Elasticsearch安装IK分词器,kibana安装是基本使用,DSL语句入门
文章目录
-
- 1. 安装IK分词器
- 2. Kibana安装和使用
-
- 2.1 ELK概述
- 2.2 Kibana下载
- 2.3 DSL语句
1. 安装IK分词器
ElasticSearch 默认采用的分词器, 是单个字分词 ,效果很差 ,所以我们需要安装一个更实用的分词器,这里采用 IK分词器
中文分词器 IK Analyzer 3.0 发布
jar包下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
源码下载地址:https://github.com/medcl/elasticsearch-analysis-ik/tree

这里选择使用 ZIP 格式下载

IK 分词器解压即可使用,打开ES的安装目录,然后打开 plugins 目录,建立一个文件夹(我这里取名为:elasticsearch-analysis-ik-6.6.2,为了区分别的插件),将ZIP文件解压在这个文件下就可以。

解压之后重启ES:

2. Kibana安装和使用
Kibana是一个针对Elasticsearch的开源分析及可视化平台,使用Kibana可以查询、查看并与存储在ES索引的数据进行交互操作,使用Kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据。
Kibana 是 ELK 的一个组成。
E:EalsticSearch,搜索和分析的功能
L:Logstach,搜集数据的功能,类似于flume(使用方法几乎跟flume一模一样),是日志收集系统1
K:Kibana,数据可视化(分析),可以用图表的方式来去展示,文不如表,表不如图,是数据可视化平台
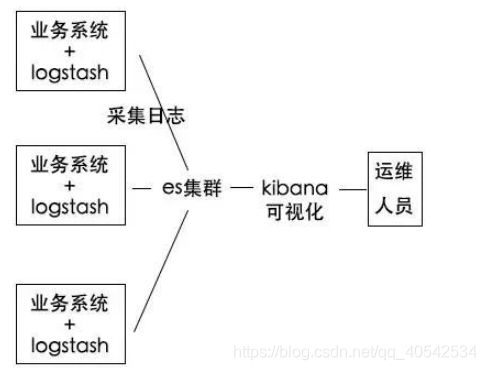
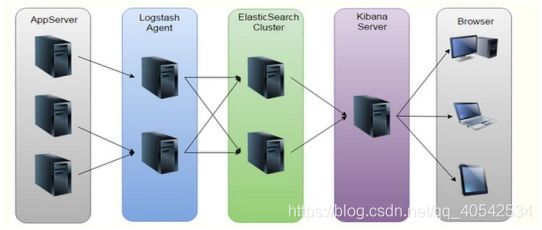
2.1 ELK概述
| ELK | 实现语言 | 简介 |
|---|---|---|
| ElasticSearch | Java | 实时的分布式搜索和分析引擎,可用于全文检索,结构化搜索以及分析,基层基于Lucene。类似于Solr |
| Logstash | JRuby | 具有实时渠道能力的数据收集引擎,包含输入、过滤、输出模块,一般在过滤模块中做日志格式化的解析工作 |
| Kibana | JavaScript | 为ElasticSerach提供分析平台和可视化的Web平台。他可以ElasticSerach的索引中查找,呼唤数据,并生成各种维度的表图 |
ELK的相关参考资料:
ELK官网:https://www.elastic.co/
ELK官网文档:https://www.elastic.co/guide
ELK中文手册:https://www.elastic.co/guide
ELK中文社区:https://elasticsearch.cn
2.2 Kibana下载
【注意】 Kibana 版本要和你安装的ES版本一致
最新版本下载地址:https://www.elastic.co/cn/downloads/kibana
其他版本下载地址:https://www.elastic.co/cn/downloads/past-releases
 选择对应你的电脑版本进行下载zip文件
选择对应你的电脑版本进行下载zip文件

下载好之后,解压:
![]()
解压之后,会有一个 kibana-版本号-系统-位的文件夹(kibana-6.6.2-windows-x86_64)
![]()
内部文件目录:

| 类型 | 描述 |
|---|---|
| home | Kibana home 目录就是解压之后的目录(kibana-6.6.2-windows-x86_64) |
| bin | 二进制脚本,包括 kibana 启动 Kibana 服务和 kibana-plugin 安装插件。 |
| config | 配置文件包括 kibana.yml 。 |
| data | Kibana 和其插件写入磁盘的数据文件位置。 |
| optimize | 编译过的源码。某些管理操作(如,插件安装)导致运行时重新编译源码。 |
| plugins | 插件文件位置。每一个插件都一个单独的二级目录。 |
启动Kibana,在bin目录下的 kibana.bat 双击启动


启动之后通过地址:http://localhost:5601/,访问
【注意】启动Kibana之前要先启动ES,不然会报错:Error: No Living connections Unable to revive connection: http://localhost:9200/
