【视频异常检测】论文阅读
目录
Video Anomaly Detection by Solving Decoupled Spatio-Temporal Jigsaw Puzzles
Temporal-Aware Self-Supervised Learning for Unsupervised Video Anomaly Detection
Robust Unsupervised Video Anomaly Detection by Multi-Path Frame Prediction
Video Anomaly Detection by Solving Decoupled Spatio-Temporal Jigsaw Puzzles
self-supervised multi-label learning
https://arxiv.org/abs/2207.10172 | Code
受自监督学习最新进展的推动,本文通过解决一个直观但具有挑战性的借口任务解决视频异常检测,即时空拼图,该问题被视为一个多标签细粒度分类问题。
- 首先,我们通过只解决一个借口任务,大大简化了自监督学习框架,该任务被分解为空间和时间拼图,分别对应于建模正常外观和运动模式。
- 其次,采用全排列来产生高多样性的大规模学习样本,允许网络从借口任务中捕获细微的时空异常。为了确保计算效率,我们将益智求解描述为多标签学习问题,适应了变化数的阶乘。
- 第三,我们的方法不需要任何预先训练的网络,因为解决具有挑战性的借口本身有助于学习丰富和有区别的时空表示。
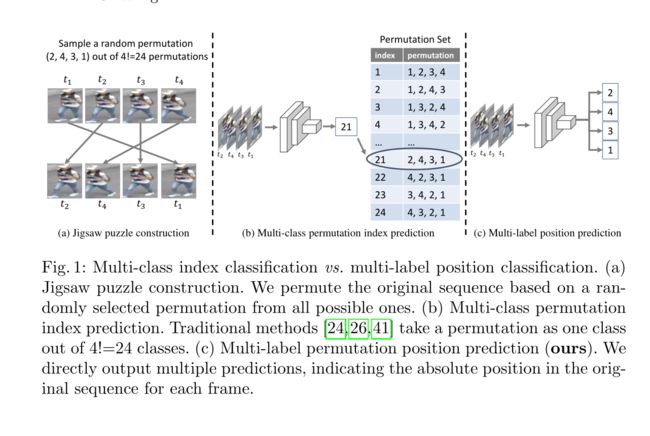
PS :下图可以看出 关于多标签 与 多分类的 区别
整体网络结构如下:
该方法包括三个步骤:以对象为中心的立方体提取、拼图构造和拼图求解。
首先使用现成的对象检测器[Yolov3]提取帧中的所有对象,并沿时间维度堆叠对象,以构建以对象为中心的立方体。对于每个立方体,我们进一步应用空间或时间混洗来构造相应的空间或时间拼图。最后,卷积神经网络充当拼图求解器,试图从其空间或时间置换版本恢复原始序列
空间拼图。对于每一帧,我们首先将其分解为n×n个大小相等的面片,然后将其随机混洗。我们使立方体中的所有帧共享相同的排列,同时保持它们按时间顺序排列。直接将空间混洗后的帧作为输入,这些帧与原始帧大小相同,即在我们的设置中为64×64。
时间拼图。为了构建时间拼图,我们在不破坏空间内容的情况下对 帧序列进行洗牌。Jenni等人[22]揭示了强大视频表示学习最有效的借口任务是那些可以通过观察最大数量的帧来解决的任务。例如,运动不规则性可以通过仅比较前两帧来容易地检测,而不是观察总帧数来解决我们的时间拼图,这对于学习运动模式的更具辨别性的表示至关重要。注意,我们不在时间上搅乱仅包含静态内容的帧序列,因为不可能通过简单观察视觉线索来推断其时间顺序。
不同于典型方法[24,26,41]将拼图求解表述为多类分类,其中每个排列都是一个类,我们将拼图解决视为多标签分类问题,并尝试直接预测每个帧的绝对位置或每个块的位置。
我们采用混合训练策略,其中训练小批量由两个不相交集组成:Qs和Qt,分别表示空间和时间拼图集。因此,小批量总共有|Qt|+| Qs|。值得注意的是,两个解算器(头部)只负责自己的拼图类型,即我们不依赖时间解算器来处理空间拼图,以避免歧义,反之亦然。
实验结果

