Weakly Superised video anomaly detection弱监督视频异常检测
关于弱监督的一些论文记录。(以便自己学习总结)
目录
Consistency-based Self-supervised Learning for Temporal Anomaly Localization
WEAKLY SUPERVISED VIDEO ANOMALY DETECTION VIA CENTER-GUIDED DISCRIMINATIVE LEARNING
编辑 PROPOSED METHOD
EXPERIMENTS
A Self-Reasoning Framework for Anomaly Detection Using Video-Level Labels
Cross-Epoch Learning for Weakly Supervised Anomaly Detection in Surveillance Videos
Methodology
B. Hard Instance Bank
Experimental Results编辑
MULTI-SCALE CONTINUITY-AWARE REFINEMENT NETWORK FOR WEAKLY SUPERVISED VIDEO ANOMALY DETECTION
记录新提出的部分
Multi-scale Continuity-aware Refinement Network
EXPERIMENTS
Consistency-based Self-supervised Learning for Temporal Anomaly Localization
WEAKLY SUPERVISED VIDEO ANOMALY DETECTION VIA CENTER-GUIDED DISCRIMINATIVE LEARNING
Wan, Boyang et al. “Weakly Supervised Video Anomaly Detection via Center-Guided Discriminative Learning.” 2020 IEEE International Conference on Multimedia and Expo (ICME) (2020): 1-6.
Paper:Weakly Supervised Video Anomaly Detection via Center-Guided Discriminative Learning | IEEE Conference Publication | IEEE Xplore
本文将视频异常检测视为弱监控下视频片段异常得分的回归问题。
为了学习异常检测的鉴别特征,我们为提出的AR网络设计了动态多实例学习损失和中心损失。前者用于扩大异常实例和正常实例之间的类间距离,而后者用于减少正常实例的类内距离。
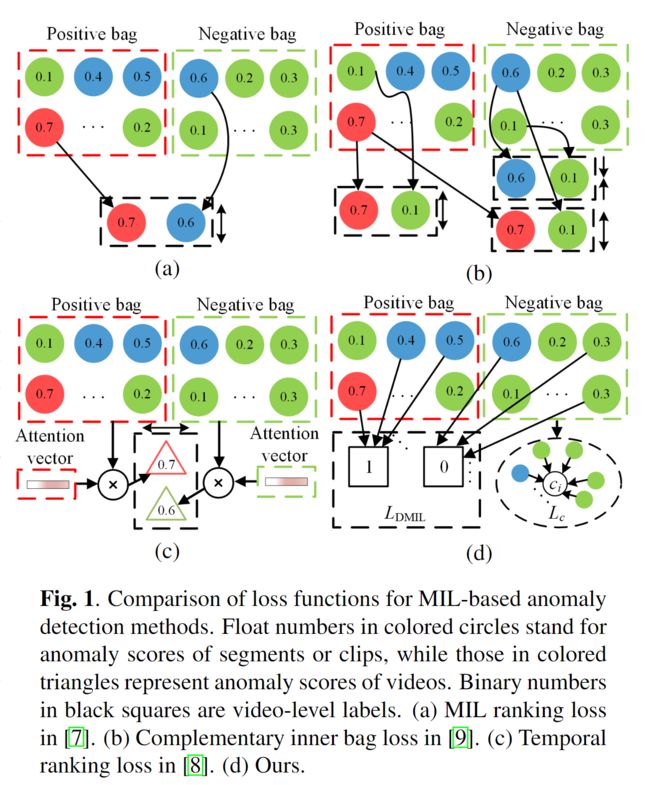 PROPOSED METHOD
PROPOSED METHOD
Problem Statement:
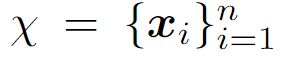 训练集一共包含 n 个视频。
训练集一共包含 n 个视频。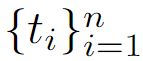 表示对于第 i 个视频的片段数。
