记录DSGN++环境配置过程
论文介绍
DSGN++: Exploiting Visual-Spatial Relation for Stereo-based 3D Detectors

DSGN面临的问题:
1.PSV通道数过小,导致3D特征表示能力差
2.只对俯视图进行特征提取和使用(3DGV——(x,y,z))
3.类别不平衡(目标检测任务都有)
基于DSGN做出的改进:
1.提出Depth-wise PV(此处没懂怎么就Depth-wise了?),未增加通道个数,在保证了计算效率的情况下又不影响特征的局部性
2.使用前视图和俯视图联合提取特征
3.数据增强方法复制-粘贴策略)
Kitti准确率
应该算是目前双目里排名最高的方法了吧

更新日志
10.11 完成图像预处理(Step 2)内容
10.12 论文汇报
尽快训练
11.11 尝试使用waymo测试、使用自己采集数据测试
错误
以下按时间顺序对报错内容逐个列举(Error8 需要事先考虑)
1 ImportError:
按照Github步骤运行第二步时,会报如下错误:
ImportError: /home/trainer/dsgn2/pcdet/ops/roiaware_pool3d/roiaware_pool3d_cuda.cpython-38-x86_64-linux-gnu.so: undefined symbol: _ZNK2at6Tensor8data_ptrIfEEPT_v
解决方法
python setup.py develop
或者可以先配置环境再运行他的第二步

2 spconv包报错
ImportError: cannot import name 'VoxelGenerator' from 'spconv.utils
按照之前的链接修改data_processor.py等一众文件(这里应该只改了两个)
Update: 经历了一些报错后,spconv再次出错,修改spconv_backbone.py
此时缺少文件,所以在/pcdet/utils路径下添加spconv_utils.py文件(文件应该可以去Openpdet里找,我直接copy了SFD中的文件)
TypeError
经历上述修改后,还会报错:TypeError: __init__() missing 1 required positional argument: 'num_point_features'
修改pcdet/dataset/stereo_dataset_template.py文件,修改方式同github中pcdet/datasets/dataset.py的修改方式
3 OSError:
问题
报如下错误:OSError: [Errno 95] Operation not supported: '../../tools' -> '/home/yangtongyu/main/DSGN2-main/mmdetection-v2.22.0/mmdet/.mim/tools'
也就是setup.py文件报错,奇了怪之前也不报错,不知道改了个什么,就开始了
此处提醒:去看.pkl文件含义!!
解决
细看是软链接出错,猜测是windows没权限的问题,我比较特殊,是Linux挂载windows硬盘,所以猜测是本地磁盘不支持软连接的缘故。
174行 os.symlink(src_relpath, tar_path)
OSError: [Errno 95] Operation not supported: '../../tools' -> '/home/yangtongyu/main/DSGN2-main/mmdetection-v2.22.0/mmdet/.mim/tools'
[end of output]
149行 改为copy复制方式,不使用软链接
mode = 'copy'
4 缺少setuptools
ModuleNotFoundError: No module named 'setuptools.command.build'
解决
pip install -U pip setuptools
5 TypeError
运行python -m pcdet.datasets.kitti.lidar_kitti_dataset create_kitti_infos时出现的,完全就是我个人忘记在ImageSet里放.txt文件了。
TypeError: 'NoneType' object is not iterable
也找到了之前修改ImageSet的.txt文件,训练集或测试集数量不变的原因。
6 FileNotFoundError
问题
运行Step2第二行python -m pcdet.datasets.kitti.lidar_kitti_dataset create_gt_database_only --image_crops 报错
FileNotFoundError: The directory '/home/yangtongyu/main/DSGN2-main/data/kitti/gt_database/images' does not exist
解决
在 /home/yangtongyu/main/DSGN2-main/data/kitti/gt_database目录下创建文件夹images,没错就是这么简单,应该是大佬目录那里没写全吧。
之后的test集也会出现类似错误,我先把data目录放在这里。生成时间略长,放一张运行结果图。

