JVM堆外内存导致的FGC问题排查

问题发现
服务在线上环境频繁的Full GC。把相关运行时数据区的监控打开,发现堆外内存一直在上升。

我使用的版本是 java8,jvm厂商是orcale hotspot,垃圾回收器使用的CMS+ParNew。
我使用的jvm参数是:
-Xmx6g -Xms6g -XX:NewRatio=1 -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:MaxTenuringThreshold=6 -XX:+ParallelRefProcEnabled -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+heapDumpOnOutOfMemoryError -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/export/Logs/gc.log
为了明确排查方向,需要研究堆外内存都具体有什么东西。于是我翻看了jvm的虚拟机规范。解读如下:
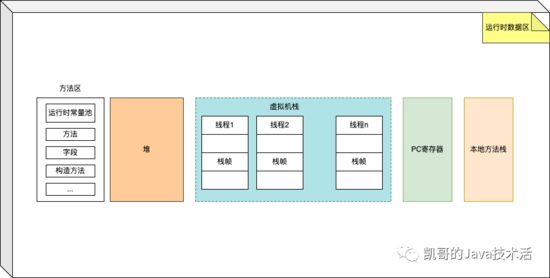
java虚拟机运行时数据区
Java虚拟机定义了程序执行期间使用的各种运行时数据区域。其中一些数据区域是在Java虚拟机启动时创建的,只有在Java虚拟机退出时才会被销毁,这部分线程共有。其他数据区域为每个线程。每线程数据区域在创建线程时创建,在线程退出时销毁,也就是线程私有。
运行时数据区分为以下几个部分:
1、PC寄存器(The pc Register)
每个线程一个,以保存当前执行指令的地址。一旦执行了指令,PC寄存器将用下一条指令更新。
2、虚拟机栈( Java Virtual Machine Stacks)
每个Java虚拟机线程都有一个私有Java虚拟机堆栈,与线程同时创建。虚拟机栈存储栈帧,它保存局部变量和部分结果。
虚拟机栈可能会出现Java虚拟机将抛出StackOverflowerError。
3、堆(Heap)
Java虚拟机线程之间共享堆,堆只有一个。堆是为所有类实例和数组分配内存的运行时数据区域。这也是我们创建的对象放置的区域。是最大的,最需要调优的地方。
堆是在虚拟机启动时创建的。对象的堆存储由垃圾收集器回收;对象永远不会显式解除分配。
如果计算需要的堆超过了自动存储管理系统的可用堆,Java虚拟机会抛出OutOfMemoryError。
4、方法区(Method Area)
存储所有类级别的数据,包括静态变量所有线程共享。Java虚拟机只有一个方法区。存储的有类结构,例如运行时常量池、字段和方法数据,以及方法和构造函数的代码,包括类和实例初始化以及接口初始化中使用的特殊方法。
5、运行时常量池(Run-Time Constant Pool)
运行时常量池是类文件中常量池表的每类或每接口运行时表示形式。它包含多种常量,从编译时已知的数字文本到必须在运行时解析的方法和字段引用。运行时常量池的功能类似于传统编程语言的符号表,尽管它包含比典型符号表更广泛的数据范围。
这段我抄的,为了保持完整性,运行时常量池其实是方法区的一部分。
6、本地方法栈(Native Method Stacks)
存储本地方法信息,线程私有。
整体结构表示如下
问题:方法区和元空间有什么关系?
简单理解,方法区是java的定义,而元空间则是hotspot虚拟机在1.8及其以后的实现。在1.7之前叫永久代(永久代还包含了部分老年对象),如果使用java8的话忽略永久代就行了。
根据jvm的规范,方法区内存储的都是jvm类级别的数据,包括什么构造方法,什么常量池什么的。那什么操作会使得这方面一直在上涨呢?带着问题,一步步搞呗。
简单尝试
首先先定死metaspce的大小,不让他动态扩容,因为元空间每次调整大小都会进行一次full gc。
jvm启动参数新增。
-XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m
但是发现并没有用。
是否能从堆看出些端倪?
堆外内存,没有特别好的查看方法。我决定还是把堆内存dump下来看看,看能否通过堆内存,看出一些猫腻来。
将堆dump下来进行分析。
使用命令 jps 找到java进程pid,指定生成文件的path。
jmap -dump:file=/path ${pid}
dump完毕后。
借助工具进行查询 首先使用mat,官方网站:https://www.eclipse.org/mat/。