kibana配置:https://www.elastic.co/guide/cn/kibana/current/settings.html
如果需要修改配置,修改 /config/kibana.yml 配置文件。

Kibana的端口号5601,是一个Web应用程序。
访问地址:http://localhost:5601/
访问Kibana页面,默认情况设置:
Discover 页面加载时选择的是默认索引模式。
时间过滤器设置的为最近15分钟。
搜索查询设置的是
match-all(\*)
可以通过:http://localhost:5601/status,来检查Kibana的当前状态,返回图标的格式显示。

也可以通过:http://localhost:5601/api/status,返回以JSON格式输出的Kibana的状态信息。

搜索数据的时候,你可以使用Kibana标准的查询语言(基于Lucene的查询语法)或者完全基于JSON的Elasticsearch查询语言DSL。
引号包括起来作为一个整体来搜索
在搜索的时候,用引号 " " 包裹起来的一段字符串叫短语搜索。
例如,
filed:"Hello World Kibana"将在filed字段中搜索"Hello World Kibana"这个短语。如果没有引号包裹,将会匹配到包含这些词的所有文档,并且不管它们的顺序如何。也就是有引号包裹的时候,只会匹配到"Hello World Kibana",而不会匹配到类似于"Hello Kibana World "这种顺序不同的。
在Dev Tools 下写DSL语句,执行
 Dev Tools的 Console 控制台支持CRUL,有以下特点
Dev Tools的 Console 控制台支持CRUL,有以下特点
可以通过使用绿色三角形按钮向ES提交请求。
使用扳手菜单来做其他有用的事情(copy as curl,auto indent)。
可以以cURL格式粘贴请求,它们将被转换为控制台语法。


2.3 DSL语句
一般ES查询结果文档的图:

1. 索引操作
查看集群的健康状况:GET /_cluster/health 或者 GET _cat/health
 集群健康值(status 字段):
集群健康值(status 字段):
- 绿色 green —— 最健康的状态,代表所有的主分片和副本分片都可用,每个索引的primary shard和replica shard 都处于active的状态。
- 黄色 yellow ——所有的主分片可用,但是部分副本分片不可用,即每个索引的primary shard是active的状态,但是部分replica shard不是active的状态,处于不可用的状态。
- 红色 red ——部分主分片不可用,不是所有的primary shard 都是active的状态,这时候是危险的,至少我们不能保证写数据是安全的。(此时执行查询部分数据仍然可以查到,遇到这种情况,尽可能的快速解决。)
查询所有的索引:GET /_cat/indices?v
![]()
查询所有信息:GET _all
删除某个索引:DELETE /user
创建索引库:PUT user(增加一个user的index库)
更详细地配置:
number_of_shards 分片数量;
number_of_replicas 副本数量。
PUT user
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 2
}
}
- PUT 类似于SQL中的新增
- DELETE 类似于SQL中的删除
- POST 类似于SQL中的修改
- GET 类似于SQL中的查查询
2. 映射操作
为了能够将数字域视为数字、时间域视为时间、字符串域视为全文或精确值字符串, Elasticsearch 需要知道每个域中数据的类型。这个信息包含在映射中。
核心简单域类型
Elasticsearch 支持如下简单域类型:
- 字符串:
string- 整数 :
byte,short,integer,long- 浮点数:
float,double- 布尔型:
boolean- 日期:
date
当你索引一个包含新域的文档(之前未曾出现过的域) Elasticsearch 会使用 动态映射,通过JSON中基本数据类型,尝试猜测域类型,使用如下转换规则:
| JSON 数据类型type | 域 数据类型type |
|---|---|
布尔型: true 或者 false |
boolean |
整数: 123 |
long |
浮点数: 123.45 |
double |
字符串,有效日期: 2014-09-15 |
date |
字符串: foo bar |
string |