Temporal-Aware Self-Supervised Learning for Unsupervised Video Anomaly Detection
Shang, Guoqian et al. “Temporal-Aware Self-Supervised Learning for Unsupervised Video Anomaly Detection.” 2021 5th Asian Conference on Artificial Intelligence Technology (ACAIT) (2021): 526-532.
Paper
现有的无监督方法通常通过帧重建或预测,然后根据重建或预测误差识别异常来实现VAD。
然而,这些方法存在两个局限性:
- 1)(快捷解决方案)Shortcut solution:以前基于DNNs的VAD通常倾向于获得快捷解决方案,导致它们无法捕获正常模式的语义特征。由于重建目标是输入,基于重建的异常检测器通常专注于存储输入的像素细节,因此也可以很好地重建异常。虽然视频预测在某种程度上避免了快捷解决方案的问题,但该框架检测不能确保学习器对正常数据产生较小的预测误差,因为它没有明确利用时间信息。(??)
- 2)(不对齐)Nonalignment : 基于 DNN 的方法已经获得了令人印象深刻的收益,但是用一个借口任务(重建或视频预测)处理 VAD 是次优的。
为了解决上述问题,我们提出了一种新的时间感知自监督学习框架,通过解决多种借口任务来获取高层次的语义特征并执行 VAD。
具体地说,我们应用多个时间变换来构造多个额外的自监督信号,以便我们的TASS网络通过执行多个代理任务来消除不对齐问题。
网络的整体结构
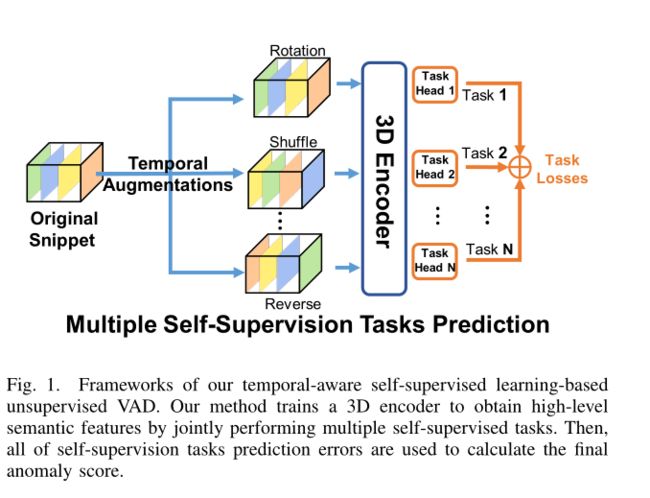
如图1所示,我们的模型包含三个模块:时间变换模块(TTM)、3D编码器和自监督任务模块(STM)。STM由多个任务头组成,每个任务头对应一个自我监督任务。
Temporal Transformation Module:具体而言,这些时间变换包括速度、抖动旋转、时间混洗和时间反转 。在这项工作中,我们介绍了两种类型的时间变换,时间反转和抖动旋转,用于执行自我监督任务。
- (1) 时间倒转:试图识别帧的播放顺序是向前还是向后。在测试阶段,预计异常行为的时间方向更难识别。
- (2) 抖动的旋转。我们不采用为图像设计的空间旋转[43],而是视频对片段中的不同帧执行抖动旋转。选择四个旋转方向,即0◦, 90◦, 180◦, 和270◦. 此外,随机噪声方向ε∈ [−3.◦,3.◦] 添加到原始旋转方向,以确保片段中的每个帧以不同的旋转角度旋转
对于原生的视频片段,则使用的是未来帧预测。
未来帧预测,使用的是下面两个损失(强度和梯度约束(Lint和Lgrd)用于学习视频预测)

由TTM中形成的自监督任务:都是使用交叉熵,并且任务的比重都是相同的
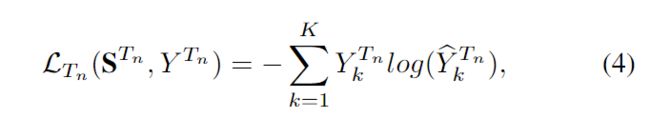
采用峰值信噪比(PSNR)来测量未来帧预测误差。对于自我监督任务,我们将视频片段正确预测被应用变换的概率作为自我监督任务给出的分数。通过应用时间高斯滤波器获得最终的规则性分数
对于3D Encoder 使用的是 3D-ResNets
任务头设计用于执行自我监督任务。所有任务头具有相同的网络架构。具体而言,任务头包括a pooling layer, a reshape operation, and a linear layer
实验结果

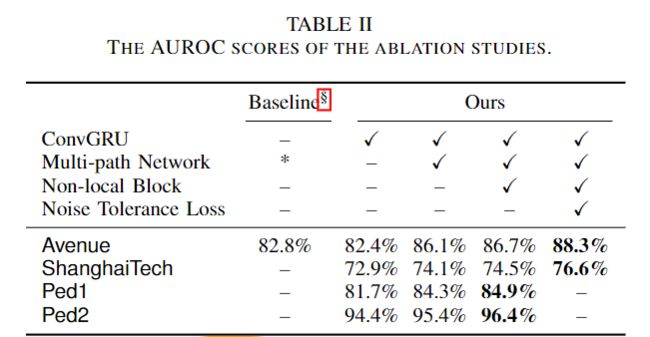
消融实验以研究我们的TASS网络的每个组件的分布,表三显示了UCSD Ped2数据集的结果。
Baseline:基本模型只执行视频未来帧预测任务
data augmentations:时间变换仅作为数据扩充

