位置偏差在马蜂窝推荐排序中的实践
 点击上方“马蜂窝技术”,关注订阅更多优质内容
点击上方“马蜂窝技术”,关注订阅更多优质内容

马蜂窝信息流推荐系统的目的是给用户推荐更好玩,更有用的内容攻略,该系统通过内容池、召回、排序、重排序几个过程,从海量内容中筛选出用户感兴趣的推荐给用户。
排序是推荐系统中的重要一环,马蜂窝使用基于CTR预估的排序模型,通过学习数据中的知识训练模型,再将内容推荐给用户,形成推荐闭环。

用户在浏览和详细查阅具体内容的时,因视觉注意力具有一定倾向性,即:注意力集中的地方普遍点击率会更高(参考图1b中,注意力热度图),使处于“好位置”的内容获得更多的曝光和点击。这些点击行为不能真实地反映出内容质量和用户喜好,从而会对基于CTR预估的推荐系统造成影响。
综上,位置偏差会给推荐系统带来以下两点问题:
1、用户的点击行为会受到展示位置的影响,处于“好位置”的内容点击率比较高
2、点击率高的内容会在推荐闭环中占据强势地位,挤压其他内容的生存空间
为此,本文将介绍马蜂窝推荐排序系统是如何降低位置偏差带来的影响的。


马蜂窝推荐排序模型是CTR预估模型,它的训练样本是所有用户的曝光点击历史。为了消除位置偏差,提高模型的预测准确率,我们可以在模型训练的时候,将位置信息作为训练特征之一。

由于展示位置是在模型排序之后,模型进行预测的时候,我们无法获得展示位置。这时候可以使用默认值来代替位置特征。默认值由离线测试的AUC和线上AB测试最终确定。由于模型训练和预测时的使用的特征不同,该方案线上表现一般:用户点击率降低 0.3%,用户人均点击篇数提升0.2%,内容曝光提升0.1%,内容点击率降低0.1%。



模型训练时同时训练ProbSeen和pCTR部分,线上预测的时候只使用pCTR部分。由于位置信息只作用在ProbSeen部分,线上预测的时候不需要知道位置信息。实际上线后,方案二收益不明显:用户点击率提升 0.9%,用户人均点击篇数降低0.7%,内容曝光提升1.0%,内容点击率降低0.3%。

逆倾向样本加权Inverse Propensity Weighting(IPW)被学术界广泛研究[3-11],IPW的核心思想在于,在得到每个样本的倾向性评分后,利用倾向性评分对样本重新加权。
本文中我们使用基于点击率的逆倾向样本加权,具体做法是:统计马蜂窝推荐场景下所有的曝光点击信息,计算不同展示位置处的平均点击率,结果如图5所示。我们使用平滑后的点击率作为倾向性评分,对训练样本进行加权。使用带权样本训练排序模型,并用于线上预测。实验前两天内容点击率相对提升约6%,后面逐渐下降,正负波动明显。
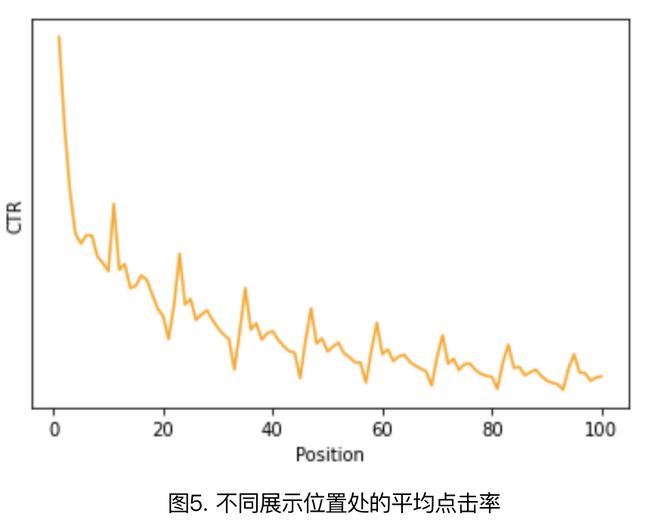
为什么方案3会先正后负?基于点击率的逆倾向样本加权忽略了一个前提,一篇内容展示位置靠前不单单是因为历史位置靠前,更重要的是因为其质量优秀及用户偏好,逆倾向加权打破位置马太效应的同时也压制了用户偏好及优质内容的展示,所以线上表现先正后负,并且一直波动。




在马蜂窝推荐场景下,不同位置对应的位置能力如表1所示:


我们将步骤二中计算出的位置能力分别应用于排序模型的训练特征部分和样本权重部分。
在训练特征部分,原来的特征中有很多点击率特征,我们对点击率特征重新处理,转换后的点击等于真实点击除以位置能力,转换后的点击率等于转换后的点击量除以曝光数量。

在样本权重部分,我们使用位置能力的倒数来代替原来的训练样本样本权重。
我们每天基于EM模型生成的新的位置能力,该位置能力作用于排序模型后,对线上提升明显:用户点击率提升 2.1%,用户人均点击篇数提升4.5%,内容曝光提升1.9%,内容点击率提升3.3%。

用户行为数据是推荐系统的水源,只有水源足够纯净才能让推荐系统持续健康,但用户行为数据中存在各式各样的偏差,如:曝光偏差、位置偏差、归纳偏差、流行度偏差等[12-14],这些偏差在推荐闭环中被加剧放大,影响推荐系统的准确性。针对这些偏差,后期我们将进行更多的深入研究,给用户带来更加准确的推荐结果。
本文作者:郭延琛、皇甫庆彬;智能中台-推荐平台研发工程师
参考文献
[1] SIGIR 2021 | 广告系统位置偏差的CTR模型优化方案
[2] Guo, Huifeng, et al. “PAL: a position-bias aware learning framework for CTR prediction in live recommender systems.” Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
[3] Wang, Xuanhui, et al. “Learning to rank with selection bias in personal search.” Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. 2016.
[4] Joachims, Thorsten, Adith Swaminathan, and Tobias Schnabel. “Unbiased learning-to-rank with biased feedback.” Proceedings of the Tenth ACM International Conference on Web Search and Data Mining. 2017.
[5] Ai, Qingyao, et al. “Unbiased learning to rank with unbiased propensity estimation.” The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.
[6] Wang, Xuanhui, et al. “Position bias estimation for unbiased learning to rank in personal search.” Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining. 2018.
[7] Agarwal, Aman, et al. “Estimating position bias without intrusive interventions.” Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining. 2019.
[8] Hu, Ziniu, et al. “Unbiased lambdamart: an unbiased pairwise learning-to-rank algorithm.” The World Wide Web Conference. 2019.
[9] Ovaisi, Zohreh, et al. “Correcting for selection bias in learning-to-rank systems.” Proceedings of The Web Conference 2020. 2020.
[10] Yuan, Bowen, et al. “Unbiased Ad click prediction for position-aware advertising systems.” Fourteenth ACM Conference on Recommender Systems. 2020.
[11] Qin, Zhen, et al. “Attribute-based propensity for unbiased learning in recommender systems: Algorithm and case studies.” Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[12] Chen, Jiawei, et al. “Bias and Debias in Recommender System: A Survey and Future Directions.” arXiv preprint arXiv:2010.03240 (2020).
[13] Cañamares, Rocío, and Pablo Castells. “Should I follow the crowd? A probabilistic analysis of the effectiveness of popularity in recommender systems.” The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.
[14] Morik, Marco, et al. “Controlling fairness and bias in dynamic learning-to-rank.” Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2020.