如果你通过引号( “111” )索引一个数字,它会被映射为 string 类型,而不是 long 。但是,如果这个域已经映射为 long ,那么 Elasticsearch 会尝试将这个字符串转化为 long ,如果无法转化,则抛出一个异常。
如果索引字段没有设置映射,ES会使用动态映射,猜测域类型然后给它映射。
查看索引映射:
# 查看索引user的映射
GET /user/_mapping
# 查看索引user中类型userinfo的映射(两种都行)
GET /user/_mapping/userinfo
GET /user/userinfo/_mapping
自定义域映射
在很多情况下基本域数据类型已经够用,但经常需要为单独域自定义映射,特别是字符串域。自定义映射允许你执行下面的操作:
- 全文字符串域和精确值字符串域的区别
- 使用特定语言分析器
- 优化域以适应部分匹配
- 指定自定义数据格式
域最重要的属性是
type。对于不是string的域,你一般只需要设置type类型就可以。# 给number域设置integer类型 "number": { "type": "integer" }
string 域映射的两个最重要属性是 index属性 和 analyzer属性
index属性
index属性控制怎样索引字符串。它可以是下面三个值:
analyzed
首先分析字符串,然后索引它(以全文索引这个域)
not_analyzed
索引这个域,所以它能够被搜索,但索引的是精确值。不会对它进行分析。
no
不索引这个域。这个域不会被搜索到。
string域index属性默认是analyzed。如果我们想映射这个字段为一个精确值,我们需要设置它为 `not_analyzed"name": { "type": "string", "index": "not_analyzed" }其他简单类型(例如
long,double,date等)也接受index参数,但有意义的值只有no和not_analyzed, 因为它们永远不会被分析。
analyzer属性
对于
analyzed字符串域,用analyzer属性指定在搜索和索引时使用的分析器。Elasticsearch 默认使用
standard分析器, 还有其它的内置的分析器替,如:whitespace、simple和english:{ "name": { "type": "string", "analyzer": "standard" # 还可以取值whitespace 、 simple 和 english } }
添加映射(ik_smart是粗粒度检索,本身分词会较细粒度max_word少),analyzer 使用 ik_smart,IK分词器(需要下载plugin)
PUT user/userinfo/_mapping
{
"properties": {
"name": {
"type": "string",
"analyzer": "ik_smart",
"store": false,
"search_analyzer": "ik_smart"
},
"age": {
"type": "long",
"store": false
},
"description": {
"type": "text",
"analyzer": "ik_smart",
"store": false,
"search_analyzer": "ik_smart"
}
}
}
使用 analyze API 测试字符串域的映射,name 使用 ik_smart 分词器,对I am strive_day, I love china 进行分词
GET /user/_analyze
{
"field": "name",
"text": "strive_day, 爱中国"
}
结果:
{
"tokens" : [
{
"token" : "strive_day",
"start_offset" : 0,
"end_offset" : 10,
"type" : "LETTER",
"position" : 0
},
{
"token" : "爱",
"start_offset" : 12,
"end_offset" : 13,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国",
"start_offset" : 13,
"end_offset" : 15,
"type" : "CN_WORD",
"position" : 2
}
]
}
token: 是实际存储到索引中的词条。
start_offset 和 end_offset :指明字符在原始字符串中的起始和终止位置。
type:是字符的类型。
position 指明词条在原始文本中出现的位置。
3. 添加数据 PUT / POST
保存一篇文档到索引当中去 (这相当于插入一条记录到一个数据库表当中)
