flink实时消费kafka中oracle的DML数据写入mysql
1.需要环境
zookeeper,小编安装环境为zookeeper-3.4.10
kakfa,小编安装环境为kafka_2.13-2.8.0
kafka-connect-oracle,此为kafka-connect的oracle实时同步开源工程,源码地址:
https://github.com/erdemcer/kafka-connect-oracle
confluent,小编安装环境为confluent-5.3.1,下载链接:
https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
2.搭建说明
多种方式可以实现实时监听数据库DDL操作,小编选择通过如上三个组件,zookeeper、kafka、confluent搭建,另也可通过debezium的方式去搭建环境,感兴趣的可以再详细了解,confluent操作如下。
*2.1、*必须开启oracle归档日志。
*2.2、*基于oracle logminer的解析方式,对源库有一定影响,影响在5%以内。
*2.3、*上传jar包到/xxx/xx/xx/confluent/share/java/kafka-connect-jdbc:kafka-connect-oracle-1.0.jar,ojdbc7.jar,jsqlparser-1.2.jar,其中kafka-connect-oracle-1.0.jar为第一步kafka-connect-oracle源码jar包
*2.4、*cd /xxxx/xxxxx/confluent/etc/kafka-connect-jdbc 增加OracleSourceConnector.properties,内容如下:
name=oracle-logminer-connector
connector.class=com.ecer.kafka.connect.oracle.OracleSourceConnector
db.name.alias=mscdw
tasks.max=1
topic=oracletokafka
db.name=orcl
db.hostname=ip
db.port=port
db.user=user
db.user.password=password
db.fetch.size=1
table.whitelist=MSCDW.*,MSCDW.CONFIG
parse.dml.data=true
reset.offset=false
start.scn=
multitenant=false
table.blacklist=
*2.5、*cd /xxxx/xxxxx/confluent/etc/schema-registry, 修改schema-registry下connect-avro-standalone.properties文件,内容如下
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
*2.6、*启动,按顺序执行
启动zookeeper
sh zkServer.sh start
停止zookeeper
sh zkServer.sh stop
启动kafka
/home/kafka/kafka_2.13-2.8.0/bin/kafka-server-start.sh /home/kafka/kafka_2.13-2.8.0/config/server.properties &
关闭kafka
/home/kafka/kafka_2.13-2.8.0/bin/kafka-server-stop.sh /home/kafka/kafka_2.13-2.8.0/config/server.properties &
启动zookeeper和kafka后,进入confluent下,通过如下命令监听oracle数据ddl
./bin/connect-standalone ./etc/schema-registry/connect-avro-standalone.properties ./etc/kafka-connect-jdbc/OracleSourceConnector.properties
通过如下命令查看topic为oracletokafka的数据变化状态
./kafka-console-consumer.sh --bootstrap-server 172.16.50.22:9092 --topic oracletokafka --from-beginning
3.结果演示
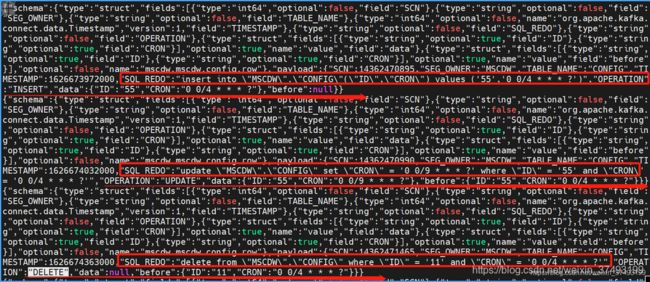
如图所示,可以捕捉到DML操作类型OPERATION:insert、update、delete,对于update而言,data为修改后数据,before为修改前数据。
 4.引言
4.引言
当拿到kafka监听oralce的DML语句时,可以搭配flink实现数据的sink,将DML语句解析实时同步计算到任意数据库,如果是同数据源之间的数据同步,小编建议直接做主从,如果是不同数据源的同步,那通过以上方式再搭配flink确实很高效。
5.flink的sink
网盘链接,有对应的组件环境以及个人手册记录:
https://pan.baidu.com/s/15rM84nK0bRcHKYO28KorBg
提取码:gaq0
5.1、首先,小编flink版本使用1.13.1
5.2、其次,贴出一些需要用到的jar
<properties>
<java.version>1.8</java.version>
<fastjson.version>1.2.75</fastjson.version>
<druid.version>1.2.5</druid.version>
<flink.version>1.13.1</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<HikariCP.version>3.2.0</HikariCP.version>
<kafka.version>2.8.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.flink.json</groupId>
<artifactId>flink-json</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka</artifactId>
<version>2.11-1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime_2.11</artifactId>
<version>${flink.version}**</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}**</version>
</dependency>
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>${HikariCP.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.2</version>
</dependency>
</dependencies>