7 ImportError:
总是自动找到别的路径下相同名字的文件,运行以下
print(sys.path)
['', '/home/yangtongyu/software/anaconda3/envs/cp_dsgn/lib/python38.zip', '/home/yangtongyu/software/anaconda3/envs/cp_dsgn/lib/python3.8', '/home/yangtongyu/software/anaconda3/envs/cp_dsgn/lib/python3.8/lib-dynload', '/home/yangtongyu/software/anaconda3/envs/cp_dsgn/lib/python3.8/site-packages', '/home/yangtongyu/software/anaconda3/envs/cp_dsgn/lib/python3.8/site-packages/spconv-2.1.24-py3.8-linux-x86_64.egg', '/home/yangtongyu/software/anaconda3/envs/cp_dsgn/lib/python3.8/site-packages/setuptools-59.8.0-py3.8.egg', '/home/yangtongyu/software/anaconda3/envs/cp_dsgn/lib/python3.8/site-packages/cumm-0.2.9-py3.8-linux-x86_64.egg', '/home/yangtongyu/SFD/SFD-main', '/home/yangtongyu/SFD/SFD-main/pcdet/ops/iou3d/cuda_op', '/home/yangtongyu/main/DSGN2-main/mmdetection-v2.22.0', '/home/yangtongyu/main/DSGN2-main']
对其进行永久修改的方式:
找到/home/yangtongyu/software/anaconda3/envs/cp_dsgn/lib/python3.8/site-packages/easy-install.pth文件,在里面修改文件路径优先查找顺序或删除。
8 RuntimeError:
RuntimeError: CUDA out of memory. Tried to allocate 722.00 MiB (GPU 0; 23.70 GiB total capacity; 21.76 GiB already allocated; 463.94 MiB free; 21.97 GiB reserved in total by PyTorch)
首先,看一下batch_size=1时,代码所占显存的截图,需要17G啊,真就是尼玛离谱。

看来真的有必要学习一下分布式训练啊
非分布式命令如下:
python tools/train.py --cfg_file ./configs/stereo/kitti_models/dsgn2.yaml --batch_size 1
结果
放两张使用它提供的.pth的运行结果作为记录


代码详细记录
训练过程: train.py中的main函数
1.args:命令行输入参数, cfg:从配置文件中读取到的字典
2.建立一些输入输出文件
3.创建dataloader & network & optimizer
# dataloader
# network
# 初始化 ['backbone_3d', 'map_to_bev_module', 'backbone_2d', 'dense_head_2d', 'dense_head', 'depth_loss_head', 'voxel_loss_head']
/DSGN2-main/pcdet/datasets/augmentor/stereo_database_sampler.py 数据采样
5. 数据增强
6. 构建模型
7. 训练
8. …
在feature_backbone中使用resnet提取特征的过程:
restnet.py中:
line690 def forward(self, x):
"""Forward function.""" # torch.Size([1, 3, 320, 1248])
if self.deep_stem:
x = self.stem(x)
else:
x = self.conv1(x)
x = self.norm1(x)
x = self.relu(x)
if self.with_max_pool:
x = self.maxpool(x)
outs = []
for i, layer_name in enumerate(self.res_layers):
res_layer = getattr(self, layer_name)
x = res_layer(x) # res_layer构建['layer1', 'layer2', 'layer3', 'layer4']
if i in self.out_indices:
outs.append(x)
return tuple(outs)
dsgn_backbone.py
这个应该的是最主要的文件了吧,以下记录几个坐标转换的过程,虽然还是看不懂。
原文作者注释:PSV with coordinates (u,v,d) --> 3D voxel grid with coordinates (x,y,z)
# line 503
Voxel = F.grid_sample(out, norm_coord_imgs, align_corners=True)
# out.shape torch.Size([1, 32, 72, 80, 312])
# norm_coord_imgs torch.Size([1, 20, 304, 288, 3])
# Voxel torch.Size([1, 32, 304, 288, 3])
先看一下PSV(out) 从何而来
# line 422
out = all_costs[-1]
其中的cost是对左右特征图求的cost volumn,这里似乎是调用了封装好的函数,看不到代码,把[1, 96, 320, 1248]维度的左右图像输入,就得到了[1, 64, 72, 80, 312]维度的输出。至于为什么选择这些维度,我一概不知。
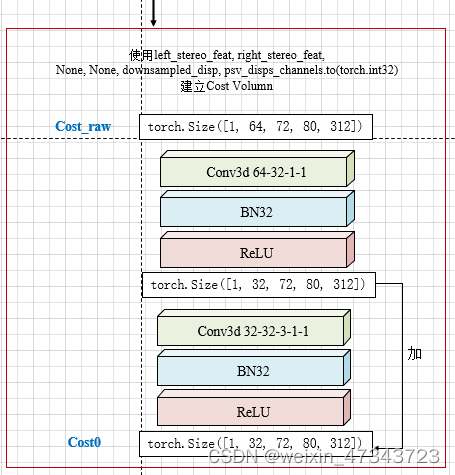
接着是norm_coord_imgs ,它是由coordinates_3d(由点云的范围计算出的)生成的,