表示对于第 i 个视频的片段数。
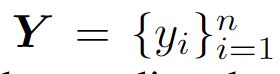 视频级标签,
视频级标签,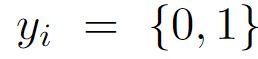 0,1分别表示没有异常,和有异常
0,1分别表示没有异常,和有异常
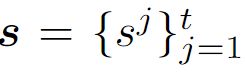 表示一个视频 的第j 个clip 的异常分数 ,值在0~1之间。
表示一个视频 的第j 个clip 的异常分数 ,值在0~1之间。
Feature Extraction:
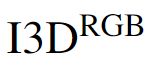
 分别表示 使用 行为识别网络I3D ,提取RGB 和 光流 特征
分别表示 使用 行为识别网络I3D ,提取RGB 和 光流 特征
一个视频 提取的特征维度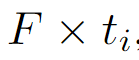
Anomaly Regression Network:

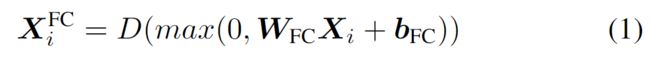 D(·)表示Dropout,
D(·)表示Dropout, 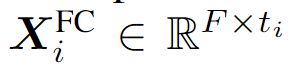 表示第i个视频特征从FC层的输出
表示第i个视频特征从FC层的输出

再通过AR layer 获得分数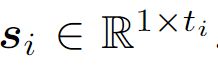
Dynamic Multiple-Instance Learning Loss :
用于扩大异常实例和正常实例之间的类间距离
每一个视频根据划分的片段选取的用于计算损失的个数 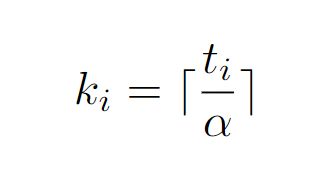
根据选区的 k 获取排名前k个值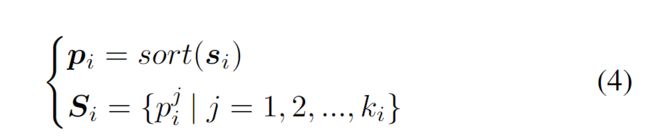
然后计算 DMIL loss 损失: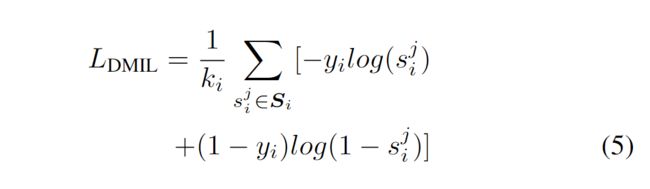
Center loss for Anomaly Scores Regression:
用于减少正常实例的类内距离
DMIL损失的目的是扩大实例的类间距离。然而,最大值和k-max选择方法都不可避免地会产生错误的标签分配,因为在早期训练阶段,异常视频中正常片段和异常片段的异常分数是相似的。因此,正常实例的类内距离因DMIL丢失而增大,这将降低测试阶段的检测精度。
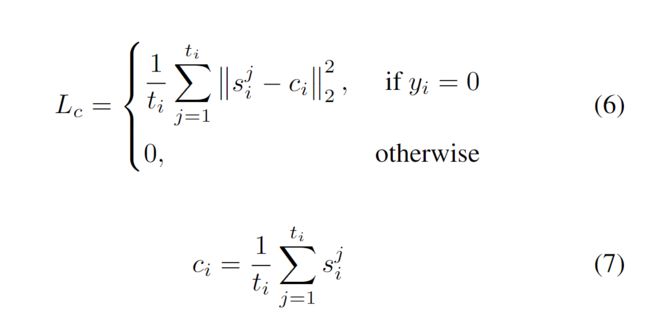
total loss function
文中 lamda :20
EXPERIMENTS
数据集:ShanghaiTech
Evaluation Metric: AUC
Implementation Details:
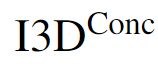 表示 RGB 与 光流的拼接。
表示 RGB 与 光流的拼接。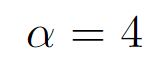
Dropout :0.7 batchsize:60 正例与反例 分别30,lr=0.0001
Results:

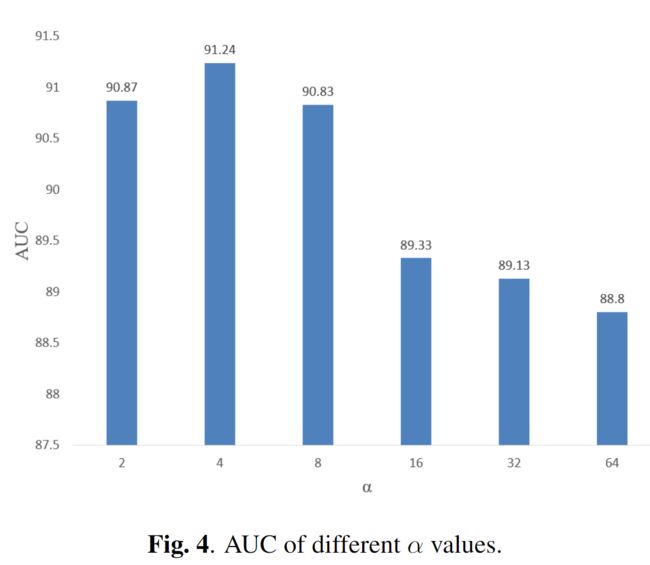
Ablation Study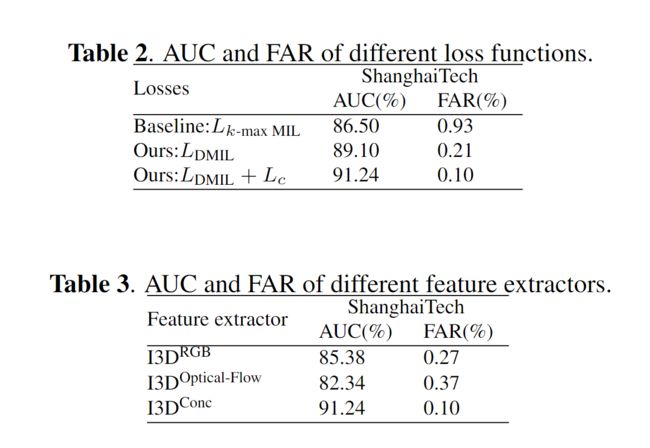
A Self-Reasoning Framework for Anomaly Detection Using Video-Level Labels
Cross-Epoch Learning for Weakly Supervised Anomaly Detection in Surveillance Videos
Yu, Shenghao, et al. "Cross-epoch learning for weakly supervised anomaly detection in surveillance videos." IEEE Signal Processing Letters 28 (2021): 2137-2141.
Code:GitHub - sdjsngs/XEL-WSAD: Official implement code for our paper:Cross-Epoch Learning for Weakly Supervised Anomaly Detection in Surveillance Videos
之前的工作将其视为一个回归问题,对正常和异常事件给出不同的分数。然而,广泛使用的小批量训练策略可能会受到这两类事件之间的数据不平衡的影响,从而限制了模型的性能。
在这项工作中,提出了一种与hard instance bank HIB 相关联的跨时期学习(cross-epoch learning XEL)策略,以引入来自先前训练时期的额外信息。为XEL提出了两种新的损失,以实现更高的检测率以及更低的异常事件错误报警率。此外,提出的XEL可以直接集成到任何现有的WSAD框架中。
提出了跨期学习(XEL)模型,以关注本文中的复杂案例,如图1所示。

hard instance bank HIB 被设计为在训练阶段期间的每个时期结束时从正常事件收集硬负实例。该HIB用于下一个时期的每个小批量的补充包。
Methodology
在弱监督异常检测(WSAD)的一般框架中有三个步骤:1)视频被划分为片段,并通过预训练的特征提取器转换为时空特征;2)异常分数由多层感知器(MLP)生成;3)模型通过损失函数优化。
异常检测数据集包括N个未修剪视频![]() ,与视频级别标签
,与视频级别标签![]() 相关,其中yi={0,1}(0:正常;1:异常)。正常视频的数量为M。WSAD的目标是检测测试视频中出现的异常事件。具体而言,V 中的第i个异常视频将被划分为 ki 个片段,并且第t个 eopch 中对应的异常得分向量可被视为:
相关,其中yi={0,1}(0:正常;1:异常)。正常视频的数量为M。WSAD的目标是检测测试视频中出现的异常事件。具体而言,V 中的第i个异常视频将被划分为 ki 个片段,并且第t个 eopch 中对应的异常得分向量可被视为:
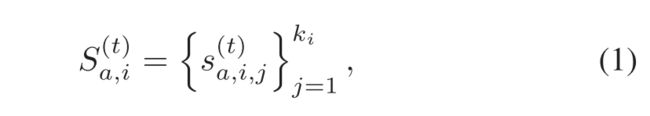
其中![]() 是
是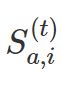 中的第j 个异常得分,得分值越高表示异常概率越高。
中的第j 个异常得分,得分值越高表示异常概率越高。
整个网络结构如图2.
