libcurl库的介绍和使用,并调用libcurl库编程访问百度主页
1.libcurl简介
libcurl是一个跨平台的网络协议库,支持七层网络模型中应用层的各种协议,例如http, https, ftp, gopher, telnet, dict, file, 和ldap 协议。libcurl同样支持HTTPS证书授权,HTTP POST, HTTP PUT, FTP 上传, HTTP基本表单上传,代理,cookies,和用户认证。
要实现http编程,就要借用libcurl库。
库下载链接:https://github.com/curl/curl/releases/tag/curl-7_71_1
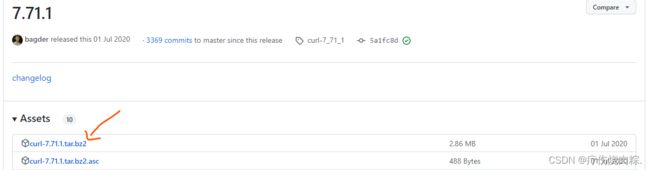
2.libcurl库的编译
1.首先将下载好的libcurl压缩包放到Ubuntu中
2.我这里创建了一个httpHandler文件夹,并拷贝到里面解压:
tar xvf curl-7.71.1.tar.bz2

3.解压后生成curl-7.71.1的文件夹,进去里面的docs文件夹直接打开INSTALL.md看看
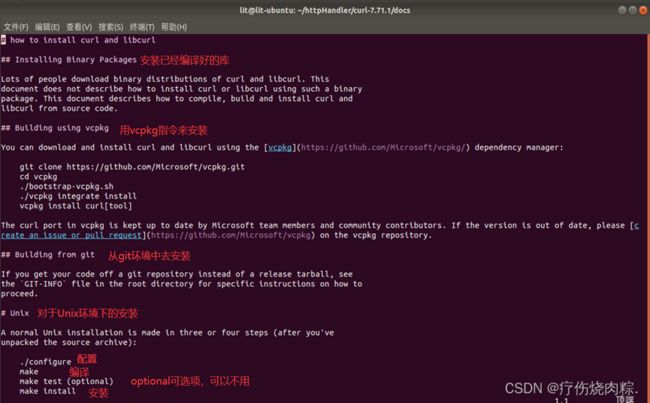
我们看到./configure后面没有跟任何参数,就表示是默认安装,这样的话我们就不知道文件安装到哪里去了,我们当然希望能指定文件夹安装
继续往下看:
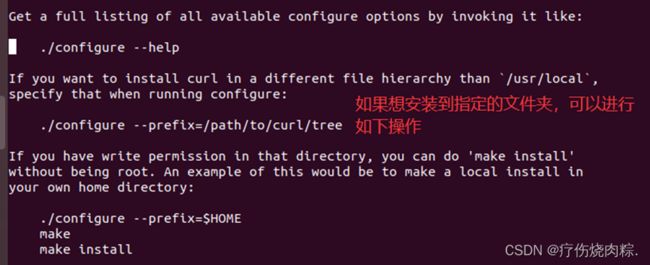
也就是说我们在linux环境下想要把开源包安装到指定目录下,后面要跟这个--prefix=想安装的路径
配置是否支持https:
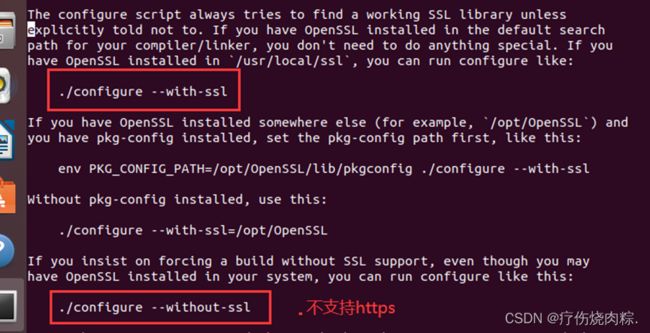
这里要介绍:
https和ssl有什么关系
他们之间的关系可以这样理解:https=http+ssl。即https的安全基础是ssl,如果想要对网站进行https加密访问,必须从受信任的CA机构颁发ssl证书,并部署到网站,才能实现。
网站安装了ssl证书,也就是实现了https加密。
要想编出来东西支持https的话,后面就得加with-ssl
4.回到/curl-7.71.1目录下,准备开始安装
(1) 配置为:$获取当前路径
./configure --prefix=$PWD/_install如果要进行交叉编译的配置,比如编译后在树莓派上用,则要:
./configure --prefix=$PWD/_install --host=arm-linux
