Flink基础系列19-实现UDF
文章目录
- 一. 函数类(Function Classes)
- 二. 匿名函数(Lambda Functions)
- 三.富函数(Rich Functions)
- 参考:
一. 函数类(Function Classes)
Flink暴露了所有UDF函数的接口(实现方式为接口或者抽象类)。例如MapFunction, FilterFunction, ProcessFunction等等。
下面例子实现了FilterFunction接口:
DataStream<String> flinkTweets = tweets.filter(new FlinkFilter());
public static class FlinkFilter implements FilterFunction<String> {
@Override public boolean filter(String value) throws Exception {
return value.contains("flink");
}
}
还可以将函数实现成匿名类
DataStream<String> flinkTweets = tweets.filter(
new FilterFunction<String>() {
@Override public boolean filter(String value) throws Exception {
return value.contains("flink");
}
}
);
我们filter的字符串"flink"还可以当作参数传进去。
DataStream<String> tweets = env.readTextFile("INPUT_FILE ");
DataStream<String> flinkTweets = tweets.filter(new KeyWordFilter("flink"));
public static class KeyWordFilter implements FilterFunction<String> {
private String keyWord;
KeyWordFilter(String keyWord) {
this.keyWord = keyWord;
}
@Override public boolean filter(String value) throws Exception {
return value.contains(this.keyWord);
}
}
二. 匿名函数(Lambda Functions)
Lambda 函数是真的简洁,不过没办法传参
DataStream<String> tweets = env.readTextFile("INPUT_FILE");
DataStream<String> flinkTweets = tweets.filter( tweet -> tweet.contains("flink") );
三.富函数(Rich Functions)
“富函数”是DataStream API提供的一个函数类的接口,所有Flink函数类都有其Rich版本。
它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
- RichMapFunction
- RichFlatMapFunction
- RichFilterFunction
- …
Rich Function有一个生命周期的概念。典型的生命周期方法有:
- open()方法是rich function的初始化方法,当一个算子例如map或者filter被调用之前open()会被调用。
- close()方法是生命周期中的最后一个调用的方法,做一些清理工作。
- getRuntimeContext()方法提供了函数的RuntimeContext的一些信息,例如函数执行的并行度,任务的名字,以及state状态
public static class MyMapFunction extends RichMapFunction<SensorReading, Tuple2<Integer, String>> {
@Override public Tuple2<Integer, String> map(SensorReading value) throws Exception {
return new Tuple2<>(getRuntimeContext().getIndexOfThisSubtask(), value.getId());
}
@Override public void open(Configuration parameters) throws Exception {
System.out.println("my map open"); // 以下可以做一些初始化工作,例如建立一个和HDFS的连接
}
@Override public void close() throws Exception {
System.out.println("my map close"); // 以下做一些清理工作,例如断开和HDFS的连接
}
}
测试代码:
package org.flink.transform;
/**
* @author 只是甲
* @date 2021-08-31
* @remark Flink 基础Transform RichFunction
*/
import org.flink.beans.SensorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformTest5_RichFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
DataStream<String> inputStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkStudy\\src\\main\\resources\\sensor.txt");
// 转换成SensorReading类型
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
DataStream<Tuple2<String, Integer>> resultStream = dataStream.map( new MyMapper() );
resultStream.print();
env.execute();
}
// 传统的Function不能获取上下文信息,只能处理当前数据,不能和其他数据交互
public static class MyMapper0 implements MapFunction<SensorReading, Tuple2<String, Integer>> {
@Override
public Tuple2<String, Integer> map(SensorReading value) throws Exception {
return new Tuple2<>(value.getId(), value.getId().length());
}
}
// 实现自定义富函数类(RichMapFunction是一个抽象类)
public static class MyMapper extends RichMapFunction<SensorReading, Tuple2<String, Integer>> {
@Override
public Tuple2<String, Integer> map(SensorReading value) throws Exception {
// RichFunction可以获取State状态
// getRuntimeContext().getState();
return new Tuple2<>(value.getId(), getRuntimeContext().getIndexOfThisSubtask());
}
@Override
public void open(Configuration parameters) throws Exception {
// 初始化工作,一般是定义状态,或者建立数据库连接
System.out.println("open");
}
@Override
public void close() throws Exception {
// 一般是关闭连接和清空状态的收尾操作
System.out.println("close");
}
}
}
测试记录:
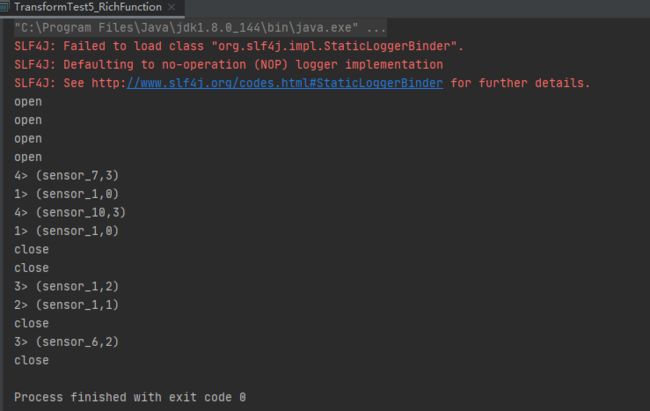
如下图可以看到,我们开了4个并行,所以会有>1 >2 >3 >4,也会有4个"open"和"close",另外进程号是从0开始,所以 sensor_*后面跟的是 0,1,2,3 共4个。
参考:
- https://www.bilibili.com/video/BV1qy4y1q728
- https://ashiamd.github.io/docsify-notes/#/study/BigData/Flink/%E5%B0%9A%E7%A1%85%E8%B0%B7Flink%E5%85%A5%E9%97%A8%E5%88%B0%E5%AE%9E%E6%88%98-%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0?id=_521-%e4%bb%8e%e9%9b%86%e5%90%88%e8%af%bb%e5%8f%96%e6%95%b0%e6%8d%ae