首先,将输入视频划分为多个剪辑。然后应用特征提取器获得时空特征,并由多层感知器(MLP)生成所有剪辑的异常分数。高于给定阈值的事件将被视为异常事件。在这些过程中,插入了一个硬实例库(HIB),以利用这些硬负实例,即得分高但来自正常视频的实例,执行跨时期学习(XEL)。它将防止正常帧被错误地检测为异常实例。
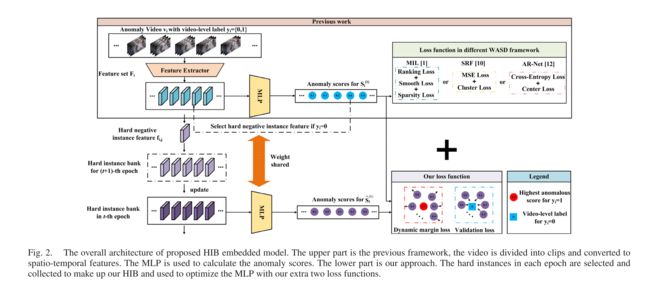
A.General Framework of WSAD
如上面提到的一样。
Video Split: 给定一个视频 分成ki段 ,下面表示第i个视频的第j个片段

Feature Extractor:应用预训练的神经网络从视频剪辑中提取时空特征。在我们的实验中测试了WSAD中两个广泛使用的网络,即C3D和 I3D。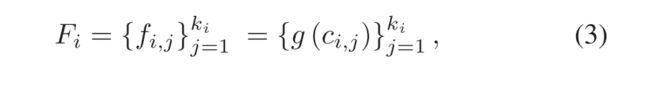
Anomaly Score Generator: 多层感知器(MLP)用于生成异常分数。一般2-3层就足够了。
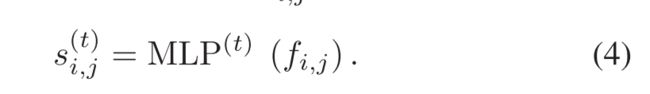
Loss Function:WSAD中损失函数的目标是指导模型学习对正常和异常事件的辨别能力。除了先前工作中使用的传统损失函数外,还提出了两种新的损失函数,即(validation loss and dynamic margin loss)验证损失和动态边际损失,以利用HIB来利用数据集的多样性
B. Hard Instance Bank
使用HIB来跨多个批次或时期收集信息。具体来说,在XEL策略是 M 个硬负面例子被选择去更新HIB 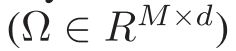 。作为正常和异常事件之间的边界,与两个新损失相关联的HIB具有两个优点:1)使用验证损失来抑制这些硬负实例的得分,以实现较低的误报率;2) 异常视频中的最高得分的下限被提升得更高,并具有动态边缘损失以提高检测率
。作为正常和异常事件之间的边界,与两个新损失相关联的HIB具有两个优点:1)使用验证损失来抑制这些硬负实例的得分,以实现较低的误报率;2) 异常视频中的最高得分的下限被提升得更高,并具有动态边缘损失以提高检测率
1) Updating HIB
在每个训练时期之后,对来自正常视频的所有剪辑进行重新评估。将选出得分最高的硬实例的特征:(e.g., t-th epoch and i-th normal video)
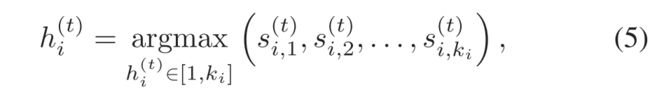
HIB在每个训练时期开始时更新: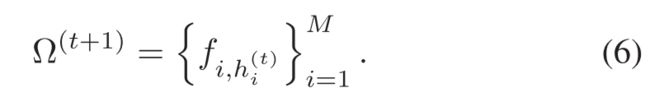
2) Learning With HIB
在第(t+1)个epoch 的第 l 次迭代中,在每次迭代中计算HIB中特征的异常得分向量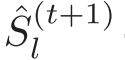 :
:
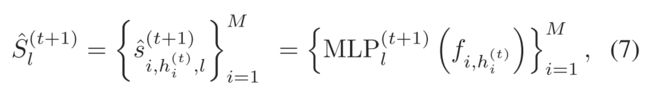
这可以被视为当前学习的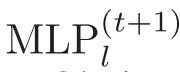 的验证过程,以评估其在正常视频上的性能。显然,正常视频的异常得分应该尽可能接近零。因此确认损失被定义为惩罚硬负实例,
的验证过程,以评估其在正常视频上的性能。显然,正常视频的异常得分应该尽可能接近零。因此确认损失被定义为惩罚硬负实例,
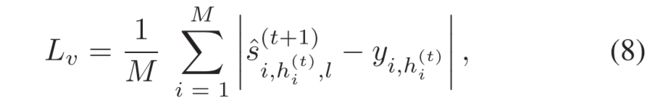
同时提出了一个 dynamic margin loss function ,该函数在HIB中的硬负实例和异常视频中的最异常实例之间具有maximum margin ε ,
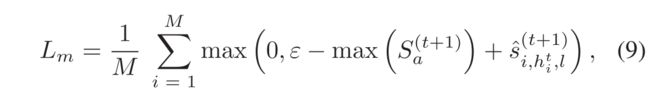
3) Final Loss Function

![]() is the loss function of any given WSAD framework.