Robust Unsupervised Video Anomaly Detection by Multi-Path Frame Prediction
Wang, X. et al. “Robust Unsupervised Video Anomaly Detection by Multipath Frame Prediction.” IEEE Transactions on Neural Networks and Learning Systems 33 (2022): 2301-2312.
Paper
在本文中,我们提出了一种新的、鲁棒的无监督视频异常检测方法,该方法通过适当设计的帧预测,更符合监控视频的特点。该方法配备了基于多路径ConvGRU的帧预测网络,可以更好地处理不同尺度的语义信息对象和区域,并捕获正常视频中的时空相关性。在训练过程中引入noise tolerance loss(噪声容忍损失),以减轻背景噪声造成的干扰.
- 提出了一种新的无监督视频异常检测框架 ROADMAP,该框架在不同场景下具有适当的鲁棒性能设计。
- 为 ROADMAP 配备了 multi-path ConvGRU,它可以处理不同尺度的信息部分,捕捉帧之间的时间关系,而较少关注帧的静态和背景部分。
- 引入 noise tolerance loss (噪音容忍损失),以减轻视像帧内固有噪音像素所造成的干扰,这种损失大大提高了基于预测的异常检测系统的稳健性和性能。
网络整体框架如下:
我们提出的 ROADMAP 方法由一个预测网络 f (·)和一个评估模型 g (·)组成,分别用于基于历史预测帧和基于预测的结果确定异常。
Multi-Path Frame Prediction Network (图一左)
由图中可知有三个部分。
1) 编码器:编码器由几个具有二维卷积的基本残差块组成,并从输入帧中提取多尺度空间特征。这些不同尺度的特征随后将被馈入不同的预测路径。与标准残差块[ResNet]不同,我们的残差块移除了所有批量归一化层。这种修改保持了提取的空间信息通过编码器的流动,并被证明是有用的[51]
[51] B. Lim, S. Son, H. Kim, S. Nah, and K. Mu Lee, “Enhanced deep residual networks for single image super-resolution,” in IEEE conferenceon computer vision and pattern recognition workshops, 2017, pp. 136–144
2) 预测器:预测器配备有L=3个并行预测模块(路径),每个模块分别以不同分辨率的特征形式预测下一帧的信息。每个预测模块由非局部块(non-local block)和卷积门控递归单元(ConvGRUs)组成。上游非局部块捕获图像中所有位置的长距离相关性。ConvGRU自然地学习时间模式,其较小的感受野集中在非局部块输出的局部邻域。这两个部分一致地使得每个预测模块能够合并局部和全局时空信息。此外,并行路径中不同尺度的预测模块共同构建了更丰富的互补信息层次结构。
3) 解码器:解码器通过使用上采样和通道拼接操作构造输出帧,一个接一个地融合来自不同预测模块的不同尺度的特征。我们通过最近邻插值和残差块执行上采样操作,以消除输出中的棋盘伪影。类似于编码器中的那些,解码器中没有剩余块具有批量归一化层。解码器的输出具有与编码器的每个输入帧相同的形状。
总而言之,通过三个步骤基于 其P个先前帧 预测时间 t 的视频帧。首先,从每个帧中![]() 编码器产生L个不同的状态。
编码器产生L个不同的状态。

第二,预测器的每个模块基于来自P个编码器的相应输出进行自己的预测,即:
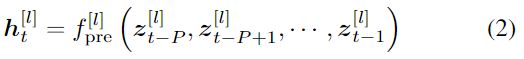
其中l=1,2,···,l。最后,解码器通过以下方式获得预测

Noise Tolerance Loss(图一右边)
帧预测模型被迫恢复每个像素的值。理想情况下,连续帧中的背景和静态对象保持不变,模型仅预测对象运动等信息性变化。然而,在实践中,我们总是在摄像机捕获的帧中发现许多内部或干扰噪声。这样的噪音会导致不规则以及相邻帧之间不可预测的像素波动,其支配训练损失并显著干扰模型训练。
为了减轻噪声造成的干扰并使预测模型更加稳健,我们引入了noise tolerance loss ,即通过预训练损失网络获得的感知损失。
类似的损失帮助了一些计算机视觉任务,如度量学习[54]、运动转移[55]、风格转移[56]和面部图像编辑[57]。虽然他们主要关注通过提取和重建高级特征来生成高质量的视觉结果,但我们的方法使用损失来消除捕获视频中噪声的干扰,从而异常检测结果对不可预测的噪声具有鲁棒性。
为了应用noise tolerance loss ,在训练预测网络时,我们同时将预测和真实帧传入损失网络,然后根据隐藏层输出计算损失。我们使用在ImageNet上训练的VGG16网络作为损失网络,其中间输出携带大量语义信息,同时滤除无关噪声。 给定V={2,4,7,10,13}作为损耗网络的选定层集合,以及控制第V层损耗强度的超参数αV,noise tolerance loss定义为:

下图可以看出应用noise tolerance loss 的对比
最终的损失函数包括:
intensity loss + the gradient difference loss + noise tolerance loss

异常分数:对每帧图片采用PSNR 判定质量,最后,我们通过最大最小归一化一个视频b中所有t帧的PSNR值Rt来计算第t帧的异常分数St

实验结果

消融实验