【实战案例】表情分类&人脸表情识别
“来源:投稿 作者:LSC
编辑:学姐
本篇文章的内容是从表情分类,到完成人脸表情识别,理论穿插实战代码。分为两部分,第一部分为表情分类实战;第二部分为人脸表情识别案例实战。
第一部分
1.表情分类实战简介

-
数据集: 表情数据集,可分为无表情、撅嘴、微笑、张嘴四类。
-
样本个数: 训练样本13598,验证样本1509
-
使用网络: resnet,multiscale-resnet
分类表情数据
-
无表情0none:4763 训练集4287 测试集476
-
嘟嘴1pouting:3154 训练集2839 测试集315
-
微笑2smile:4841 训练集4357 测试集484
-
大笑3openmouth:2348 训练集2114 测试集234
训练数据:13597
测试数据:1509
格式:统一为128*128,jpg图像
训练模型要求:
(1) 输入大小统一为:96*96
(2) 最后一层特征输出大小为3*3,分类类别为4,使用迁移学习
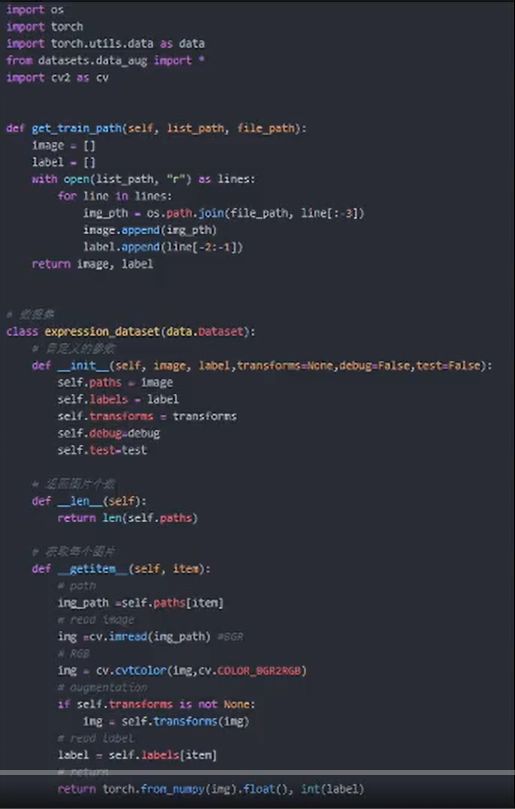
2.表情分类实战数据集读取
使用torch.utils.data里的data函数实现编写过程;
分为_init_、_len_、_getitem_三个模块;
_init_完成某些参数的初始定义;
len 获取数据集的总数;
getitem 读取每幅图像和标签。
3.数据增强
可以自行编写,也可以使用torchvision.transform
4.网络搭建
可以自行编写,也可以使用torchvision.models中的模型
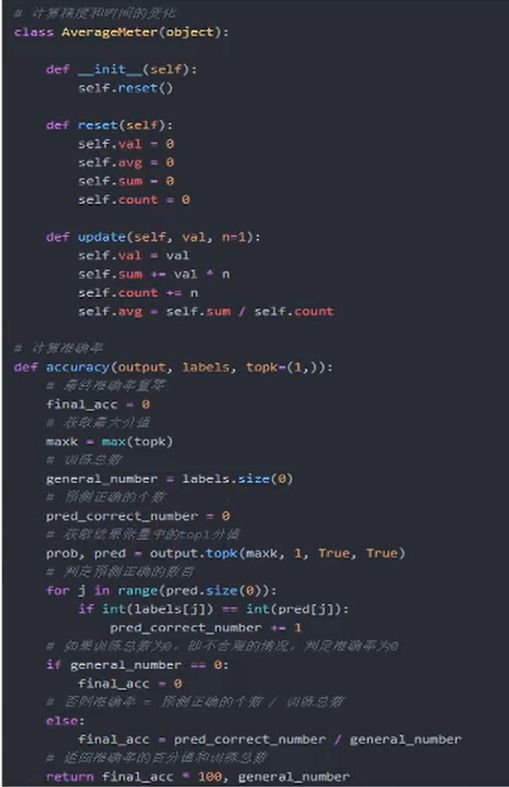
5.正确率计算
评价指标记录函数的编写,主要为分类准确率.
