研发中遇到的问题总结
Python、Pytorch、AI算法开发过程中遇到的一些问题及其解决方法
(自备的,以便后面遇到同样问题时查阅,如果对你没有帮助,请勿喷)
▶dtype="
▶Pycharm提示:cannot find reference ‘***’ in (input:(any,```),kwargs:dict) -> any’,但是可以正常跑?

这个问题困扰了我很久很久,在网上找了很多方法都没有用,包括什么设置快捷键忽略此提示,在设置的某个框框里去掉‘__ init __.py’等等方法,无一解决。IDE也重装过还是不行,最后终于解决:方法就是卸载Pycharm,清理pycharm在系统中的所有文件和记录,包括注册表之类的跟pycharm有关的全部清理干净,再重装Pycharm,问题解决。
▶卷积参数量、计算量
参数量:(+1为偏置项)
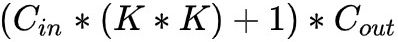
计算量:
不考虑输入输出通道:
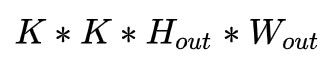
考虑输入输出通道:
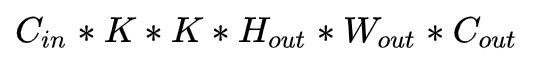
▶ 求完损失以后在进行反向传播 loss.backward()时报一个类型错误:
loss = torch.nn.MSELoss()(out, torch.nn.functional.one_hot(target, 10).to(device))
self.opt.zero_grad()
loss.backward()
self.opt.step()
RuntimeError: expected dtype Float but got dtype Long
原因:one_hot函数返回的target数据类型为Long,可以与网络输出进行前向计算,但不能反向传播梯度更新
解决:将one_hot返回的标签转成Float类型,加“.float()”
loss = torch.nn.MSELoss()(out, torch.nn.functional.one_hot(target, 10.float().to(device))
说明:这个问题不只是在用onehot函数返回target时出现,用其他方式也会有类似的错误提示,这时就需要手动perint一下target.dtype看一下标签的数据类型了,一般网络输出的是tensor.float32,所以标签也应该是float32,否则就会造成可以计算loss,但是不能backward
▶ 网络一个batch的输出不是我们想用来计算的数据,我们希望将一轮(多个batch/多次输出)的结果拿来计算,但是,Tensor不能append,如果用cat,那初始化也是个难题,这时借助列表,将多次输出append到列表,再用torch.cat()将列表连接并转换成tensor数据。
a = []
b = torch.tensor([[11, 12, 13],
[14, 15, 16]])
c = torch.tensor([[21, 22, 23],
[24, 25, 26],
[27, 28, 29]])
a.append(b)
a.append(c)
print(a)
>> [ tensor([[11, 12, 13],
[14, 15, 16]]),
tensor([[21, 22, 23],
[24, 25, 26],
[27, 28, 29]])]
a = torch.cat(a, dim=0)
print(a)
>> tensor([[11, 12, 13],
[14, 15, 16],
[21, 22, 23],
[24, 25, 26],
[27, 28, 29]])
▶ CNN中Conv2d的padding方式
padding=(1, 1)时,上下左右填充;
padding=(1, 0)时,上下填充;
padding=(0, 1)时,左右填充;
▶ Pycharm中run控制台的可显示长度、显示精度、取消科学计数法……
在运行python时,有时候明明可以一行显示完的他非要给你显示为两行,看起来让人有点难受
设置前的显示效果:
Arc_out: tensor([0.1034, 0.1001, 0.1054, 0.1033, 0.0972, 0.0981, 0.1001, 0.0981, 0.0971,
0.0973])
Net_out: tensor([9.7265e-10, 8.8703e-33, 1.0000e+00, 1.1067e-09, 0.0000e+00, 0.0000e+00,
3.1043e-33, 0.0000e+00, 0.0000e+00, 0.0000e+00])
设置后的效果:
Arc_out: tensor([0.1034, 0.1001, 0.1054, 0.1033, 0.0972, 0.0981, 0.1001, 0.0981, 0.0971, 0.0973])
Net_out: tensor([0.0000, 0.0000, 1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000])
是不是舒服点了?