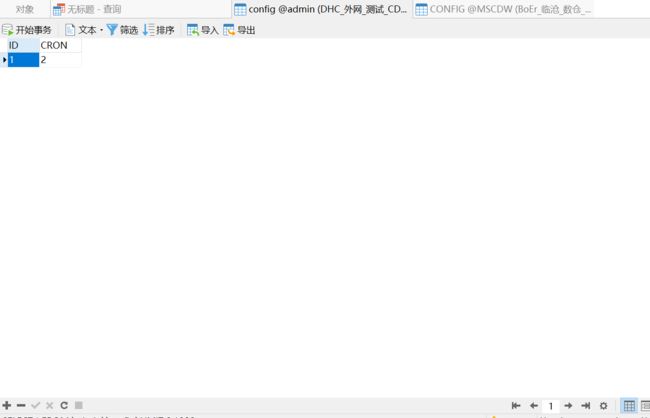
5.3、贴出小编使用的测试表
oracle: mysql:
mysql:
 5.4、贴出flink-sql:
5.4、贴出flink-sql:
sink:
CREATE TABLE sinkMysqlConfig
(
ID VARCHAR,
CRON VARCHAR
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://xxx:xxx/xxx',
'connector.table' = 'xxx',
'connector.username' = 'xxx',
'connector.password' = 'xxx',
'connector.write.flush.max-rows' = '1'
);
source:
CREATE TABLE sourceOracleConfig (
payload ROW(SCN string,SEG_OWNER string,TABLE_NAME string,data ROW(ID string,CRON string))
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'xxx',
'connector.startup-mode' = 'earliest-offset',
'connector.properties.group.id' = 'xxx',
'connector.properties.zookeeper.connect' = 'xxx:2181',
'connector.properties.bootstrap.servers' = 'xxx:9092',
'format.type' = 'json',
'format.json-schema' = --json format
'{
"type": "object",
"properties":
{
"payload":
{type: "object",
"properties" :
{
"SCN" : {type:"string"},
"SEG_OWNER" : {type:"string"},
"TABLE_NAME" : {type:"string"},
"data":
{type : "object",
"properties":
{
"ID" : {type : "string"},
"CRON" : {type : "string"}
}
}
}
}
}
}'
);
5.5、flinksqlclient演示,可跳过此步骤

5.6、贴出代码流程
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env,settings);
String sourceKafkaTable = String.format("CREATE TABLE sourceOracleConfig (\n" +
" payload ROW(SCN string,SEG_OWNER string,TABLE_NAME string,data ROW(ID string,CRON string))\n" +
") WITH (\n" +
" 'connector.type' = 'kafka',\n" +
" 'connector.version' = 'universal', \n" +
" 'connector.topic' = 'xxx', \n" +
" 'connector.startup-mode' = 'earliest-offset', \n" +
" 'connector.properties.group.id' = 'xxx',\n" +
" 'connector.properties.zookeeper.connect' = 'ip:2181',\n" +
" 'connector.properties.bootstrap.servers' = 'ip:9092',\n" +
" 'format.type' = 'json',\n" +
" 'format.json-schema' = --json format\n" +
" '{\n" +
" \"type\": \"object\",\n" +
" \"properties\": \n" +
" {\n" +
" \"payload\":\n" +
" {type: \"object\",\n" +
" \"properties\" : \n" +
" {\n" +
"\t\t\t\t\t\t\"SCN\" \t\t : {type:\"string\"},\n" +
"\t\t\t\t\t\t\"SEG_OWNER\" : {type:\"string\"},\n" +
"\t\t\t\t\t\t\"TABLE_NAME\" : {type:\"string\"},\n" +
"\t\t\t\t\t\t\"data\": \n" +
"\t\t\t\t\t\t{type : \"object\", \n" +
" \"properties\": \n" +
" {\n" +
" \t\"ID\" : {type : \"string\"},\n" +
" \"CRON\" : {type : \"string\"}\n" +
" }\n" +
" \t\t}\n" +
" \t\t }\n" +
" }\n" +
" }\n" +
" }'\n" +
")");
String sinkMysqlTable = String.format(
"CREATE TABLE sinkMysqlConfig \n" +
"(\n" +
" ID VARCHAR,\n" +
" CRON VARCHAR\n" +
") WITH (\n" +
" 'connector.type' = 'jdbc', \n" +
" 'connector.url' = 'jdbc:mysql://ip:port/xxx', \n" +
" 'connector.table' = 'xxx',\n" +
" 'connector.username' = 'xxx',\n" +
" 'connector.password' = 'xxx', \n" +
" 'connector.write.flush.max-rows' = '1' \n" +
")");
System.out.println(sourceKafkaTable+"\n"+sinkMysqlTable);
tableEnv.executeSql(sourceKafkaTable);
tableEnv.executeSql(sinkMysqlTable);
String sql = "insert into sinkMysqlConfig select payload.data.ID,payload.data.CRON from sourceOracleConfig";
tableEnv.executeSql(sql);
env.execute("FlinkSourceOracleSyncKafkaDDLSinkMysqlJob");
5.7、结果演示
当在oracle中新增数据后,发现mysql中对应表数据同步过来,自此oracle-mysql的数据同步测试demo验证完毕。最后打包将任务提交在flink web中。