保存文档到索引当中,如果没有设置id,会自动分配一个id。
PUT 和 POST 都可以用于创建数据,只是创建的格式不同。
POST /uri
PUT /uri/xxx
PUT user/userinfo/1
{
"name":"孙悟空",
"age":2599,
"description":"齐天大圣"
}
PUT user/userinfo/2
{
"name":"如来佛祖",
"age":2586,
"description":"多宝道人"
}
4. 查询数据
获取某个索引中某个类型某个id的数据(返回Json格式):
GET 索引名/类型名/id,例如:
GET user/userinfo/1 或 GET user/userinfo/1?_source
获取某个索引中某个类型的某个id的某列数据(获取name列数据):
GET user/userinfo/1?_source=name
获取某个索引中某个类型某个id的某几列数据(name,description列):
GET user/userinfo/1?_source=name,description
match_all: 查询简单的匹配所有文档,匹配所有数据返回为json格式。在没有指定查询方式时,它是默认的查询。
GET /user/userinfo/_search
{
"query": {
"match_all": {}
}
}
match : 标准查询(无论在任何字段进行 全文本查询/精准查询都可以使用match)
如果你在一个全文字段上使用 match 查询,在执行查询前,它将用正确的分析器去分析查询的字符串
GET /user/userinfo/_search
{
"query": {
"match": {
"name": "孙悟空"
}
}
}
如果在一个精确值的字段上使用它,例如数字、日期、布尔或者一个
not_analyzed字符串字段,那么它将会精确匹配给定的值:
GET /user/userinfo/_search
{
"query": {
{ "match": { "age": 26 }}
{ "match": { "description": "孙悟空" }}
{ "match": { "boolean": true }}
}
}
对于精确值的查询,你可能需要使用 filter 语句来取代 query,因为 filter 将会被缓存。
_source :返回指定字段的内容(这里返回description和name字段)
这个字段包含我们索引数据时发送给 Elasticsearch 的原始 JSON 文档
在请求的查询串参数中加上
pretty参数,这将会调用 Elasticsearch 的 pretty-print 功能,该功能 使得 JSON 响应体更加可读。但是,_source字段不能被格式化打印出来。相反,我们得到的_source字段中的 JSON 串,刚好是和我们传给它的一样。
GET /user/userinfo/_search
{
"query": {
"match": {
"name": "孙悟空"
}
},
"_source": ["description", "name"]
}
在查询数据的时候,查询条件也会进行分词(所以下面这个方式查询到两条结果 -孙悟空和如来佛祖的数据)
GET /user/userinfo/_search
{
"query": {
"match": {
"name": "孙悟空 如来佛祖"
}
}
}
match_phrase:让查询条件不进行分词,精确匹配(下面这个就查询不到数据,因为没有name = 孙悟空 如来佛祖 的文档数据)
GET /user/userinfo/_search
{
"query": {
"match_phrase": {
"name": "孙悟空 如来佛祖"
}
}
}
highlight : 将查询结果高亮显示,默认以html的 ; 标签包裹,可以自定义替换(支持html语言),关于高亮可以查看这个>>>
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/search-request-highlighting.html
GET /user/userinfo/_search
{
"query": {
"match": {
"name": "孙悟空"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
空搜索 - 没有指定任何查询的空搜索,返回集群中所有索引下的所有文档
GET /_search
Elasticsearch 转发搜索请求到每一个主分片或者副本分片,汇集查询出的前10个结果,并且返回给我们。
空搜索 中如果集群中有超过 10 个文档匹配了 。 但是在 hits 数组中只有 10 个文档显示出来。如何才能看到其他的文档?