设置方式:
用torch.set_printoptions()方法,
import torch
torch.set_printoptions(sci_mode=False, linewidth=200)
顺便看下该方法的原型
def set_printoptions(
precision=None, # 精度,小数位数
threshold=None, #
edgeitems=None, # 省略到每个二维和一维显示多少条数据
linewidth=None, # 每一行可显示多少个字符
profile=None, #
sci_mode=None # 科学计数法
):
r"""Set options for printing. Items shamelessly taken from NumPy
Args:
precision: Number of digits of precision for floating point output
(default = 4).
threshold: Total number of array elements which trigger summarization
rather than full `repr` (default = 1000).
edgeitems: Number of array items in summary at beginning and end of
each dimension (default = 3).
linewidth: The number of characters per line for the purpose of
inserting line breaks (default = 80). Thresholded matrices will
ignore this parameter.
profile: Sane defaults for pretty printing. Can override with any of
the above options. (any one of `default`, `short`, `full`)
sci_mode: Enable (True) or disable (False) scientific notation. If
None (default) is specified, the value is defined by `_Formatter`
"""
同样,numpy也有该方法可用,但参数有些大同小异
np.set_printoptions(precision=None, threshold=None, edgeitems=None,
linewidth=None, suppress=None, nanstr=None, infstr=None,
formatter=None, sign=None, floatmode=None, **kwarg):
"""
precision : 输出的精度,即小数点后位数
threshold : 当数组数目过大时,设置显示几个数字,其余用省略号
edgeitems: 每个维度开始和结束时摘要中的数组项数,
linewidth:一行要print多少个字符
suppress:是否采用科学计数法
infstr:无穷大的字符串表示
nanstr:浮点非数字的字符串表示
"""
▶损失为Nan、nan;loss为nan
梯度爆炸
解决:输入加BN、换激活函数、梯度截断、dropout、减小BacthSize、L2正则化等等
注意:一旦出现Nan,那么网络的权重将全部不可用,整个网络都将报废,如果在出现之后没做保存,那还可以加载之前保存的来继续训练,一旦执行了保存,那么保存的权重也会是nan,只得考虑重新训练了。
▶过拟合、发现与解决
解释:“在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据”,这是百度百科的解释。通俗的讲就是模型学的太较真了,抬杠,举个栗子:训练数据里面的螃蟹都是八跪而二螯,在测试或使用的时候,输入的螃蟹是八条腿两只钳模型能认识,但输入的图片中螃蟹少了一条或多条腿,模型就判定不是螃蟹。这就是一种过拟合现象。
解决:(1)增大增强数据集;(2)dropout:按比例随机屏蔽掉一些神经元;(3)L1、L2正则化:L1会使某些神经元死掉,权重为0,L2根据神经元权重对损失的影响因子进行权重抑制,不会为0。
▶二范数、欧氏距离、向量求模
torch.dist(a, b) # 求ab向量的模、距离、范数
▶二维向量按某列排序用lambda匿名函数
a = torch.tensor([[1, 2, 1],
[1, 2, 3],
[1, 2, 2]])
a = sorted(a, key=lambda x: x[2]) # x为枚举的a中的每个元素,x[2]为a中每个元素的下标[2]元素
print(a)
执行结果:
[[1, 2, 1],
[1, 2, 2],
[1, 2, 3]]
▶RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
在将输入数据送入到网络模型的时候,报错:
RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
原因:
这个错误提示并没有说是什么原因,也没说什么问题,因为数据在GPU(cuda)上,所以提示与普通错误提示不太一样,将数据放回到 CPU 上重新运行代码,可以看到一个更加清楚地错误描述,其根本问题是数据类型不匹配,模型期望的是一个 Float 类型的数据,而我们传入的是另一个数据类型。
解决:
OK,问题找到了,把数据转成float再计算就搞定了。
▶PIL和OpenCV互转
PIL >> CV2:
import cv2
from PIL import Image
import numpy
image = Image.open("plane.jpg")
image.show()
img = cv2.cvtColor(numpy.asarray(image),cv2.COLOR_RGB2BGR)
cv2.imshow("OpenCV",img)
cv2.waitKey()
CV2 >> PIL:
import cv2
from PIL import Image
import numpy
img = cv2.imread("plane.jpg")
cv2.imshow("OpenCV",img)
image = Image.fromarray(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))
