Mybatis批量插入大量数据最优方式
Mybatis批量插入的方式有三种
1. 普通插入
2. foreach 优化插入
3. ExecutorType.BATCH插入
下面对这三种分别进行比较:
1.普通插入
默认的插入方式是遍历insert语句,单条执行,效率肯定低下,如果成堆插入,更是性能有问题。
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
sql log如下:
2022-08-30 05:26:02 [1125b8ff-dfa3-478e-bbee-29173babe5a7] [http-nio-3005-exec-2] [com.btn.common.config.MybatisSqlLoggerInterceptor]-[INFO] 拦截的sql ==>: com.btn.mapper.patient.PatientLabelDetailMapper.insert:INSERT INTO t_patient_label_detail ( patient_id, doctor_id, tag_id, patient_name, gender, age, create_by, create_time ) VALUES ( 337, 178, 251, '刘梅好', 2, 29, '178', )
2022-08-30 05:26:02 [1125b8ff-dfa3-478e-bbee-29173babe5a7] [http-nio-3005-exec-2] [com.btn.mapper.patient.PatientLabelDetailMapper.insert]-[DEBUG] ==> Preparing: INSERT INTO t_patient_label_detail ( patient_id, doctor_id, tag_id, patient_name, gender, age, create_by, create_time ) VALUES ( ?, ?, ?, ?, ?, ?, ?, ? )
2022-08-30 05:34:40 [215b2b99-b0c9-41f6-93b2-545c8d6ff0fb] [http-nio-3005-exec-2] [com.btn.common.config.MybatisSqlLoggerInterceptor]-[INFO] 拦截的sql ==>: com.btn.mapper.patient.PatientLabelDetailMapper.insert:INSERT INTO t_patient_label_detail ( patient_id, doctor_id, tag_id, patient_name, gender, age, create_by, create_time ) VALUES ( 256, 178, 253, '啊~吃西瓜', 0, 0, '178', )
2022-08-30 05:34:40 [215b2b99-b0c9-41f6-93b2-545c8d6ff0fb] [http-nio-3005-exec-2] [com.btn.mapper.patient.PatientLabelDetailMapper.insert]-[DEBUG] ==> Preparing: INSERT INTO t_patient_label_detail ( patient_id, doctor_id, tag_id, patient_name, gender, age, create_by, create_time ) VALUES ( ?, ?, ?, ?, ?, ?, ?, ? )
可以看到每个语句的执行创建一个新的预处理语句,单条提交sql,性能低下.
2.foreach 优化插入
如果要优化插入速度时,可以将许多小型操作组合到一个大型操作中。理想情况下,这样可以在单个连接中一次性发送许多新行的数据,并将所有索引更新和一致性检查延迟到最后才进行。
<insert id="batchInsert" parameterType="java.util.List">
insert into table1 (field1, field2) values
<foreach collection="list" item="t" index="index" separator=",">
(#{t.field1}, #{t.field2})
</foreach>
</insert>
翻译成sql语句也就是
INSERT INTO `table1` (`field1`, `field2`)
VALUES ("data1", "data2"),
("data1", "data2"),
("data1", "data2"),
("data1", "data2"),
("data1", "data2");
乍看上去这个foreach没有问题,但是经过项目实践发现,当表的列数较多(20+),以及一次性插入的行数较多(5000+)时,整个插入的耗时十分漫长,达到了14分钟,这是不能忍的。在资料中也提到了一句话:
Of course don’t combine ALL of them, if the amount is HUGE. Say you
have 1000 rows you need to insert, then don’t do it one at a time. You
shouldn’t equally try to have all 1000 rows in a single query. Instead
break it into smaller sizes.
它强调,当插入数量很多时,不能一次性全放在一条语句里。可是为什么不能放在同一条语句里呢?这条语句为什么会耗时这么久呢?我查阅了资料发现:
Insert inside Mybatis foreach is not batch, this is a single (could
become giant) SQL statement and that brings drawbacks:some database such as Oracle here does not support.
in relevant cases: there will be a large number of records to insert
and the database configured limit (by default around 2000 parameters
per statement) will be hit, and eventually possibly DB stack error if
the statement itself become too large.Iteration over the collection must not be done in the mybatis XML.
Just execute a simple Insertstatement in a Java Foreach loop. The most
important thing is the session Executor type.Unlike default ExecutorType.SIMPLE, the statement will be prepared
once and executed for each record to insert.
