熟练掌握Tensor的基本操作
来源:AI有温度
本文介绍了张量的创建、维度、索引、视图等常用操作与基本概念,帮助大家熟练掌握Tensor的使用技巧!
一、张量的创建与类型
张量最基本创建方法和Numpy中创建Array的格式一致,都是创建函数的格式。
1.1 通过列表创建
t = torch.tensor([1, 2])
print(t)
# tensor([1, 2])1.2 通过元组创建
t = torch.tensor((1, 2))
print(t)
# tensor([1, 2])1.3 通过Numpy创建
import numpy as np
n = np.array([1, 2])
t = torch.tensor(n)
print(t)
# tensor([1, 2])1.4 张量的类型
type()不能识别出Tensor内部的数据类型,只能识别出变量的基本类型是Tensor,而dtype方法可以识别出变量具体为哪种类型的Tensor。
i = torch.tensor([1, 2])
f = torch.tensor([1.0, 2.0])
print(type(i), i.dtype, sep = ' , ')
print(type(f), f.dtype, sep = ' , ')
# , torch.int64
# , torch.float32 1.5 张量类型的转化方法
可以使用.float()、.int()等方法对张量类型进行转化。
t = torch.tensor([1, 2])
f = t.float()
print(f)
print(t)
# tensor([1., 2.])
# tensor([1, 2])需要注意的是,这里并不会改变原来t的数据类型。
二、张量的维度
张量的维度中,我们使用的张量如下:
# 一维向量
t1 = torch.tensor((1, 2))
# 二维向量
t2 = torch.tensor([[1, 2, 3], [4, 5, 6]])
# 三维向量
t3 = torch.tensor([[[1, 2], [3, 4]],[[5, 6], [7, 8]]])2.1 ndim查看张量维度
print(t1.ndim, t2.ndim, t3.ndim, sep = ', ')
# 1, 2, 3
# t1为1维向量
# t2为2维矩阵
# t3为3维张量2.2 shape&size查看向量的形状
print(t1.shape, t2.shape, t3.shape, sep = ', ')
# torch.Size([2]), torch.Size([2, 3]), torch.Size([2, 2, 2])
print(t1.size(), t2.size(), t3.size(), sep = ', ')
# torch.Size([2]), torch.Size([2, 3]), torch.Size([2, 2, 2])t1向量torch.Size([2])的理解:向量的形状是1行2列。
t2矩阵torch.Size([2, 3])的理解:包含两个一维向量,每个一维向量的形状是1行3列。
t3矩阵torch.Size([2, 2, 2])的理解:包含两个二维矩阵,每个二维矩阵的形状是2行2列。
2.3 numel查看张量中的元素个数
print(t1.numel(), t2.numel(), t3.numel(), sep = ', ')
# 2, 6, 8
# t1向量中共有2个元素
# t2矩阵中共有6个元素
# t3张量中共有8个元素2.4 flatten将任意维度张量转为一维张量
t2.flatten()
# tensor([1, 2, 3, 4, 5, 6])
t3.flatten()
# tensor([1, 2, 3, 4, 5, 6, 7, 8])2.5 reshape任意变形
形变维度的乘积需要等于张量元素的个数。
# 将`t3`变成2×4的矩阵
t3.reshape(2, 4)
#tensor([[1, 2, 3, 4],[5, 6, 7, 8]])
# 将`t3`变成1×4×2的矩阵
t3.reshape(1, 4, 2)
# tensor([[[1, 2], [3, 4], [5, 6], [7, 8]]])2.6 squeeze&unsqueeze
squeeze的作用是压缩张量,去掉维数为1位置的维度
# 将t3的维度变为2×1×4
t_214 = t3.reshape(2, 1, 4)
print(t_214)
# tensor([[[1, 2, 3, 4]], [[5, 6, 7, 8]]])
# 使用squeeze将其变成2×4,去掉维度为1位置的维度
t_24 = t_214.squeeze(1)
print(t_24)
# tensor([[1, 2, 3, 4], [5, 6, 7, 8]])unsqueeze的作用是解压张量,给指定位置加上维数为一的维度。
# 将2×4的维度再转换成2×1×4,在第二个维度上加一维
# 索引是从0开始的。参数0代表第一维,参数1代表第二维,以此类推
print(t_24.unsqueeze(1))