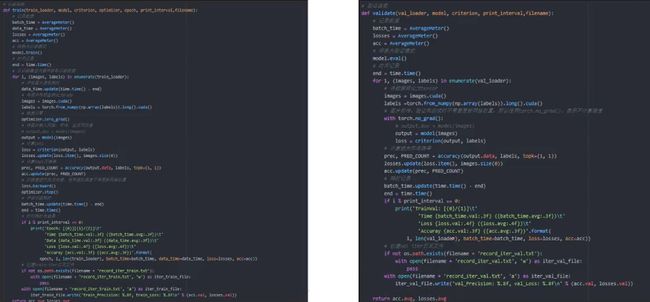
6.训练和验证函数
第二部分
人脸表情识别案例
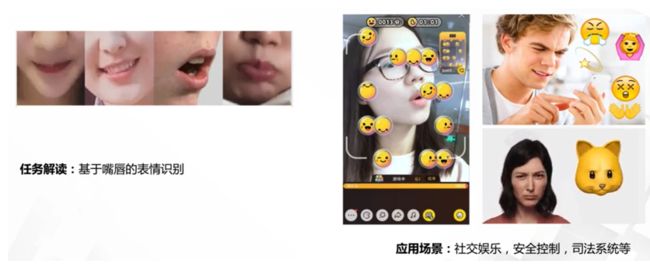
1.1任务——表情识别
从零开始整理数据,使用pytorch从零开始搭建表情识别模型
1.2 一个完整的工业级项目流程
从数据整理到模型验证
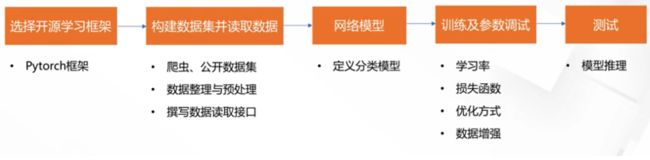
1.3.1数据获取的常见方法
数据集(ImageNet等 数据质量高 成本低) 外包(阿里众包等 大规模 成本高) 自采集(自己采集或者爬虫 成本低 速度快)
1.3.2开源数据集
表情数据集: KDEF, RaFD, RAF, EMotioNet等
人脸数据集: Celaba等

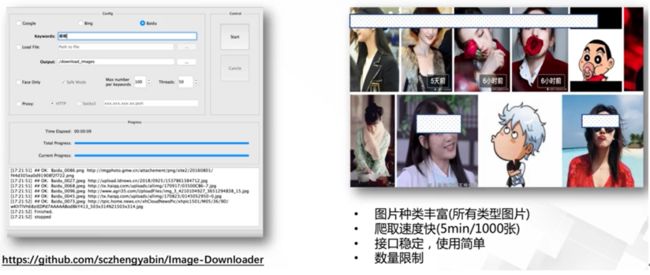
1.3.3爬虫获取
用于准备小型的数据集(10000以内),图片来源主要是搜索引擎,快速获取第一批数据用于验证方案。
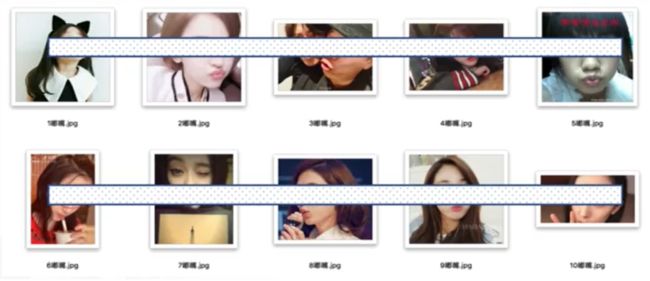
1.4.1数据预处理——归一化
-
去除损坏图片,防止读取失败
-
类型归一化(方便遍历,*.jpg | .*png,统一压缩方式)
-
去除尺寸异常图片(如长宽比大于10)
-
命名归一化(方便归类)
# 数据读取
def listfiles(rootDir):
list_dirs = os.walk(rootDir)
for root, dirs, files in list_dirs:
for d i dirs:
print(os.path.join(root, d))
for f in files:
fileid = f.split('.')[0]
filepath = os.path.join(root, f)
try:
src = cv2.imread(filepath, 1)
print("src = ", filepath, src.shape)
os.remove(filepath)
cv2.imwrite(os.path.join(root, fileid + '.jpg'), src)
except:
os.remove(filepath)
continue
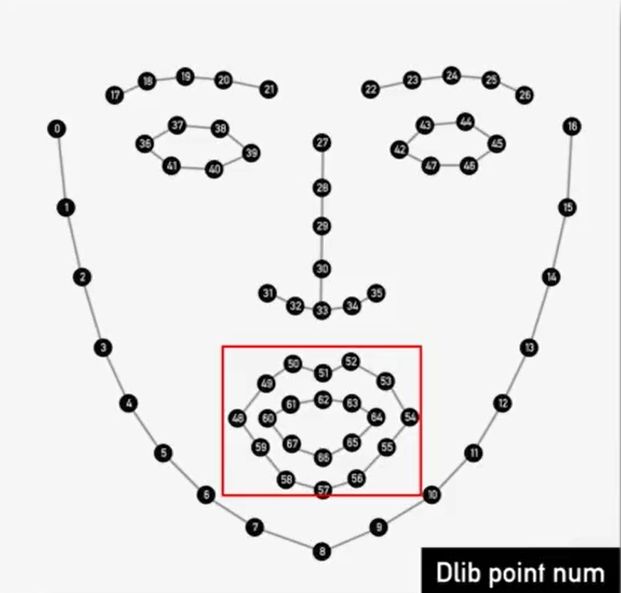
1.4.2数据预处理——人脸检测
OpenCv人脸检测,Dlib关键点检测,将嘴唇区域裁剪并适当扩大区域。
# 人脸检测
cascade_path = 'haarcascade_frontalface_default.xml'
cascade = cv2.CascadeClassifier(cascade_path)
#关键点检测
PREDICTOR_PATH = "shape_predictor_68_face_landmarks.dat"
predictor = dlib.shape_predictor(PREDICTOR_PATH)
def get_landmarks(im):
rects = cascade.detectMultiScale(im, 1.3, 5)
x, y, w, h = rects[0]
rect = dlib.rectangle(int(x), int(y), int(x + w), int(y + h))
return np.matrix([[p.x, p.y] for p in predictor(im, rect).parts()])
#提取出嘴唇区域,并适当扩大区域
for i in range(48, 67):
x = landmarks[i, 0]
y = landmarks[i, 1]
1.5数据集大小
15000多张图,包含微笑,嘟嘴,大笑,无表情4类
按9:1均匀划分为训练集和测试集,格式统一为128*128,jpg图像。

2.1图像分类任务,通过torchvision包来读取数据
import torchvision.dataset as dataset
data_dir = './data' # 数据目录
data = dataset.ImageFolder(data_dir, data_transform) # ImageFolder接口
dataloader = data.DataLoader(data) # 数据指针