从资料中可知,默认执行器类型为Simple,会为每个语句创建一个新的预处理语句,也就是创建一个PreparedStatement对象。在我们的项目中,会不停地使用批量插入这个方法,而因为MyBatis对于含有的语句,无法采用缓存,那么在每次调用方法时,都会重新解析sql语句。
Internally, it still generates the same single insert statement with
many placeholders as the JDBC code above. MyBatis has an ability to
cache PreparedStatement, but this statement cannot be cached because
it contains element and the statement varies depending on
the parameters. As a result, MyBatis has to 1) evaluate the foreach
part and 2) parse the statement string to build parameter mapping [1]
on every execution of this statement.And these steps are relatively costly process when the statement
string is big and contains many placeholders.[1] simply put, it is a mapping between placeholders and the
parameters.
从上述资料可知,耗时就耗在,由于我foreach后有5000+个values,所以这个PreparedStatement特别长,包含了很多占位符,对于占位符和参数的映射尤其耗时。并且,查阅相关资料可知,values的增长与所需的解析时间,是呈指数型增长的。
foreach 遇到数量大,性能瓶颈
项目实践发现,当表的列数较多(超过20),以及一次性插入的行数较多(上万条)时,插入性能非常差,通常需要20分钟以上
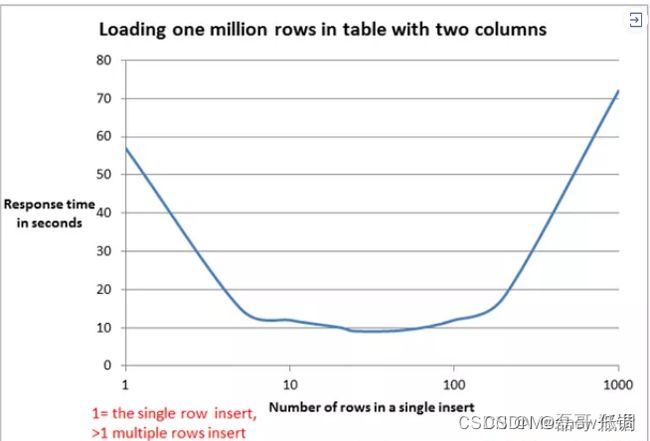
所以,如果非要使用 foreach 的方式来进行批量插入的话,可以考虑减少一条 insert 语句中 values 的个数,最好能达到上面曲线的最底部的值,使速度最快。一般按经验来说,一次性插20~50行数量是比较合适的,时间消耗也能接受。
此外Mysql 对执行的SQL语句大小进行限制,相当于对字符串进行限制。默认允许最大SQL是 4M 。
超过限制就会抛错:
com.mysql.jdbc.PacketTooBigException: Packet for query is too large (8346602 > 4194304). You can change this value on the server by setting the max_allowed_packet’ variable.
这个错误是 Mysql 的JDBC包抛出的,跟Mybatis框架无关, Mybatis 解析动态SQL的源码如下:
// 开始解析
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingChacheRefs();
parsePendingStatements();
}
// 解析mapper
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e);
}
}
// 创建 select|insert|update|delete 语句
private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
for (XNode context : list) {
final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
try {
statementParser.parseStatementNode();
} catch (IncompleteElementException e) {
configuration.addIncompleteStatement(statementParser);
}
}
}
// 填充参数,创建语句
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
for (Map.Entry<String, Object> entry : context.getBindings().entrySet()) {
boundSql.setAdditionalParameter(entry.getKey(), entry.getValue());
}
return boundSql;
}
从开始到结束, Mybatis 都没有对填充的条数和参数的数量做限制,是Mysql 对语句的长度有限制,默认是 4M。
3.ExecutorType.BATCH插入
Mybatis内置的ExecutorType有3种,SIMPLE、REUSE、BATCH; 默认的是simple,该模式下它为每个语句的执行创建一个新的预处理语句,单条提交sql;而batch模式重复使用已经预处理的语句,并且批量执行所有更新语句,显然batch性能将更优;但batch模式也有自己的问题,比如在Insert操作时,在事务没有提交之前,是没有办法获取到自增的id,这在某型情形下是不符合业务要求的.