image.show()
cv2.waitKey()
判断图像数据是否是OpenCV格式:
isinstance(img, np.ndarray)
▶python+openCV通道拆分(R、G、B)和合并
拆分
B,G,R = cv2.split(image)
合并
image = cv2.merge([B, G, R])
▶PIL的save命令保存下来的图片的质量问题
该save方法有一个参数叫quality, 默认的值为95,表示保存下来的图片质量会压缩到原来的95%,会存在一些噪点噪声之类的,所以在保存的时候尽量手动设置一下该参数为quality=100,这样保存下来的照片才不会白压缩。
▶ reduce failed to synchronize: cudaErrorAssert: device-side assert triggered
这个问题是由于GPU数据计算BCELoss出错导致的,如果转入CPU里计算的话错误提示为:
all elements of input should be between 0 and 1
可以看出是input超出0 ~ 1的范围了,因为BCELoss是0~1之间进行二分类,所以注意检查sigmoid的作用范围,检查BCELoss的输入是否符合0 ~1分布
▶Pytorch跑RNN、LSTM等结构时报:'UserWarning: RNN module weights are not part of single contiguous chunk of memory
使用DataParallel的情况下,RNN才会报这个提示。
这个并不是一个错误,只是一个警告,就是说RNN的权值并不是单一连续的,这些权值在每一次RNN被调用的时候都会被压缩,会很大程度上增加显存消耗。使用flatten_parameters()把权重存成连续的形式,可以提高内存利用率。
解决方案:在forward()里面加一句self.xxx.flatten_parameters()就可以解决了。
比如你有这样两层rnn:
def __init__(self):
super().__init__()
self.lstm1 = nn.LSTM(180, 512, 2, batch_first=True)
self.lstm2 = nn.LSTM(512, 128, 2, batch_first=True)
那你就在forward()里面加上:
def forward(self, x):
self.lstm1.flatten_parameters()
self.lstm2.flatten_parameters()
▶ValueError: Expected more than 1 value per channel when training, got input size torch.Size([1, 512]
这个问题,我看了博客上很多这个类似问题,引起的原因也不尽一样,
我的引起原因是在使用的时候没有将model置为eval状态,在模型初始化后加一句“model.eval()”就解决了。
▶MXNET警告提示(linux):
src/operator/nn/./cudnn/./cudnn_algoreg-inl.h:97: Running performance tests to find the bestconvolution algorithm, this can take a while… (setting env variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0to disable)
解决方法:跑代码之前,输入:
export MXNET_CUDNN_AUTOTUNE_DEFAULT = 0
▶解决 python-opencv打开或保存中文路径的问题
im=cv2.imdecode(np.fromfile('c:\\测试\\1.jpg',dtype=np.uint8),cv2.IMREAD_UNCHANGED)#打开含有中文路径的图片
cv2.imencode('.jpg',im)[1].tofile('C:\\测试\\你好.jpg')#保存图片
print(“end”)
▶Pycharm提示:cannot find reference ‘***’ in (input:(any,```),kwargs:dict) -> any’,但是可以正常跑?
这个问题困扰了我很久很久,在网上找了很多方法都没有用,包括什么设置快捷键忽略此提示,在设置的某个框框里去掉‘__ init __.py’等等方法,无一解决。IDE也重装过还是不行,最后终于解决:方法就是卸载Pycharm,清理pycharm在系统中的所有文件和记录,包括注册表之类的跟pycharm有关的全部清理干净,再重装Pycharm,问题解决。
▶卷积参数量、计算量
参数量:(+1为偏置项)
![]()
计算量:
不考虑输入输出通道:
考虑输入输出通道:
▶ 求完损失以后在进行反向传播 loss.backward()时报一个类型错误:
loss = torch.nn.MSELoss()(out, torch.nn.functional.one_hot(target, 10).to(device))
self.opt.zero_grad()
loss.backward()
self.opt.step()
RuntimeError: expected dtype Float but got dtype Long
原因:one_hot函数返回的target数据类型为Long,可以与网络输出进行前向计算,但不能反向传播梯度更新
解决:将one_hot返回的标签转成Float类型,加“.float()”
loss = torch.nn.MSELoss()(out, torch.nn.functional.one_hot(target, 10.float().to(device))
说明:这个问题不只是在用onehot函数返回target时出现,用其他方式也会有类似的错误提示,这时就需要手动perint一下target.dtype看一下标签的数据类型了,一般网络输出的是tensor.float32,所以标签也应该是float32,否则就会造成可以计算loss,但是不能backward
▶ 网络一个batch的输出不是我们想用来计算的数据,我们希望将一轮(多个batch/多次输出)的结果拿来计算,但是,Tensor不能append,如果用cat,那初始化也是个难题,这时借助列表,将多次输出append到列表,再用torch.cat()将列表连接并转换成tensor数据。
