统计全球每年的最高/最低气温
文章目录
- 数据准备
-
- 1.下载数据
- 2.处理数据
-
- 1.在linux本地目录中创建一个文件夹ncdc
- 2.去下载的目录,然后把数据复制到ncdc中
- 3.解压文件gzip -d *.op.gz
- 4.输出数据到data.txt
- 5.上传到hdfs中
- 一、统计全球每年的最高气温和最低气温
-
- 实现思路
- 1.YearMaxTAndMinT
- 2.Mapper:MaxTAndMinTMapper
- 3.Combiner:MaxTAndMinTCombiner
- 4.Reducer:MaxTAndMinTReducer
- 5.运行代码:MaxTAndMinT.java
- 6.输出结果
- 二、筛选气温在15~25°C之间的数据
-
- 1.MTAMTMapper类
- 2.MTAMTReducer类
- 3.MTAMT类
- 4.输出结果
- 总结
数据准备
先启动hadoop,然后打开eclipse
1.下载数据
打开虚拟机从:ftp://ftp.ncdc.noaa.gov/pub/data/gsod 上下载2014~2016年的数据

2.处理数据
1.在linux本地目录中创建一个文件夹ncdc
cd /usr/loacl
madir /data
cd /usr/loacl/data
mkdir /ncdc
2.去下载的目录,然后把数据复制到ncdc中

3.解压文件gzip -d *.op.gz

4.输出数据到data.txt
在/usr/local/data目录下创建一个文件data.txt
cd /usr/local/data
vim data.txt
![]()
cd /usr/local/data/ncdc
回到ncdc目录执行命令 来删除所有文件的首行字段sed -i ‘1d’ *
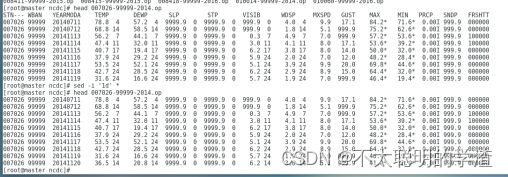
将内容写入data.txt文件当中
cat *>>…/data.txt