JDBC 在执行 SQL 语句时,会将 SQL 语句以及实参通过网络请求的方式发送到数据库,一次执行一条 SQL 语句,一方面会减小请求包的有效负载,另一个方面会增加耗费在网络通信上的时间。通过批处理的方式,我们就可以在 JDBC 客户端缓存多条 SQL 语句,然后在 flush 或缓存满的时候,将多条 SQL 语句打包发送到数据库执行,这样就可以有效地降低上述两方面的损耗,从而提高系统性能。进行jdbc批处理时需在JDBC的url中加入rewriteBatchedStatements=true
不过,有一点需要特别注意:每次向数据库发送的 SQL 语句的条数是有上限的,如果批量执行的时候超过这个上限值,数据库就会抛出异常,拒绝执行这一批 SQL 语句,所以我们需要控制批量发送 SQL 语句的条数和频率.
使用Batch批量处理数据库,当需要向数据库发送一批SQL语句执行时,应避免向数据库一条条的发送执行,而应采用JDBC的批处理机制,以提升执行效率
//如果自动提交设置为true,将无法控制提交的条数,改为最后统一提交
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH,false);
PatientLabelDetailMapper patientLabelDetailMapper = sqlSession.getMapper(PatientLabelDetailMapper.class);
private int BATCH = 1000;
for (int index = 0; index < data.size(); index++) {
patientLabelDetailMapper.insert(data.get(i))
if (index != 0 && index % BATCH == 0) {
sqlSession .commit();
}
}
sqlSession.commit();
需要说明的是,很多博客文章都说在commit后需要调用sqlSession .clearCache()和sqlSession .flushStatements();,用以刷新缓存和提交到数据库,通过阅读源码,这两行大可不必写,源码解析如下:
public void commit(boolean required) throws SQLException {
if (this.closed) {
throw new ExecutorException("Cannot commit, transaction is already closed");
} else {
this.clearLocalCache();
this.flushStatements();
if (required) {
this.transaction.commit();
}
}
}
public void clearCache() {
this.executor.clearLocalCache();
}
源码commit()方法已经调用了clearLocalCache()和flushStatements(),
而clearCache()方法也是调用了clearLocalCache(),所以只需写commit()即可.
sql log日志分析如下:
2022-08-30 05:31:27 [0ed35173-ae5f-4ea5-a937-f771d33ae4bd] [http-nio-3005-exec-1] [com.btn.common.config.MybatisSqlLoggerInterceptor]-[INFO] 拦截的sql ==>: com.btn.mapper.patient.PatientLabelDetailMapper.insert:INSERT INTO t_patient_label_detail ( patient_id, doctor_id, tag_id, patient_name, gender, age, create_by, create_time ) VALUES ( 337, 178, 252, '刘梅好', 2, 29, '178', )
2022-08-30 05:31:27 [0ed35173-ae5f-4ea5-a937-f771d33ae4bd] [http-nio-3005-exec-1] [com.btn.mapper.patient.PatientLabelDetailMapper.insert]-[DEBUG] ==> Preparing: INSERT INTO t_patient_label_detail ( patient_id, doctor_id, tag_id, patient_name, gender, age, create_by, create_time ) VALUES ( ?, ?, ?, ?, ?, ?, ?, ? )
2022-08-30 05:31:27 [0ed35173-ae5f-4ea5-a937-f771d33ae4bd] [http-nio-3005-exec-1] [com.btn.common.config.MybatisSqlLoggerInterceptor]-[INFO] sql耗时 ==>: 2
2022-08-30 05:31:27 [0ed35173-ae5f-4ea5-a937-f771d33ae4bd] [http-nio-3005-exec-1] [com.btn.mapper.patient.PatientLabelDetailMapper.insert]-[DEBUG] ==> Parameters: 337(Long), 178(Long), 252(Long), 刘梅好(String), 2(Integer), 29(Integer), 178(String), null
2022-08-30 05:31:27 [0ed35173-ae5f-4ea5-a937-f771d33ae4bd] [http-nio-3005-exec-1] [com.btn.mapper.patient.PatientLabelDetailMapper.insert]-[DEBUG] ==> Parameters: 256(Long), 178(Long), 252(Long), 啊~吃西瓜(String), 0(Integer), 0(Integer), 178(String), null
ExecutorType.BATCH原理:把SQL语句发个数据库,数据库预编译好,数据库等待需要运行的参数,接收到参数后一次运行,ExecutorType.BATCH只打印一次SQL语句,预编译一次sql,多次设置参数步骤.
总结:
经过以上三种方式分析,在插入大数据量时优先选择第三种方式,
ExecutorType.BATCH插入