Train和val文件夹都包含4个类的子文件夹,自动被torchvision转成标签。
2.2 数据增强方法
添加随机缩放裁剪,随机翻转,去均值方差归一化操作。
transforms.RandomSizedCrop(48),将输入图进行随机裁剪,尺度由面积比参数scale控制,长宽比由ratio控制,然后缩放为48*48。
transforms.RandomHorizontalFlip()以0.5的概率进行随机翻转。
2.3数据指针
使用data.DataLoader获得数据指针
data_dir = './data/'
# 分别读取'../data/train'.和'./data/val'文件夹
image_datasets = {x:dataset.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
# 设置batchsize大小为4,数据读取线程为1,使用随机打乱操作
dataloaders = {x: torch.util.data.DataLoader(image_datasets[x], batch_size = 16, shuffle = True, num_workers = 4) for x in ['train', 'val']}
2.4 定义一个简单的网络,由3个卷积层,3个BN层,3个全连接层构成
# 网络搭建
calss Net(nn.Module, nclass):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 12, 3, 2)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(12, 24, 3, 2)
self.bn2 = nn.BatchNorm2d(24)
self.conv3 = nn.Conv2d(24, 48, 3, 2)
self.bn2 = nn.BatchNorm2d(48)
self.fc1 = nn.Linear(48 * 5 * 5, 1200) # conv3的输出为48 * 5 * 5
self.fc2 = nn.Linear(1200, 128)
self.fc3 = nn.Linear(128, nclass) # 输出Tensor尺寸[batch, 1, 1, nclass]
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = x.view(-1, 48 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
2.5 优化目标与方法
优化目标: 交叉熵损失
优化方法: 带动量的SGD算法(Momentum算法)
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(modelclc.parameters(), lr = 0.1, momentum = 0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size = 100, gamma = 0.1) # 学习率迭代策略
模型定义与训练
model = Net(4)
model = train_model(model = model, criterion = criterion, optimizer = optimizer_ft,
scheduler = exp_lr_scheduler, num_epochs = 500)
2.6训练迭代
每一次epoch,包含数据batch数据迭代
def train_model(model, criterion, optimizer, scheduler, num_epochs = 25):
for epoch in range(num_epochs):
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
model.train(True)
else:
model.train(False)
running_loss = 0.0
running_corrects = 0.0
for data in dataLoader[phase]:
inputs, labels = data