查看了一下数据

5.上传到hdfs中
hdfs dfs -put data.txt /user/temperature

一、统计全球每年的最高气温和最低气温
实现思路
(1)自定义一个数据类型YearMaxTAndMinT来继承Writable接口,在这个类里定义字符串类型的变量year,定义double类型的变量maxTemp和minTemp,获取get()和set()方法。
(2)创建一个Mapper,命名为MaxTAndMinTMapper,获取年份和气温,年份为key,气温为value输出
(3)创建一个Combiner,命名为MaxTAndMinTCombiner,获取年份最高气温和最低气温,年份为key,气温为value输出
(4)创建一个Reducer,命名为MaxTAndMinTReducer,也是获取年份最高气温和最低气温,并创建一个YearMaxTAndMinT对象,按最高气温和最低气温分别设置maxTemp和minTemp的值。将YearMaxTAndMinT最为value,NullWritable.get()作为key输出
(5)创建运行代码,创建一个驱动类MaxTAndMinT.java
代码如下:
1.YearMaxTAndMinT
package temperature;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class YearMaxTAndMinT implements Writable{
private String year;
private double maxTemp;
private double minTemp;
public YearMaxTAndMinT() {
}
public String getYear() {
return year;
}
public void setYear(String year) {
this.year = year;
}
public double getMaxTemp() {
return maxTemp;
}
public void setMaxTemp(double maxTemp) {
this.maxTemp = maxTemp;
}
public double getMinTemp() {
return minTemp;
}
public void setMinTemp(double minTemp) {
this.minTemp = minTemp;
}
@Override
public void readFields(DataInput in) throws IOException {
this.year=in.readUTF();
this.maxTemp=in.readDouble();
this.minTemp=in.readDouble();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(year);
out.writeDouble(maxTemp);
out.writeDouble(minTemp);
}
@Override
public String toString() {
return this.year+"\t"+this.maxTemp+"\t"+this.minTemp;
}
}
2.Mapper:MaxTAndMinTMapper
package temperature;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTAndMinTMapper extends Mapper<LongWritable, Text, Text, DoubleWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString().trim();
int[] indexs = getIndexs(line);// 获取年份和气温数据的索引范围
String year = getYear(line, indexs);// 获取年份
double airTemperature;
String temperature = getTemperature(line, indexs);
if (temperature.charAt(0) == '-') { // 每行数据中带 - 号的气温数据做负数处理
airTemperature = 0-Double.parseDouble(temperature.substring(1));// 获取气温数值
} else {
airTemperature = Double.parseDouble(temperature);// 获取气温数值
}
context.write(new Text(year), new DoubleWritable(airTemperature));
}
//获取年份
public String getYear(String line,int[] indexs){
return line.substring(indexs[1], indexs[2]).replace(" ", "").substring(0, 4);
}
//获取气温
public String getTemperature(String line,int[] indexs){
return line.substring(indexs[2],indexs[3]).replace(" ", "");
}
//获取年份和气温的索引范围
public int[] getIndexs(String line){
int[] indexs = new int[4];
int n=0;
for(int i=0;i < line.length();i++){
if(line.charAt(i) == ' '){
if(line.charAt(i+1) != ' '){
indexs[n++]=i+1;
}
if(n == 4){
break;
}
}
}
return indexs;
}
}
3.Combiner:MaxTAndMinTCombiner
package temperature;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTAndMinTCombiner extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
@Override
protected void reduce(Text key, Iterable<DoubleWritable> values,
Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context) throws IOException, InterruptedException {
double maxValue = Double.MIN_VALUE;// 获取整形最大值
double minValue=Double.MAX_VALUE;// 获取最小值
for (DoubleWritable value : values) {
maxValue = Math.max(maxValue, value.get());// 获取最高温度
minValue=Math.min(minValue, value.get());// 获取最低温度
}
context.write(key, new DoubleWritable(maxValue));
context.write(key, new DoubleWritable(minValue));
}
}
4.Reducer:MaxTAndMinTReducer
package temperature;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTAndMinTReducer extends Reducer<Text, DoubleWritable, NullWritable,YearMaxTAndMinT> {
private YearMaxTAndMinT year_max_min=new YearMaxTAndMinT();
@Override
protected void reduce(Text key, Iterable<DoubleWritable> values,
Reducer<Text, DoubleWritable, NullWritable,YearMaxTAndMinT>.Context context)
throws IOException, InterruptedException {
double maxValue = Double.MIN_VALUE;// 获取整形最大值
double minValue=Double.MAX_VALUE;// 获取最小值
for (DoubleWritable value : values) {
maxValue = Math.max(maxValue, value.get());// 获取最高温度
minValue=Math.min(minValue, value.get());
}
year_max_min.setYear(key.toString());
year_max_min.setMaxTemp(maxValue);
year_max_min.setMinTemp(minValue);
context.write(NullWritable.get(),year_max_min);
}
}
5.运行代码:MaxTAndMinT.java
package temperature;
import java.io.IOException;
import java.nio.file.FileSystem;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import test.JarUtil;
public class MaxTAndMinT extends Configured implements Tool{
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job MaxTAndMinTJob = Job.getInstance(conf,"max min");
//重要:指定本job所在的jar包
MaxTAndMinTJob.setJarByClass(MaxTAndMinT.class);
//设置wordCountJob所用的mapper逻辑类为哪个类
MaxTAndMinTJob.setMapperClass(MaxTAndMinTMapper.class);
//设置wordCountJob所用的reducer逻辑类为哪个类
MaxTAndMinTJob.setReducerClass(MaxTAndMinTReducer.class);
//设置map阶段输出的kv数据类型
MaxTAndMinTJob.setMapOutputKeyClass(Text.class);
MaxTAndMinTJob.setMapOutputValueClass(DoubleWritable.class);
//设置最终输出的kv数据类型
MaxTAndMinTJob.setOutputKeyClass(NullWritable.class);
MaxTAndMinTJob.setOutputValueClass(YearMaxTAndMinT.class);
MaxTAndMinTJob.setCombinerClass(MaxTAndMinTCombiner.class);
//设置要处理的文本数据所存放的路径
FileInputFormat.setInputPaths(MaxTAndMinTJob, new Path("hdfs://master:8020/user/temperature/data.txt"));
FileOutputFormat.setOutputPath(MaxTAndMinTJob, new Path("hdfs://master:8020/user/output/temperature"));
//提交job给hadoop集群
MaxTAndMinTJob.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
//获取当前环境变量
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:8020");// 指定namenode
//使用ToolRunner的run方法对自定义的类型进行处理
conf.set("mapreduce.job.jar",JarUtil.jar(MaxTAndMinT.class));
try {
ToolRunner.run(conf, new MaxTAndMinT(), args);
} catch (Exception e) {
e.printStackTrace();
}
}
}
6.输出结果