tensor([[[1, 2, 3, 4]], [[5, 6, 7, 8]]])2.7 特殊的零维张量
Tensor的零维张量只包含一个元素,可以理解为标量,只有大小,没有方向。
# 零维张量的创建只有一个数,不具备一维或多维的概念
t0 = torch.tensor(1)
# 因为它是标量,所以维度是0
print(t0.ndim)
# 0
# 因为它是标量,所以也不具有形状
print(t0.shape)
# torch.Size([])
# 它没有维度,但是有一个数
print(t0.numel())
# 12.8 .item():标量转化为数值
在很多情况下,我们需要将最终计算的结果张量转为单独的数值进行输出。
n = torch.tensor(1)
print(n)
# tensor(1)
# 使用.item()方法将标量转为python中的数值
n.item()
# 12.8 什么是张量
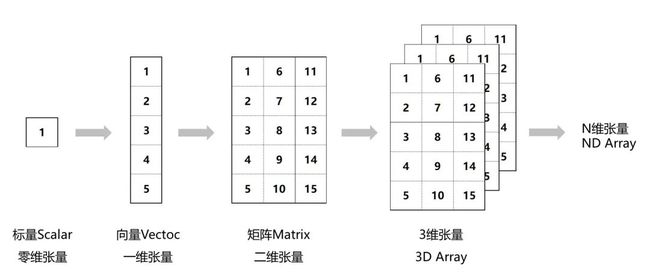
Tensor是一个多维数组,它是标量、向量、矩阵的高维拓展。
三、张量的索引
3.1 张量的符号索引
张量是有序序列,我们可以根据每个元素在系统内的顺序位置,来找出特定的元素,也就是索引。
一维张量索引与Python中的索引一样是是从左到右,从0开始的,遵循格式为[start: end: step]。
t1 = torch.arange(1, 11)
t1
# tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 取出索引位置是0的元素
t1[0]
# tensor(1)注:张量索引出的结果是零维张量,而不是单独的数。要转化成单独的数还需使用上节介绍的item()方法。
可理解为构成一维张量的是零维张量,而不是单独的数。
3.2 张量的step必须大于0
但在张量中,step必须大于1,否则就会报错。
t1 = torch.arange(1, 11)
t1[ ::-1]
# ValueError: step must be greater than zero3.3 二维张量的索引
二维张量的索引逻辑和一维张量的索引逻辑相同,二维张量可以视为两个一维张量组合而成。
t2 = torch.arange(1, 17).reshape(4, 4)
t2
#tensor([[ 1, 2, 3, 4],
# [ 5, 6, 7, 8],
# [ 9, 10, 11, 12],
# [13, 14, 15, 16]])t2[0,1]也可用t2[0][1]的表示。
# 表示索引第一行、第二个(第二列的)元素
t2[0, 1]
# tensor(2)
t2[0][1]
# tensor(2)但是t2[::2, ::2]与t2[::2][ ::2]的索引结果就不同:
t2[::2, ::2]
# tensor([[ 1, 3],
# [ 9, 11]])
t2[::2][::2]
# tensor([[1, 2, 3, 4]])t2[::2, ::2]二维索引使用逗号隔开时,可以理解为全局索引,取第一行和第三行的第一列和第三列的元素。
t2[::2][::2]二维索引在两个中括号中时,可以理解为先取了第一行和第三行,构成一个新的二维张量,然后在此基础上又间隔2并对所有张量进行索引。
tt = t2[::2]
# tensor([[ 1, 2, 3, 4],
# [ 9, 10, 11, 12]])
tt[::2]
# tensor([[1, 2, 3, 4]])3.4 三维张量的索引
设三维张量的shape是x、y、z,则可理解为它是由x个二维张量构成,每个二维张量由y个一维张量构成,每个一维张量由z个标量构成。
t3 = torch.arange(1, 28).reshape(3, 3, 3)
t3
# tensor([[[ 1, 2, 3],
# [ 4, 5, 6],
# [ 7, 8, 9]],
# [[10, 11, 12],
# [13, 14, 15],
# [16, 17, 18]],
# [[19, 20, 21],
# [22, 23, 24],
# [25, 26, 27]]])
# 索引第二个矩阵中的第二行、第二个元素
t3[1, 1, 1]
# tensor(14)
# 索引第二个矩阵,行和列都是每隔两个取一个
t3[1, ::2, ::2]
# tensor([[10, 12],
# [16, 18]])高维张量的思路与低维一样,就是围绕张量的“形状”进行索引。
3.5 张量的函数索引
在PyTorch中,我们还可以使用index_select函数指定index来对张量进行索引,index的类型必须为Tensor。
index_select(dim, index)表示在张量的哪个维度进行索引,索引的位值是多少。
t1 = torch.arange(1, 11)
