实体关系抽取几篇论文
1、《A Unified MRC Framework for Named Entity Recognition》
paper:https://arxiv.org/pdf/1910.11476.pdf
code:https://github.com/ShannonAI/mrc-for-flat-nested-ner
摘要:提出了一种基于MRC的框架提高了Flat NER和Nested NER的准确率,尤其是在Nested NER上效果的提升。
模型:基于阅读理解式的就需要构造query获得answer,先看query的构造:

这种query是实体类别的一种描述,尽可能的通用和精确,可以使用解释概念或者提及。这种构造query的方式加入了标签的先验知识。
模型输入(基于bert):
![]()
Span selection:
有两种形式:
一、使用两个 n-class 分类器,其中 n 表示输入序列『X』的长度,等同所有的 token 的数量,第一个 classifier 判断所有的 token 中哪个最有可能是 start index ,第二个 classifier 判断哪个最有可能是 end index 。由于,每个分类器都使用 softmax 作用于 X 的所有 token 上面,因此,只能得到单个范围的 span ;二、使用两个 binary 分类器,对每个token都进行预测,第一个 classifier 预测每个 token 是否是 start index ,第二个 classifier 预测每个 token 是否是 end index ,因此,这种策略允许输出多个 start index 和 end index ,这样就可以输出多个与 query 相关联的 span ,本文选择较为合理的第二种策略。
Start-End Matching
因为在文本中有同一个类别的多个实体(距离最近原则不适应嵌套的实体),我们需要找到匹配的起始位置。对于可能的start,end:
 加入一个二分类器来判断他们是否匹配:
加入一个二分类器来判断他们是否匹配:

损失函数:

**优点:**在query中加入了先验知识,可以解决Nested NER问题。
**缺点:**同一个样本要复制N(实体类别数目)次来构造所有实体类型的query。
2、《FLAT: Chinese NER Using Flat-Lattice Transformer》
paper:https://arxiv.org/pdf/2004.11795.pdf
code:https://github.com/LeeSureman/Flat-Lattice-Transformer
Lattice这种加入词汇信息的都属于词汇增强方式。
Lattice NER的缺点:
1、双向LSTM效率低,很难利用GPU并行计算;
2、只针对LSTM结构进行了改进,无法迁移至其他模型。
**摘要:**本文针对中文NER,提出了一种Flat-lattice Transformer结构,将lattice结构展平,利用transformer结构和精心设计的位置编码,能够充分利用lattice信息并有较好的并行能力。
Flat-Lattice框架:

这里为每一个token设计了head position and tail position。对于每一个字符,它的head和tail是相同的,对于一个词,head和tail分别为词的起始index。我们可以通过词典来获得所有字符的lattice,就可以将它扁平化了。
Spans的相对位置编码
Flat-lattice结构包含了不同长度的spans,为了编码每个span之间的内在联系,作者提出了spans的相对位置编码。对于在lattice中的2个span,xi xj,他们之间有三种关系,intersection ,inclusion and separation,是哪种关系取决于头和尾,论文使用一个Dense向量去建模他们的关系,而不是直接编码三种关系。它是通过头尾信息的连续变换来计算的, 由此,作者认为,这样不仅可以表示两个token之间的关系,还可以蕴含一些细节信息,比如,字符和词之间的距离。来看具体表示,Head[i]和tail[i]表示span x[i]的头和尾,4种距离可以表明x[i]和x[j]之间的关系:
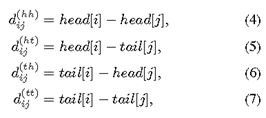
举个例子:
 最后span的相对位置编码是一个简单的四个距离的非线性变换:
最后span的相对位置编码是一个简单的四个距离的非线性变换:
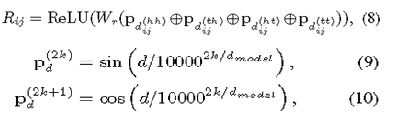
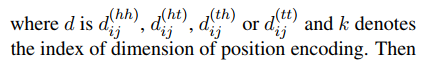
最后接一层CRF。
3、《A Novel Cascade Binary Tagging Framework for Relational Triple Extraction》
paper:https://arxiv.org/pdf/1909.03227.pdf
code:https://github.com/weizhepei/CasRel
摘要:提出了一种新的级联框架可以从句子中抽取多个关系三元组。
实体关系抽取中几种情况:

- Normal:一个实体参与一个关系
- EPO:同一对实体有两种不同的关系
- SEO:一个实体参与到多个关系中
针对上述问题,论文提出 a novel cascade binary tagging framework(CASREL)来解决,直接来看模型框架:

本模型使用bert进行编码,然后找出句子中所有可能的subject,subject的开始和结束都用1表示,不是边界的词用0表示,使用就近原则来确定subject。然后对于每一个subject,对subject_head和subject_tail做平均,加到bert的编码中,加一个n-class分类器,遍历每一种关系,同时识别关系和object,如果存在某种关系,则获得object的起始位置,如果不存在,则起始位置都是0,如上图。
4、《A Frustratingly Easy Approach for Joint Entity and Relation Extraction》
paper:https://arxiv.org/pdf/2010.12812.pdf
先来介绍两种实体提取方法:
- 片段排列+分类
对片段进行排列,排列所有可能提取的span,然后加softmax对每一个span进行分类。
因为选择了所有可能的span,所以解决了Nested NER问题。但是对于含有T个token的文本,理论上有N=T(T+1)/2种片段排列。如果文本过长,就会产生大量的负样本,在实际中需要限制span的长度合理消减负样本。 - 加入标志符信息
如图所示,在实体前后加入标志符,强化实体表征,然后将[E1]和[/E1]向量contact再进行关系分类。
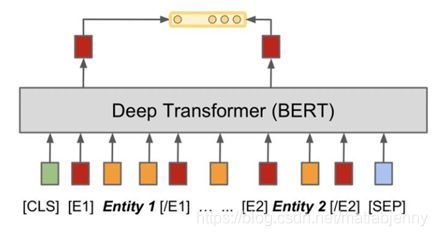
在这篇paper中,所采取的pipeline模型如下:

(a) Entity model: 片段排列+分类
(b) Relation model: 对所有的实体pair进行关系分类。其中最重要的一点改进,就是将实体边界和类型作为标识符加入到实体Span前后,然后作为关系模型的input。例如,对于实体pair(Subject和Object)可分别在其对应的实体前后插入以下标识符:和:代表实体类型为Method的Subject,S是实体span的第一个token,/S是最后一个token; 和:代表实体类型为Method的Object,O是实体span的第一个token,/O是最后一个token;对于关系模型,对每个实体pair中第一个token的编码进行concatenate,然后进行SoftMax分类。
(c) 近似模型
需要指出的是,上述实体模型和关系模型分别采取两个独立的预训练模型进行编码(不共享参数)。
对于这种关系模型,我们不难发现:对每个实体pair都要轮流进行关系分类,也就是同一文本要进行多次编码。
为解决这一问题,提出了一种加速的近似模型(如上图c所示):可将实体边界和类型的标识符放入到文本之后,然后与原文对应实体共享位置向量。上图中相同的颜色代表共享相同的位置向量。实验结果表明,这样可以提速8-16倍,对精度的损失只有一点点,可忽略。
cross-sentence
为了加入上下文特征,有的做法是将上下文中句子加入进来,比如加入上下文3个句子。本文作者认为,一个好的预训练模型有能力捕捉长距离信息,作者简单的将上下文固定窗口的信息加入到实体模型和关系模型。即在左右两端分别加入(W-n)/2个词信息,n为文本长度,W为窗口大小,论文中实验W=100.
从实验结果上看,本文提出的方法较其他方法提高很大,为什么有如此好的表现,作者也进行了分析:
1.实体和关系模型的上下文表示本质上捕获不同的信息,因此共享它们的表示会影响效果;
2.在关系模型的输入层融合实体信息(包括边界信息和类型信息)至关重要;
3.利用跨句(cross-sentence)信息在这两项任务中都很有用;
4.更强大的预先训练语言模型可以带来进一步的收益。
由此,作者期望这个简单的模型能作为一个很强的基线,让我们重新思考联合训练在端到端关系抽取中的价值。