这边看到了很多Netty的PoolThreaCache。
联想到netty使用了直接内存,是否和这个有关呢?
为此查询了大量资料,找到了一个参数:-Dio.netty.maxDirectMemory 。
这个参数大概意思是调整netty堆外内存,通过它有三个取值,无论调成什么都没办法阻止堆外内存的上涨。其实在这就有点无头苍蝇乱撞了。
确实,只有两种情况会导致netty相关的堆外内存上涨。
1、要么是netty有bug 。
2、要么是使用方法不对。
netty有bug,这个可能性就算了吧。使用的版本也不是最新的,也没有直接引用netty包,都是通过例如http-client或者rpc框架引入的netty。
使用方法不对?在http client或者rpc服务的部分代码排查了一遍,基本上都是比较简单的用法,并没有直接设置很怪的参数,或者很非常规的操作。
在这就确实在堆里面找不到有用的线索了。
找到原因
貌似确实没辙了。
随后我请教了我司的超级大佬:森哥。森哥给我要了相关权限后,上去机器一顿操作。推测可能是C2 Compiler或者什么即时编译导致的问题,因为堆外都是jvm级别的数据,常规的排查确实比较难找到线索。
听完后联想到堆外不就是方法区吗,我用的java8 hotspot虚拟机,也就是元空间了。
代码里面会有什么导致元空间上涨呢?
元空间是存储jvm级别的数据,是否有很多类加载?
带着这个猜想,找到相应的参数 -verbose:class,这个会将类加载全部打印出来。
如下图:

发现有非常多的ASMAccessorImpl_,而且是不会停止,一直在加载。
厚礼蟹,这就查到了原因。
那ASM是什么,如果研究过spring,就知道在aop扩展动态生成字节码,最底层其实就是ASM生成的,其实是一个字节码编辑框架。官网:https://asm.ow2.io/。
也就是说,我的代码有一个地方一直在动态生成类字节码,加载到方法区。从而导致堆外内存一直在上涨,从而导致full gc。
代码修改
那怎么定位到是哪段代码?
这个简单,打开idea,double shift,调search everywhere。
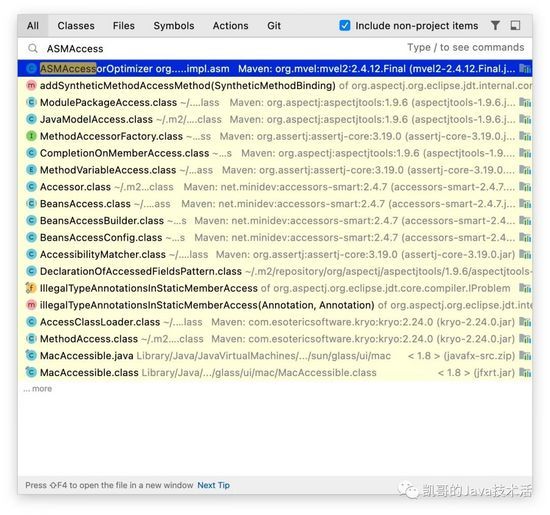
排查到是mvel这个依赖框架生成的。
关于mvel,其实是spel差不多,表达式解析引擎。在项目中,mvel的使用我们只用了两行代码。
MVEL.executeExpression() MVEL.compileExpression()
然后我们也有把编译完的进行缓存,按道理说不会一直生成类的。因为mvel这个框架实在是相关文档太少,没人维护的感觉,抱着死马当活马医的态度,去github上提一个issue,然后自己同时接着排查。
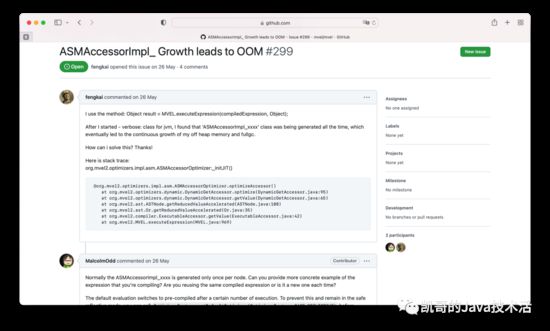
幸运的是这个框架还没死绝,还有人回复。
大概意思是说,我问为什么使用你们的mvel会导致我jvm出现oom错误(频繁的full gc),另外如果说每次编译相同的内容的话,为什么没有框架层面缓存起来。回答说是需要自己缓存的。
也就是我的代码还是缓存失效了。
找到缓存的那一行,使用的是map,用key去查找的时候, 发现用的是contains,而没有用containsKey。这就导致了永远查不到,也就导致了永远会重新编译。

经过修改后,问题得以解决。
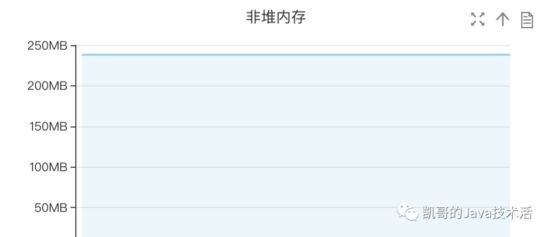
一条平平的线,并且没有full gc,皆大欢喜
总结
堆外内存有点难搞,难以和代码联系起来。提供一个思路:可通过-verbose:class查看类加载的情况,然后具体分析。