indices = torch.tensor([1, 2])
# tensor([1, 2])
t1.index_select(0, indices)
# tensor([2, 3])注:这里取出的是位置,而不是取出[1:2]区间内左闭右开的元素。
3.6 二维张量的函数索引
t2 = torch.arange(12).reshape(4, 3)
t2
# tensor([[ 0, 1, 2],
# [ 3, 4, 5],
# [ 6, 7, 8],
# [ 9, 10, 11]])
t2.shape
# torch.Size([4, 3])
indices = torch.tensor([1, 2])
t2.index_select(0, indices)
# tensor([[3, 4, 5],
# [6, 7, 8]])此时dim参数取值为0,代表在shape的第一个维度上进行索引,即在向量维度进行索引。
在PyTorch中很多函数都采用的是第几维的思路,后面会介绍给大家,大家还需勤加练习,适应这种思路。同时使用函数式索引,在习惯后对代码可读性会有很大提升。
在此,我强烈建议阅读:干货|深入理解数据的维度,读后你一定会对维度有新的认识,与维度相关的操作都能信手捏来。
四、张量的合并与分割
4.1 张量的分割
chunk(tensor, chunks, dim)能够按照某个维度dim对张量进行均匀切分chunks,并且返回结果是原张量的视图。
还不了解视图的同学,点击进行学习
# 创建一个4×3的矩阵
t2 = torch.arange(12).reshape(4, 3)
t2
# tensor([[ 0, 1, 2],
# [ 3, 4, 5],
# [ 6, 7, 8],
# [ 9, 10, 11]])在第0个维度(shape的第一个数字,代表向量维度)上将t2进行4等分:
# 在矩阵中,第一个维度是行,理解为shape的第一个数
tc = torch.chunk(t2, chunks = 4, dim = 0)
tc
# (tensor([[0, 1, 2]]),
# tensor([[3, 4, 5]]),
# tensor([[6, 7, 8]]),
# tensor([[ 9, 10, 11]]))根据结果可见:
返回结果是一个元组,不可变
tc[0] = torch.tensor([[1, 1, 1]])
# TypeError: 'tuple' object does not support item assignment元组中的每个值依然是一个二维张量
tc[0]
# tensor([[0, 1, 2]])返回的张量
tc的一个视图,不是新成了一个对象
# 我们将原张量t2中的数值进行更改
t2[0] = torch.tensor([6, 6, 6])
# 再打印分块后tc的结果
tc
# (tensor([[6, 6, 6]]),
# tensor([[3, 4, 5]]),
# tensor([[6, 7, 8]]),
# tensor([[ 9, 10, 11]]))若原张量不能均分时,chunk不会报错,会返回次一级均分结果。
# 创建一个4×3的矩阵
t2 = torch.arange(12).reshape(4, 3)
t2
# tensor([[ 0, 1, 2],
# [ 3, 4, 5],
# [ 6, 7, 8],
# [ 9, 10, 11]])将4行分为3等份,不可分,就会返回2等分的结果:
tc = torch.chunk(t2, chunks = 3, dim = 0)
tc
# (tensor([[0, 2, 2],
# [3, 4, 5]]),
# tensor([[ 6, 7, 8],
# [ 9, 10, 11]]))4.2 split函数
split既能进行均分,也能进行自定义切分。需要注意的是split的返回结果也是视图。
# 第二个参数只输入一个数值时表示均分
# 第三个参数表示切分的维度
torch.split(t2, 2, dim = 0)
# (tensor([[0, 1, 2],
# [3, 4, 5]]),
# tensor([[ 6, 7, 8],
# [ 9, 10, 11]]))与chunk函数不同的是,split第二个参数可以输入一个序列,表示按照序列数值等分:
torch.split(t2, [1,3], dim = 0)
# (tensor([[0, 1, 2]]),
# tensor([[ 3, 4, 5],
# [ 6, 7, 8],
# [ 9, 10, 11]]))当第二个参数输入一个序列时,序列的各数值的和必须等于对应维度下形状分量的取值,即shape对应的维度。
例如上述代码中,是按照第一个维度进行切分,而t2总共有4行,因此序列的求和必须等于4,也就是1+3=4,而序列中每个分量的取值,则代表切块大小。
4.3 张量的拼接cat
这里一定要将dim参数与shape返回的结果相对应理解。
a = torch.zeros(2, 3)