二、筛选气温在15~25°C之间的数据
一般来说,最适合人类生存的温度是15~25°C,所以我们要筛选出这些数据
代码如下:
1.MTAMTMapper类
package between;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
public class MTAMTMapper extends Mapper<LongWritable, Text, Text, DoubleWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString().trim();
int[] indexs = getIndexs(line);// 获取年份和气温数据的索引范围
String year = getYear(line, indexs);// 获取年份
double airTemperature;
String temperature = getTemperature(line, indexs);
if (temperature.charAt(0) == '-') { // 每行数据中带 - 号的气温数据做负数处理
airTemperature = 0-Double.parseDouble(temperature.substring(1));// 获取气温数值
} else {
airTemperature = Double.parseDouble(temperature);// 获取气温数值
}
context.write(new Text(year), new DoubleWritable(airTemperature));
}
//获取年份
public String getYear(String line,int[] indexs){
return line.substring(indexs[1], indexs[2]).replace(" ", "").substring(0, 4);
}
//获取气温
public String getTemperature(String line,int[] indexs){
return line.substring(indexs[2],indexs[3]).replace(" ", "");
}
//获取年份和气温的索引范围
public int[] getIndexs(String line){
int[] indexs = new int[4];
int n=0;
for(int i=0;i < line.length();i++){
if(line.charAt(i) == ' '){
if(line.charAt(i+1) != ' '){
indexs[n++]=i+1;
}
if(n == 4){
break;
}
}
}
return indexs;
}
}
2.MTAMTReducer类
package between;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
public class MTAMTReducer extends Reducer<Text,DoubleWritable,Text,DoubleWritable>{
protected void reduce(Text key, Iterable<DoubleWritable> values,Context context) throws IOException, InterruptedException {
String date=key.toString();
for(DoubleWritable value:values) {
if(value.get()>=15 && value.get()<=25) {
if(date.contains("2014")|| date.contains("2015")|| date.contains("2016")) {
context.write(key,new DoubleWritable(value.get()));
}
}
}
}
}
3.MTAMT类
package between;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import test.JarUtil;
public class MTAMT extends Configured implements Tool{
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job MTAMTJob = Job.getInstance(conf,"15~25°C");
//重要:指定本job所在的jar包
MTAMTJob.setJarByClass(MTAMT.class);
//设置wordCountJob所用的mapper逻辑类为哪个类
MTAMTJob.setMapperClass(MTAMTMapper.class);
//设置wordCountJob所用的reducer逻辑类为哪个类
MTAMTJob.setReducerClass(MTAMTReducer.class);
//设置map阶段输出的kv数据类型
MTAMTJob.setMapOutputKeyClass(Text.class);
MTAMTJob.setMapOutputValueClass(DoubleWritable.class);
//设置最终输出的kv数据类型
MTAMTJob.setOutputKeyClass(Text.class);
MTAMTJob.setOutputValueClass(DoubleWritable.class);
MTAMTJob.setNumReduceTasks(2);
//设置要处理的文本数据所存放的路径
FileInputFormat.setInputPaths(MTAMTJob, new Path("hdfs://master:8020/user/temperature/data.txt"));
FileOutputFormat.setOutputPath(MTAMTJob, new Path("hdfs://master:8020/user/output/temperature2"));
//提交job给hadoop集群
MTAMTJob.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
//获取当前环境变量
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:8020");
//使用ToolRunner的run方法对自定义的类型进行处理
conf.set("mapreduce.job.jar",JarUtil.jar(MTAMT.class));
try {
ToolRunner.run(conf, new MTAMT(), args);
} catch (Exception e) {
e.printStackTrace();
}
}
}
4.输出结果

总结
以上就是全部内容,欢迎大家在评论区讨论