这样,在ubuntu中就会使用arm-gcc进行编译
(2)make指令开始编译
(3)make install指令开始安装,会生成一个_install文件夹,并且把编译生成的东西全部放入里面。

(4)代码中我们会用到这些头文件
![]()
同样,程序编译时也需要链_install/lib里面的libcurl.so动态库(.a是静态库)

3.调用libcurl编程访问百度主页
介绍libcurl的使用
1.调用curl_global_init()初始化libcurl
CURLcode curl_global_init(long flags)
函数只能用一次。(其实在调用curl_global_cleanup 函数后仍然可再用)
如果这个函数在curl_easy_init函数调用时还没调用,它讲由libcurl库自动调用,所以多线程下最好主动调用该函数以防止在线程中curl_easy_init时多次调用。
注意:虽然libcurl是线程安全的,但curl_global_init是不能保证线程安全的,所以不要在每个线程中都调用curl_global_init,应该将该函数的调用放在主线程中。
参数:flags
2.调用curl_easy_init()函数得到 easy interface型指针(类似于socket函数返回的fd,fd也称为:句柄)
一般curl_easy_init意味着一个会话的开始. 它会返回一个easy_handle(CURL*对象), 一般都用在easy系列的函数中.
3.调用curl_easy_setopt()设置传输选项,操作这个句柄,操作哪些东西呢,比如要访问的网址,要传的参数等。
根据curl_easy_setopt()设置的传输选项,实现回调函数以完成用户特定任务,就是拿到数据后如何获取这个数据,比如可以写到一个文件或者数组中。
CURLcode curl_easy_setopt(CURL *handle, CURLoption option, parameter);
这个函数最重要了.几乎所有的curl 程序都要频繁的使用它.它告诉curl库.程序将有如何的行为. 比如要查看一个网页的html代码等.(这个函数有些像ioctl函数)参数:
1 CURL类型的指针
2 各种CURLoption类型的选项.(都在curl.h库里有定义,man 也可以查看到)
3 parameter 这个参数 既可以是个函数的指针,也可以是某个对象的指针,也可以是个long型的变量.它用什么这取决于第二个参数.