a = []
b = torch.tensor([[11, 12, 13],
[14, 15, 16]])
c = torch.tensor([[21, 22, 23],
[24, 25, 26],
[27, 28, 29]])
a.append(b)
a.append(c)
print(a)
>> [ tensor([[11, 12, 13],
[14, 15, 16]]),
tensor([[21, 22, 23],
[24, 25, 26],
[27, 28, 29]])]
a = torch.cat(a, dim=0)
print(a)
>> tensor([[11, 12, 13],
[14, 15, 16],
[21, 22, 23],
[24, 25, 26],
[27, 28, 29]])
▶ CNN中Conv2d的padding方式
padding=(1, 1)时,上下左右填充;
padding=(1, 0)时,上下填充;
padding=(0, 1)时,左右填充;
▶ Pycharm中run控制台的可显示长度、显示精度、取消科学计数法……
在运行python时,有时候明明可以一行显示完的他非要给你显示为两行,看起来让人有点难受
设置前的显示效果:
Arc_out: tensor([0.1034, 0.1001, 0.1054, 0.1033, 0.0972, 0.0981, 0.1001, 0.0981, 0.0971,
0.0973])
Net_out: tensor([9.7265e-10, 8.8703e-33, 1.0000e+00, 1.1067e-09, 0.0000e+00, 0.0000e+00,
3.1043e-33, 0.0000e+00, 0.0000e+00, 0.0000e+00])
设置后的效果:
Arc_out: tensor([0.1034, 0.1001, 0.1054, 0.1033, 0.0972, 0.0981, 0.1001, 0.0981, 0.0971, 0.0973])
Net_out: tensor([0.0000, 0.0000, 1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000])
是不是舒服点了?
设置方式:
用torch.set_printoptions()方法,
import torch
torch.set_printoptions(sci_mode=False, linewidth=200)
顺便看下该方法的原型
def set_printoptions(
precision=None, # 精度,小数位数
threshold=None, #
edgeitems=None, # 省略到每个二维和一维显示多少条数据
linewidth=None, # 每一行可显示多少个字符
profile=None, #
sci_mode=None # 科学计数法
):
r"""Set options for printing. Items shamelessly taken from NumPy
Args:
precision: Number of digits of precision for floating point output
(default = 4).
threshold: Total number of array elements which trigger summarization
rather than full `repr` (default = 1000).
edgeitems: Number of array items in summary at beginning and end of
each dimension (default = 3).
linewidth: The number of characters per line for the purpose of
inserting line breaks (default = 80). Thresholded matrices will
ignore this parameter.
profile: Sane defaults for pretty printing. Can override with any of
the above options. (any one of `default`, `short`, `full`)
sci_mode: Enable (True) or disable (False) scientific notation. If
None (default) is specified, the value is defined by `_Formatter`
"""
同样,numpy也有该方法可用,但参数有些大同小异
np.set_printoptions(precision=None, threshold=None, edgeitems=None,
linewidth=None, suppress=None, nanstr=None, infstr=None,
formatter=None, sign=None, floatmode=None, **kwarg):
"""
precision : 输出的精度,即小数点后位数
threshold : 当数组数目过大时,设置显示几个数字,其余用省略号
edgeitems: 每个维度开始和结束时摘要中的数组项数,
linewidth:一行要print多少个字符
suppress:是否采用科学计数法
infstr:无穷大的字符串表示
nanstr:浮点非数字的字符串表示
"""
▶损失为Nan、nan;loss为nan
梯度爆炸
解决:输入加BN、换激活函数、梯度截断、dropout、减小BacthSize、L2正则化等等
注意:一旦出现Nan,那么网络的权重将全部不可用,整个网络都将报废,如果在出现之后没做保存,那还可以加载之前保存的来继续训练,一旦执行了保存,那么保存的权重也会是nan,只得考虑重新训练了。
▶过拟合、发现与解决
解释:“在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据”,这是百度百科的解释。通俗的讲就是模型学的太较真了,抬杠,举个栗子:训练数据里面的螃蟹都是八跪而二螯,在测试或使用的时候,输入的螃蟹是八条腿两只钳模型能认识,但输入的图片中螃蟹少了一条或多条腿,模型就判定不是螃蟹。这就是一种过拟合现象。