is the loss function of any given WSAD framework.
Experimental Results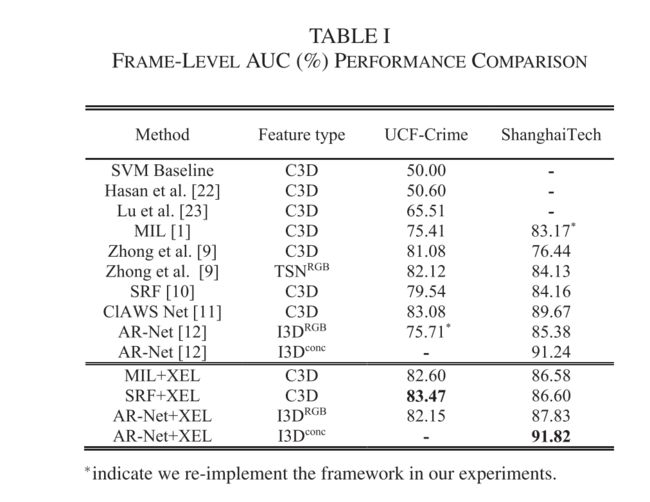

MULTI-SCALE CONTINUITY-AWARE REFINEMENT NETWORK FOR WEAKLY SUPERVISED VIDEO ANOMALY DETECTION
Y. Gong, C. Wang, X. Dai, S. Yu, L. Xiang and J. Wu, "Multi-Scale Continuity-Aware Refinement Network for Weakly Supervised Video Anomaly Detection," 2022 IEEE International Conference on Multimedia and Expo (ICME), 2022, pp. 1-6, doi: 10.1109/ICME52920.2022.9860012.
paper:Multi-Scale Continuity-Aware Refinement Network for Weakly Supervised Video Anomaly Detection | IEEE Conference Publication | IEEE Xplore
本文是早上面一篇 的基础上 改进:Weakly Supervised Video Anomaly Detection via Center-Guided Discriminative Learning
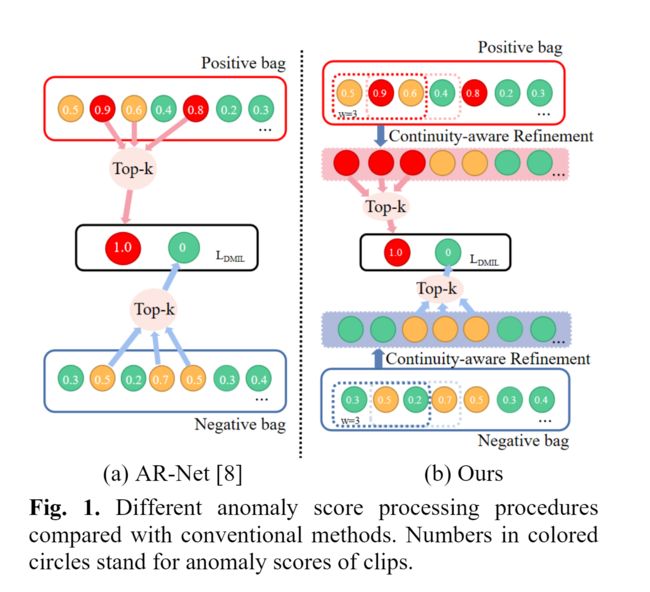
基于真实世界视频中异常事件往往更加连续的事实,本文提出了一种多尺度连续性感知细化网络(MCR)。它利用多尺度连续性的特性,通过引入实例的差异上下文信息来细化异常得分。同时,多尺度注意力被设计为产生视频级权重,以选择合适的尺度并融合不同尺度下的所有分数。
记录新提出的部分
Multi-scale Continuity-aware Refinement Network
在先前的工作[8][9]中,直接使用基本异常评分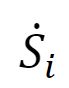 来定位异常剪辑。然而,该分数缺少视频的连续性信息,因为它是在不考虑其对应实例的上下文的情况下单独生成的。由于连续性是异常事件最重要的特征之一,所提出的MCR网络旨在通过引入实例的时间连续性来细化基本异常得分。因此,利用多尺度连续性模块通过在不同时间尺度上移动平均来提取异常连续性。此外,多尺度关注被应用于更好地整合不同尺度的信息,以增强所提出的MCR网络的鲁棒性。
来定位异常剪辑。然而,该分数缺少视频的连续性信息,因为它是在不考虑其对应实例的上下文的情况下单独生成的。由于连续性是异常事件最重要的特征之一,所提出的MCR网络旨在通过引入实例的时间连续性来细化基本异常得分。因此,利用多尺度连续性模块通过在不同时间尺度上移动平均来提取异常连续性。此外,多尺度关注被应用于更好地整合不同尺度的信息,以增强所提出的MCR网络的鲁棒性。