a
# tensor([[0., 0., 0.],
# [0., 0., 0.]])
b = torch.ones(2, 3)
b
# tensor([[1., 1., 1.],
# [1., 1., 1.]])因为在张量a与b中,shape的第一个位置是代表向量维度,所以当dim取0时,就是将向量进行合并,向量中的标量数不变:
torch.cat([a, b], dim = 0)
# tensor([[0., 0., 0.],
# [0., 0., 0.],
# [1., 1., 1.],
# [1., 1., 1.]])当dim取1时,shape的第二个位置是代表列,即标量数,就是在列上(标量维度)进行拼接,行数(向量数)不变:
torch.cat([a, b], dim = 1)
# tensor([[0., 0., 0., 1., 1., 1.],
## [0., 0., 0., 1., 1., 1.]])将dim与shape结合理解,是不是清晰明了了?
4.4 张量的堆叠stack
和拼接不同,堆叠不是将元素拆分重装,而是将各参与堆叠的对象分装到一个更高维度的张量里。
a = torch.zeros(2, 3)
a
# tensor([[0., 0., 0.],
# [0., 0., 0.]])
b = torch.ones(2, 3)
b
# tensor([[1., 1., 1.],
# [1., 1., 1.]])堆叠之后,生成一个三维张量:
torch.stack([a, b], dim = 0)
# tensor([[[0., 0., 0.],
# [0., 0., 0.]],
# [[1., 1., 1.],
# [1., 1., 1.]]])
torch.stack([a, b], dim = 0).shape
# torch.Size([2, 2, 3])此例中,就是将两个维度为1×2×3的张量堆叠为一个2×2×3的张量。
4.5 cat与stack的区别
拼接之后维度不变,堆叠之后维度升高。拼接是把一个个元素单独提取出来之后再放到二维张量里,而堆叠则是直接将两个二维向量封装到一个三维张量中。因此,堆叠的要求更高,参与堆叠的张量必须形状完全相同。
4.6 python中的拼接和堆叠
a = [1, 2]
b = [3, 4]cat拼接操作与list的extend相似,不会改变维度,只会在已有框架内增加元素:
a.extend(b)
a
# [1, 2, 3, 4]stack堆叠操作与list的append相似,会改变维度:
a = [1, 2]
b = [3, 4]
a.append(b)
a
# [1, 2, [3, 4]]-------- End --------

精选资料
回复关键词,获取对应的资料:
| 关键词 | 资料名称 |
|---|---|
| 600 | 《Python知识手册》 |
| md | 《Markdown速查表》 |
| time | 《Python时间使用指南》 |
| str | 《Python字符串速查表》 |
| pip | 《Python:Pip速查表》 |
| style | 《Pandas表格样式配置指南》 |
| mat | 《Matplotlib入门100个案例》 |
| px | 《Plotly Express可视化指南》 |
精选视频
可视化: Plotly
财经: Plotly在投资领域的应用 | 绘制K线图表
排序算法: 冒泡排序 | 选择排序 | 快速排序 | 归并排序 | 堆排序 | 插入排序 | 希尔排序 | 计数排序