— > 使用 分页 技术 (下面有分页相关的信息 : 查看如何使用分页 )
其他GET 多索引、多类型的使用
GET /_search
# 在所有的索引中搜索所有的类型 返回所有索引中的所有文档(并将前10个结果返回)
GET /_search
# 在 user 索引中搜索所有的类型
GET /user/_search
# 在 user 和 website 索引中搜索所有的文档
GET /user,website/_search
# 在任何以 u 或者 w 开头的索引中搜索所有的类型
GET /u*,w*/_search
# 在 user 索引中搜索 userinfo 类型
GET /user/userinfo/_search
# 在 user 和 website 索引中搜索 userinfo 和 blog 类型(两个索引中,匹配类型)
GET /user,website/userinfo,blog/_search
# 在所有的索引中搜索 user 和 blog 类型
GET /_all/user,blog/_search
5. 更新数据POST、PUT
在 Elasticsearch 中文档是 不可改变 的,不能修改它们。如果想要更新现有的文档,需要 重建索引 或者 进行替换,在ES内部,Elasticsearch 已将旧文档标记为已删除,并增加一个全新的文档。(就是新建索引,然后将原索引删除,可以查看每次更新后 _version 字段增加)。
尽管你不能再对旧版本的文档进行访问,但它并不会立即消失。当继续索引更多的数据,Elasticsearch 会在后台清理这些已删除文档。
Elasticsearch 更新文档 步骤:
- 从旧文档构建 JSON 数据
- 更改该 JSON 数据
- 删除旧文档
- 重新索引一个新文档
使用GET命令查询ID=1的Source信息
GET user/userinfo/1/_source
查询结果:
{
"name" : "孙悟空",
"age" : 2599,
"description" : "齐天大圣"
}
PUT采用的是覆盖的方式进行文档的更新,但是这种修改会丢失数据, 这是全局的修改。
PUT user/userinfo/1
{
"name":"猪八戒",
"age":18
}
查询结果 GET user/userinfo/1/_source
{
"name" : "猪八戒",
"age" : 18
}
执行上述的操作后,发现之前的 description 列消失了(PUT全局更新,原文档本删除后重新索引了)。
如果只需要更新某个字段使用POST:
POST user/userinfo/1
{
"doc":{
"name":"猪八戒",
"age":18
}
}
查询结果 GET user/userinfo/1/_source
{
"name" : "猪八戒",
"age" : 18
}
发现之前的 description 列也消失了,因为被覆盖了。
所以真正的局部更新应该在后面添加字段 _update
POST user/userinfo/1/_update
{
"doc":{
"name":"猪八戒",
"age":18
}
}
查询结果 GET user/userinfo/1/_source
{
"name" : "猪八戒",
"age" : 18,
"description" : "齐天大圣"
}
这时候发现 description 列存在,没有被删除,因为使用 _update 更新只是局部更新,虽然还是新建了一个文档,但是保留了没有更新的原字段。
Post 和 Put 的区别:
Post 和 Put 都可以用于创建和更新数据。
POST /uri创建或更新PUT /uri/xxx更新或创建POST方式不用加具体的id,它是作用在一个集合资源之上的(/uri),而PUT操作是作用在一个具体资源之上的(/uri/xxx)。
在ES中,如果不确定 文档document 的ID,那么直接POST对应uri( 比如:POST /user/userinfo/1),ES可以自己生成不会发生碰撞的UUID。(自动生成的 ID 是 URL-safe、 基于 Base64 编码且长度为20个字符的 GUID 字符串。)
这些 GUID 字符串由可修改的 FlakeID 模式生成,这种模式允许多个节点并行生成唯一 ID ,且互相之间的冲突概率几乎为零。POST可以实现局部更新数据(
_update),别的数据不改变,只更新需要更新的数据。PUT只能全局更新(没有更新的字段默认删除)POST 和 PUT 主要区别
- 更新:PUT会将新的json值完全替换掉旧的;而POST方式只会更新相同字段的值,其他数据不会改变,新提交的字段若不存在则增加。
- PUT和DELETE操作是幂等的。所谓幂等是指不管进行多少次操作,结果都一样。比如用PUT修改一篇文章,然后在做同样的操作,每次操作后的结果并没有什么不同,DELETE也是一样。
- POST操作不是幂等的,比如常见的POST重复加载问题:当我们多次发出同样的POST请求后,其结果是创建了若干的资源。
- 创建操作可以使用POST,也可以使用PUT,区别就在于POST是作用在一个集合资源(
/user/userinfo)之上的,而PUT操作是作用在一个具体资源之上的(/user/userinfo/123)。
6. 删除数据
删除一条指定id的记录:DELETE user/userinfo/1
如果存在对应id的文档,那么删除成功,返回一个 200 ok 的 HTTP 响应码,并且版本号字段_version 值增加, "result" : "deleted"。