Multi-Scale Continuity
如图3所示,池化算子用于对第j个剪辑执行多尺度移动平均算子,以获得新的平滑分数
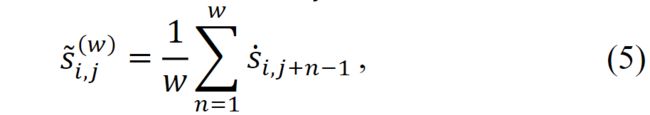
w 是移动平均的窗口大小。
值得注意的是,每个视频中的剪辑ki的数量不一致。此外,不同类型异常事件的持续时间也有很大差异。因此,固定的时间尺度显然是不合适的。在所提出的MCR网络中,使用不同的窗口大小生成候选得分向量组,而最合适的得分向量将在下一节中选择。
Multi-Scale Attention
为了从候选分数集![]() 中选择合适的尺度,引入了一个类似注意力的模块,根据每个视频的增强特征
中选择合适的尺度,引入了一个类似注意力的模块,根据每个视频的增强特征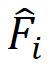 在不同尺度上分配适当的权重。
在不同尺度上分配适当的权重。
由于剪辑的数量ki因视频而异,因此采用自适应挤压步骤来合并连续剪辑的特征,如图3所示。之后,特征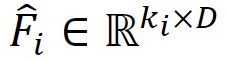 可以转移到
可以转移到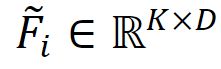 ,是一个超参数,在我们的实验中为32。另一个FC层接受
,是一个超参数,在我们的实验中为32。另一个FC层接受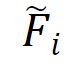 作为输入,然后是SoftMax层作为激活功能。通过这个过程,可以获得每个尺度的视频级别加权因子,这表示相应的平滑分数
作为输入,然后是SoftMax层作为激活功能。通过这个过程,可以获得每个尺度的视频级别加权因子,这表示相应的平滑分数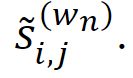 的重要性。然后该加权因子向量Pi可以形式化如下,
的重要性。然后该加权因子向量Pi可以形式化如下,
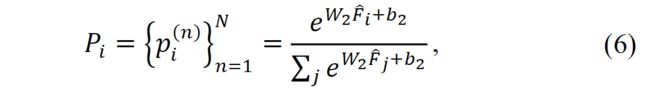
其中, , 表示权重因子的数量,该数量与标尺的数量相同。在我们的实验中设定为3。
, 表示权重因子的数量,该数量与标尺的数量相同。在我们的实验中设定为3。
通过将平滑的多尺度异常得分![]() 与权重
与权重 ![]() 相乘,第i个视频中第j个剪辑的最终异常得分
相乘,第i个视频中第j个剪辑的最终异常得分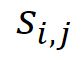 可以表示如下:
可以表示如下:
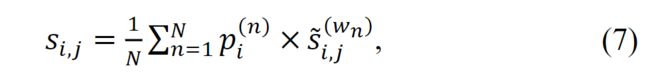
Optimization
使用最终得到的分数,进行优化 ,使用的分数同 ARNet:Dynamic multiple instances of learning (DMIL) loss and center loss
EXPERIMENTS

Ablation study
对比不同尺度的性能