if use_gpu = True:
inputs = inputs.cuda()
labels = labels.cuda()
optimizer.zero_grad() # 梯度清零
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
if phase = "train":
loss.backward() # 误差反向传播
optimizer.step() # 参数更像
2.7 可视化
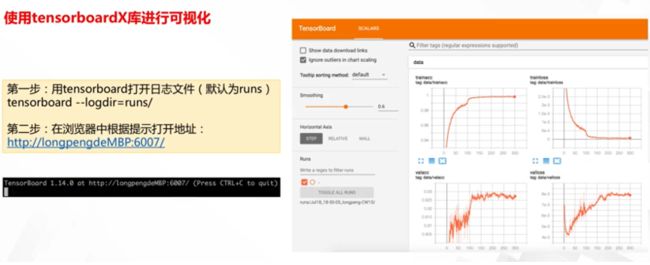
使用tensorboardX库进行可视化
# 记录需要可视化的变量
for tersorboardX import SummaryWriter
writer = SummaryWriter()
# 每一个batch
if phase == 'train':
writer.add_scaler('data/trainloss', epoch_loss, epoch)
writer.add_scaler('data/trainacc', epoch_acc, epoch)
else:
writer.add_scaler('data/trainloss', epoch_loss, epoch)
writer.add_scaler('data/trainacc', epoch_acc, epoch)
# 每一个epoch
writer.export_scalars_to_json('./all_scalars.json')
writer.close()
第一步,用tensorboardX打开日志文件(默认为runs) tensorboard --logdir=runs/
第二步,在浏览器根据提示打开地址: http://longpengdeMBP:6007/
2.8测试
# 测试
# 载入预训练模型,前向推理获得预测结果
form net import Net
Net.load_state_dict(torch.load(modelpath, map_location = lambda storage, loc:storage))
Net.eval() # 设置为推理模式,不会更新模型的k, b参数
torch.no_grad() # 停止autograd模块的工作,加速和节省显存
# 定义数据预处理
testsize = 48 # 测试图大小
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
# 前向推理获得结果,读取数据,填充数据维度
image = Image.open(imagepath)
imgblob = data_transfroms(img).unsqueeze(0)
predict = F.softmax(Net(imgblob))
imdex = np.argmax(predict.detach().numpy())
# 使用OpenCv的rectangle函数和putText函数将结果绘制到图像
# 绘制框与文本
pos_x = int(offsetx + roisize)
pos_y = int(offsety + roisize)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.rectangle(im, (offsetx), offsety), (pos_x, pos_y), (0, 255, 0), 2)
if index == 0:
cv2.putText(im, 'none', (pos_x, pos_y), font, 1,2, (0, 255, 255), 1)
elif index == 1:
cv2.putText(im, 'pouting', (pos_x, pos_y), font, 1,2, (0, 255, 255), 1)
elif index == 2:
cv2.putText(im, 'smile', (pos_x, pos_y), font, 1,2, (0, 255, 255), 1)
else:
cv2.putText(im, 'open', (pos_x, pos_y), font, 1,2, (0, 255, 255), 1)
关注卡片,回复"CVPR"领取500+篇经典CV论文