如果不存在,那么返回失败,得到 404 Not Found 的响应码,并且版本号字段_version 值也会增加,"result" : "not_found"
即使文档不存在(
Found是false),_version值仍然会增加。这是 Elasticsearch 内部记录本的一部分,用来确保这些改变在跨多节点时以正确的顺序执行。
7. 高级查询
order:搜索排序
排序条件的顺序是很重要的。结果首先按第一个条件排序,仅当结果集的第一个 sort 值完全相同时才会按照第二个条件进行排序,依此类推。
按age升序排序,如果排序完全相同才会安装name降序排序"sort": [ { "age": { "order": "asc" }}, { "name": { "order": "desc" }} ]
按age年龄排序
GET /user/userinfo/_search
{
"query": {
"match_all": {}
},
"sort":{
"age":{
"order": "desc"
}
}
}
或者
GET /user/userinfo/_search
{
"sort":{
"age":{
"order": "desc"
}
}
}
分页查询
在之前的 空搜索 中说到了了集群中有超过 10 个文档匹配了 。 但是在 hits 数组中默认只有 10 个文档。那么怎么才能查看到其他的文档信息,就需要使用到分页查询了。
分页查询 和 SQL 中使用的 LIMIT 关键字返回单个 page 结果的方法是一样的,Elasticsearch 分页查询使用到 from 和 size 参数:
- from:显示应该跳过的初始结果数量(跳过多少条数据之后再显示),默认值为0。
- size:每页应该返回的数据量,默认值为10.
# 搜索所有索引所有类型数据,且显示前20条数据(from默认为0)
GET /_search?size=20
# 显示第1-第21条数据(from=1,跳过第一条显示)
GET /_search?size=20&from=1
# 显示第21-第40条数据(from=20.跳过前20条数据)
GET /_search?size=20&from=20
# 查找user索引中userinfo类型,跳过from=前3条数据,按每页2条数据显示第3-第5条(2条)数据,且按照age降序显示。
GET /user/userinfo/_search
{
"query": {
"match_all": {}
},
"sort":{
"age":{
"order": "desc"
}
},
"from": 3,
"size": 2
}
在分布式系统中深度分页
为什么深度分页是有问题的?我们可以假设在一个有 5 个主分片的索引中搜索。 当我们请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,并且返回给 协调节点 ,协调节点对 50 个结果排序得到全部结果的前 10 个。
现在假设我们请求第 1000 页,结果从 10001 到 10010 。所有都以相同的方式工作除了每个分片不得不产生前10010个结果以外。 然后协调节点对全部 50050 个结果排序最后丢弃掉这些结果中的 50040 个结果。
可以看到,在分布式系统中,对结果排序的成本随分页的深度成指数上升。这就是 web 搜索引擎对任何查询都不要返回超过 1000 个结果的原因。
multi_match 查询:可以在多个字段上执行相同的 match 查询。
根据多个字段查询 - 根据 fields 中的列,找满足query的值(从多列中查找对应query值的文档)
GET /user/userinfo/_search
{
"query": {
"multi_match": {
"query": "孙悟空",
"fields": [
"name",
"description"
]
}
}
}
过滤查询
term: term 词项搜索主要用于分词精确匹配字符串、数值、日期或者那些 not_analyzed 等的值
term 查询对于输入的文本不 分析 ,所以它将给定的值进行精确查询。
GET /user/userinfo/_search
{
"query": {
"term": {
"age":{
"value": 2599
}
}
}
}
terms:和 term 查询一样,但它允许你指定多值进行匹配,其实就是多个 term 词项搜索(多条件用terms)。
如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件。
terms 查询对于输入的文本也不进行不分析。它查询那些精确匹配的值(包括在大小写、重音、空格等方面的差异)
GET /user/userinfo/_search
{
"query": {
"terms": {
"age": [2599, 2586, 21]
}
}
}
范围过滤查询
range: 过滤允许按照指定范围查找一批数据。
gte:大于等于
lte:小于等于
gt:大于
lt:等于
GET /user/userinfo/_search
{
"query": {
"range": {
"age": {
"gte": 18,
"lte": 2586
}
}
}
}
exists:过滤查询 - 查找指定字段中 有值 存在的文档(类似于mysql中该列有数据的就能查询出来,类似于SQL中的 NOT IS_NULL)
missing : 查找指定字段中 没有值 存在的文档(类似于SQL中的 IS_NULL)
GET /user/userinfo/_search