解决:(1)增大增强数据集;(2)dropout:按比例随机屏蔽掉一些神经元;(3)L1、L2正则化:L1会使某些神经元死掉,权重为0,L2根据神经元权重对损失的影响因子进行权重抑制,不会为0。
▶二范数、欧氏距离、向量求模
torch.dist(a, b) # 求ab向量的模、距离、范数
▶二维向量按某列排序用lambda匿名函数
a = torch.tensor([[1, 2, 1],
[1, 2, 3],
[1, 2, 2]])
a = sorted(a, key=lambda x: x[2]) # x为枚举的a中的每个元素,x[2]为a中每个元素的下标[2]元素
print(a)
执行结果:
[[1, 2, 1],
[1, 2, 2],
[1, 2, 3]]
▶RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
在将输入数据送入到网络模型的时候,报错:
RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
原因:
这个错误提示并没有说是什么原因,也没说什么问题,因为数据在GPU(cuda)上,所以提示与普通错误提示不太一样,将数据放回到 CPU 上重新运行代码,可以看到一个更加清楚地错误描述,其根本问题是数据类型不匹配,模型期望的是一个 Float 类型的数据,而我们传入的是另一个数据类型。
解决:
OK,问题找到了,把数据转成float再计算就搞定了。
▶PIL和OpenCV互转
PIL >> CV2:
import cv2
from PIL import Image
import numpy
image = Image.open("plane.jpg")
image.show()
img = cv2.cvtColor(numpy.asarray(image),cv2.COLOR_RGB2BGR)
cv2.imshow("OpenCV",img)
cv2.waitKey()
CV2 >> PIL:
import cv2
from PIL import Image
import numpy
img = cv2.imread("plane.jpg")
cv2.imshow("OpenCV",img)
image = Image.fromarray(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))
image.show()
cv2.waitKey()
判断图像数据是否是OpenCV格式:
isinstance(img, np.ndarray)
▶python+openCV通道拆分(R、G、B)和合并
拆分
B,G,R = cv2.split(image)
合并
image = cv2.merge([B, G, R])
▶PIL的save命令保存下来的图片的质量问题
该save方法有一个参数叫quality, 默认的值为95,表示保存下来的图片质量会压缩到原来的95%,会存在一些噪点噪声之类的,所以在保存的时候尽量手动设置一下该参数为quality=100,这样保存下来的照片才不会白压缩。
▶ reduce failed to synchronize: cudaErrorAssert: device-side assert triggered
这个问题是由于GPU数据计算BCELoss出错导致的,如果转入CPU里计算的话错误提示为:
all elements of input should be between 0 and 1
可以看出是input超出0 ~ 1的范围了,因为BCELoss是0~1之间进行二分类,所以注意检查sigmoid的作用范围,检查BCELoss的输入是否符合0 ~1分布
▶Pytorch跑RNN、LSTM等结构时报:'UserWarning: RNN module weights are not part of single contiguous chunk of memory
使用DataParallel的情况下,RNN才会报这个提示。
这个并不是一个错误,只是一个警告,就是说RNN的权值并不是单一连续的,这些权值在每一次RNN被调用的时候都会被压缩,会很大程度上增加显存消耗。使用flatten_parameters()把权重存成连续的形式,可以提高内存利用率。
解决方案:在forward()里面加一句self.xxx.flatten_parameters()就可以解决了。
比如你有这样两层rnn:
def __init__(self):
super().__init__()
self.lstm1 = nn.LSTM(180, 512, 2, batch_first=True)
self.lstm2 = nn.LSTM(512, 128, 2, batch_first=True)
那你就在forward()里面加上:
def forward(self, x):
self.lstm1.flatten_parameters()
self.lstm2.flatten_parameters()
▶ValueError: Expected more than 1 value per channel when training, got input size torch.Size([1, 512]
这个问题,我看了博客上很多这个类似问题,引起的原因也不尽一样,
我的引起原因是在使用的时候没有将model置为eval状态,在模型初始化后加一句“model.eval()”就解决了。
▶MXNET警告提示(linux):
src/operator/nn/./cudnn/./cudnn_algoreg-inl.h:97: Running performance tests to find the bestconvolution algorithm, this can take a while… (setting env variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0to disable)
解决方法:跑代码之前,输入:
export MXNET_CUDNN_AUTOTUNE_DEFAULT = 0
▶解决 python-opencv打开或保存中文路径的问题
im=cv2.imdecode(np.fromfile('c:\\测试\\1.jpg',dtype=np.uint8),cv2.IMREAD_UNCHANGED)#打开含有中文路径的图片
cv2.imencode('.jpg',im)[1].tofile('C:\\测试\\你好.jpg')#保存图片
print(“end”)