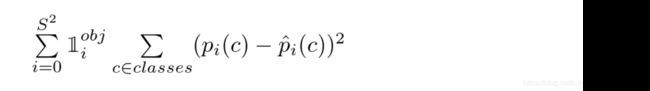
因为YOLOv1中是每个cell只能预测一种类别(而不是每个bbox),所以我们只要考虑负责物体的cell的类别损失。直接使用条件概率值作为预测的类别值,因为负责即表示有物体;对于真实值,则在真实类别上值为1,错误类别上值为0。