{
"query": {
"exists": {
"field": "description"
}
}
}
bool 过滤: - 用来合并多个过滤条件查询结果的布尔逻辑(当需要多个查询条件拼接的时候就用bool,就是将多查询组合成单一查询的查询方法),它包含以下操作符:
- must:多个查询条件的完全匹配,相当于and;
- must_not:多个查询条件的相反匹配,相当于not;
- should:如果满足这些语句中的任意语句,将增加
_score,主要用于修正每个文档的相关性得分,相当于or。- filter:必须匹配,但它以不评分、过滤模式来进行。这些语句对评分
_score没有贡献,只是根据过滤标准来排除或包含文档。不评分查询,可缓存。使用filter(过滤),表明只希望获取匹配对应的文档,并不需要获取对应的相关性(即获取到的文档都会评分为零分_source)
- 相关性得分组合方法:
每一个子查询都独自地计算文档的相关性得分。一旦他们的得分被计算出来, bool 查询就将这些得分进行合并并且返回一个代表整个布尔操作的得分。
GET /user/userinfo/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": "孙悟空"
}
}
],
"filter": {
"range": {
"age": {
"gte": 18,
"lte": 2600
}
}
}
}
}
}
查找字段 description 必须匹配为 齐天大圣 的文档,并且 name 不是 猴子,age 在 ( 30, 2600 ] 区间,且 name 按照 孙悟空、猪八戒 进行比较评分排名显示。
GET /user/userinfo/_search
{
"query": {
"bool": {
"must": {
"match": {
"description": "齐天大圣"
}
},
"must_not": {
"match": {
"name": "猴子"
}
},
"should": {
"match": {
"name": "孙悟空, 猪八戒"
}
},
"filter": {
"range": {
"age": {
"gt": 30,
"lte": 2600
}
}
}
}
}
}
如果没有 must 语句,那么至少需要能够匹配其中的一条 should 语句。但,如果存在至少一条 must 语句,则对 should 语句的匹配没有要求。
constant_score 查询:它将一个不变的常量评分应用于所有匹配的文档。它被经常用于你只需要执行一个 filter 而没有其它查询的情况下。
可以使用它来取代只有 filter 语句的 bool 查询。在性能上是完全相同的,但对于提高查询简洁性和清晰度有很大帮助。
GET /user/userinfo/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "孙悟空"
}
}
}
}
}
term 查询被放置在 constant_score 中,转成不评分的 filter。这种方式可以用来取代只有 filter 语句的 bool 查询。
根据某个字符搜索满足条件的数据(需要数据完全匹配)
GET /user/userinfo/_search
{
"query": {
"match": {
"description": "齐天大圣"
}
}
}
根据字段前缀查询满足添加的数据(只能从文档字段的第一个词开始匹配,一旦出现不同就匹配失败,比如name = 孙悟空,匹配悟、悟空都是查询不到数据的)
GET /user/userinfo/_search
{
"query": {
"prefix": {
"name": {
"value": "孙"
}
}
}
}
上述代码>>>
# 查看集群健康状态
GET /_cluster/health
GET _cat/health
# 查询所有的索引
GET /_cat/indices?v
# 查询所有信息
GET _all
# 获取集群的节点列表
GET /_cat/nodes?v
# 删除某个索引
DELETE demo
# 创建索引库
PUT user
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 2
}
}
# 添加映射(IK分词器:ik_smart是粗粒度检索)
PUT user/userinfo/_mapping
{
"properties": {
"name": {
"type": "text",
"analyzer": "ik_smart",
"store": false,
"search_analyzer": "ik_smart"
},
"age": {
"type": "long",
"store": false
},
"description": {
"type": "text",
"analyzer": "ik_smart",
"store": false,
"search_analyzer": "ik_smart"
}
}
}
# 查看映射
GET user/userinfo/_mapping
# 添加数据
PUT user/userinfo/1
{
"name": "孙悟空",
"age": 2599,
"description": "齐天大圣"
}
PUT user/userinfo/2
{
"name": "如来佛祖",
"age": 2586,
"description": "多宝道人"
}
# 查询数据
GET user/userinfo/1