CURLoption 这个参数的取值很多.具体的可以查看man手册curl_easy_setopt函数部分选项介绍:
1. CURLOPT_URL
设置访问URL2. CURLOPT_WRITEFUNCTION,CURLOPT_WRITEDATA
回调函数原型为:size_t function( void *ptr, size_t size, size_t nmemb, void *stream); 函数将在libcurl接收到数据后被调用,因此函数多做数据保存的功能,如处理下载文件。CURLOPT_WRITEDATA 用于表明CURLOPT_WRITEFUNCTION函数中的stream指针的来源。3. CURLOPT_HEADERFUNCTION,CURLOPT_HEADERDATA
回调函数原型为 size_t function( void *ptr, size_t size,size_t nmemb, void *stream); libcurl一旦接收到http 头部数据后将调用该函数。CURLOPT_WRITEDATA 传递指针给libcurl,该指针表明CURLOPT_HEADERFUNCTION 函数的stream指针的来源。
4.调用curl_easy_perform()函数完成传输任务
5.调用curl_easy_cleanup()释放内存
具体使用看这里:Http协议之libcurl实现
结合以下示例代码 demo1.c 来访问百度主页
#include
#include
#include
#define true 1
#define false 0
typedef unsigned int bool;
size_t readData(void *ptr, size_t size, size_t nmemb, void *stream)
{
char buf[10240] = {'\0'};
strncpy(buf, ptr, 10240);
printf("=========================get Data=====================\n");
printf("%s\n",buf);
}
bool getUrl(char *filename)
{
CURL *curl;
CURLcode res;
FILE *fp;
if ((fp = fopen(filename, "w")) == NULL) // 返回结果用文件存储
return false;
struct curl_slist *headers = NULL;
headers = curl_slist_append(headers, "Accept: Agent-007");
curl = curl_easy_init(); // 初始化
if (curl)
{
//curl_easy_setopt(curl, CURLOPT_PROXY, "10.99.60.201:8080");// 代理
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, headers);// 改协议头
curl_easy_setopt(curl, CURLOPT_URL,"http://www.baidu.com");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, readData); //设置回调函数将返回数据打印出来开
//curl_easy_setopt(curl, CURLOPT_WRITEDATA, fp); //将返回的http头输出到fp指向的文件
//curl_easy_setopt(curl, CURLOPT_HEADERDATA, fp); //将返回的html主体数据输出到fp指向的文件
//就是说把百度访问的所有结果往filename里面写
res = curl_easy_perform(curl); // 执行,就是在访问百度
if (res != 0) {
curl_slist_free_all(headers);
curl_easy_cleanup(curl);
}
fclose(fp);
return true;
}
}
bool postUrl(char *filename)
{
CURL *curl;
CURLcode res;
FILE *fp;
if ((fp = fopen(filename, "w")) == NULL)
return false;
curl = curl_easy_init();
if (curl)
{
curl_easy_setopt(curl, CURLOPT_COOKIEFILE, "/tmp/cookie.txt"); // 指定cookie文件
curl_easy_setopt(curl, CURLOPT_POSTFIELDS, "&logintype=uid&u=xieyan&psw=xxx86"); // 指定post内容
//curl_easy_setopt(curl, CURLOPT_PROXY, "10.99.60.201:8080");
curl_easy_setopt(curl, CURLOPT_URL, " http://mail.sina.com.cn/cgi-bin/login.cgi "); // 指定url
curl_easy_setopt(curl, CURLOPT_WRITEDATA, fp);
res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
fclose(fp);
return true;
}
int main(void) //用get和post两种方法来请求网页
{
getUrl("/tmp/get.html");
postUrl("/tmp/post.html");
}
编译:
gcc demo1.c -I ./curl-7.71.1/_install/include/ -L ./curl-7.71.1/_install/lib/ -lcurl
编译的时候,这里要注意要链接库和头文件
-I (大写i) 来指定头文件的路径;
-L (大写l) 来指定路径去寻找库文件;
编译后直接./a.out是会报错的,原因是我们没有添加环境变量,输入如下指令添加就好了,指令忘了可以百度
export LD_LIBRARY_PATH=./curl-7.71.1/_install/lib/
程序运行的时候会默认去/usr/lib/下去找库,这种外面下载进来的库里面当然是找不到的,所以我们需要多添加一个找库的路径,这就是添加环境变量。
打印结果如下:
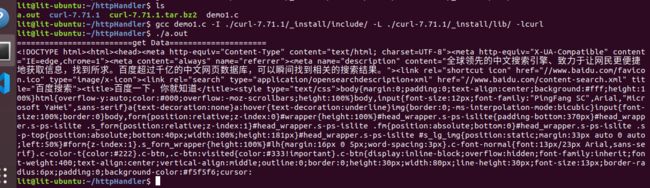
下篇文章会介绍怎么根据以上代码结合翔云平台来实现两张图片的人脸识别:翔云平台编程实现两张图片的人脸识别