# 或者这么查询
GET user/userinfo/1?_source
# match_all - 查询所有数据
GET /user/userinfo/_search
{
"query": {
"match_all": {}
}
}
# match - 标准查询(全文本查询/精准查询一般都用得上)
GET /user/userinfo/_search
{
"query": {
"match": {
"name": "孙悟空"
}
}
}
# 查询数据的时候,查询条件也会进行分词(所以查询到两条结果)
GET /user/userinfo/_search
{
"query": {
"match": {
"name": "孙悟空 如来佛祖"
}
}
}
# 使用match_phrase,让查询条件不进行分词,精确匹配
GET /user/userinfo/_search
{
"query": {
"match_phrase": {
"name": "孙悟空 如来佛祖"
}
}
}
# highlight - 将查询结果高亮显示,默认是<em>标签,可以自定义替换
GET /user/userinfo/_search
{
"query": {
"match": {
"name": "孙悟空"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
# 通过 _source 返回指定字段的内容
GET /user/userinfo/_search
{
"query": {
"match": {
"name": "孙悟空"
}
},
"_source": [
"description",
"name"
]
}
# 获取user索引中某个类型的某个id的某列(name)数据
GET user/userinfo/1?_source=name
GET user/userinfo/2?_source=description
# 获取某个索引中某个类型某个id的某几列数据
GET user/userinfo/1?_source=name,description
# 局部更新数据 Post(age没有更新还在)
POST user/userinfo/1/_update
{
"doc": {
"name": "沙悟净",
"description": "物流搬运工"
}
}
# 全局更新 PUT(删掉重建,age被删除了)
PUT user/userinfo/1
{
"doc": {
"name": "沙悟净",
"description": "物流搬运工"
}
}
# 搜索(按age年龄降序输出)
GET /user/userinfo/_search
{
"query": {
"match_all": {}
},
"sort": {
"age": {
"order": "desc"
}
}
}
# 分页查询 from:跳过前多少条数据,size:每页数据量
GET /user/userinfo/_search
{
"query": {
"match_all": {}
},
"sort": {
"age": {
"order": "desc"
}
},
"from": 0,
"size": 2
}
# 过滤查询 - term(精确匹配字符串、日期、数值等)
GET /user/userinfo/_search
{
"query": {
"term": {
"age": {
"value": 2599
}
}
}
}
# 多个term词项搜索(多条件)
GET /user/userinfo/_search
{
"query": {
"terms": {
"age": [
2599,2586,21
]
}
}
}
# range 范围过滤查询 - 过滤允许按照指定范围查找一批数据。
GET /user/userinfo/_search
{
"query": {
"range": {
"age": {
"gte": 18,
"lte": 2586
}
}
}
}
# exists过滤查询 - 查找拥有某个域的数据
GET /user/userinfo/_search
{
"query": {
"exists": {
"field": "description"
}
}
}
# bool 过滤 - 合并多个过滤条件查询结果的布尔逻辑(多个查询条件拼接)
GET /user/userinfo/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": "孙悟空"
}
}
],
"filter": {
"range": {
"age": {
"gte": 18,
"lte": 2600
}
}
}
}
}
}
# 根据某个字符搜索满足条件的数据
GET /user/userinfo/_search
{
"query": {
"match": {
"description": "齐天大圣"
}
}
}
# 根据字段前缀查询满足添加的数据
GET /user/userinfo/_search
{
"query": {
"prefix": {
"name": {
"value": "孙"
}
}
}
}
# 根据多个字段查询 - 根据fields中的列,找满足query的值(从多列中查找)
GET /user/userinfo/_search
{
"query": {
"multi_match": {
"query": "孙悟空",
"fields": [
"name",
"description"
]
}
}
}
# 删除数据
DELETE user/userinfo/2