图像分类、5个网络
图像分类
基于卷积神经网络的图像分类方法
图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉的核心,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层次视觉任务的基础。
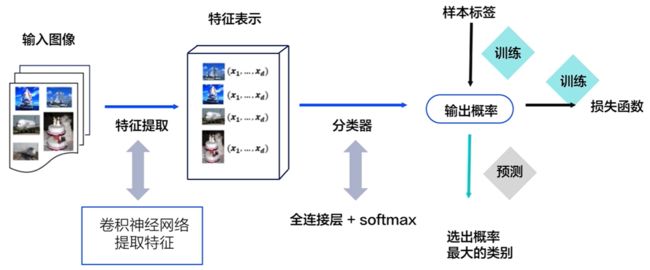
按照被提出的时间顺序,涵盖如下卷积神经网络:
-
LeNet:Yan LeCun等人于1998年第一次将卷积神经网络应用到图像分类任务上[1],在手写数字识别任务上取得了巨大成功。
-
AlexNet:Alex Krizhevsky等人在2012年提出了AlexNet[2], 并应用在大尺寸图片数据集ImageNet上,获得了2012年ImageNet比赛冠军(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)。
-
VGG:Simonyan和Zisserman于2014年提出了VGG网络结构[3],是当前最流行的卷积神经网络之一,由于其结构简单、应用性极强而深受广大研究者欢迎。
-
GoogLeNet:Christian Szegedy等人在2014提出了GoogLeNet[4],并取得了2014年ImageNet比赛冠军。
-
ResNet:Kaiming He等人在2015年提出了ResNet[5],通过引入残差模块加深网络层数,在ImagNet数据集上的错误率降低到3.6%,超越了人眼识别水平。ResNet的设计思想深刻地影响了后来的深度神经网络的设计。
眼疾识别数据集
IChallenge-PM数据集:关于病理性近视(Pathologic Myopia,PM)的医疗类数据集, 包含1200个受试者的眼底视网膜图片,训练、验证和测试数据集各400张。
LeNet(5)
LeNet通过连续使用卷积和池化层的组合提取图像特征。
LeNet具有CNN的基本结构,卷积层,池化层,全连接层
LeNet在手写数字识别上的应用
LeNet网络的实现代码如下:
# 导入需要的包 import paddle import numpy as np from paddle.nn import Conv2D, MaxPool2D, Linear ## 组网 import paddle.nn.functional as F # 定义 LeNet 网络结构 class LeNet(paddle.nn.Layer): def __init__(self, num_classes=1): super(LeNet, self).__init__() # 创建卷积和池化层 # 创建第1个卷积层 self.conv1 = Conv2D(in_channels=1, out_channels=6, kernel_size=5) self.max_pool1 = MaxPool2D(kernel_size=2, stride=2) # 尺寸的逻辑:池化层未改变通道数;当前通道数为6 # 创建第2个卷积层 self.conv2 = Conv2D(in_channels=6, out_channels=16, kernel_size=5) self.max_pool2 = MaxPool2D(kernel_size=2, stride=2) # 创建第3个卷积层 self.conv3 = Conv2D(in_channels=16, out_channels=120, kernel_size=4) # 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W] # 输入size是[28,28],经过三次卷积和两次池化之后,C*H*W等于120 self.fc1 = Linear(in_features=120, out_features=64) # 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分类标签的类别数 self.fc2 = Linear(in_features=64, out_features=num_classes) # 网络的前向计算过程 def forward(self, x): x = self.conv1(x) # 每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化 x = F.sigmoid(x) x = self.max_pool1(x) x = F.sigmoid(x) x = self.conv2(x) x = self.max_pool2(x) x = self.conv3(x) # 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W] x = paddle.reshape(x, [x.shape[0], -1]) x = self.fc1(x) x = F.sigmoid(x) x = self.fc2(x) return x
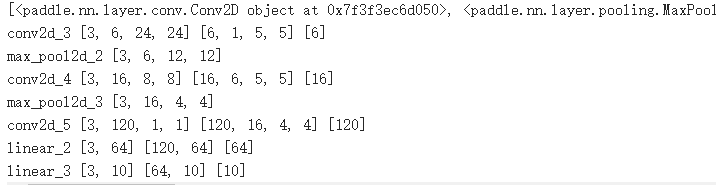
飞桨会根据实际图像数据的尺寸和卷积核参数自动推断中间层数据的W和H等,只需要用户表达通道数即可。下面的程序使用随机数作为输入,查看经过LeNet-5的每一层作用之后,输出数据的形状。
# 输入数据形状是 [N, 1, H, W]
# 这里用np.random创建一个随机数组作为输入数据
x = np.random.randn(*[3,1,28,28])
x = x.astype('float32')
# 创建LeNet类的实例,指定模型名称和分类的类别数目
m = LeNet(num_classes=10)
# 通过调用LeNet从基类继承的sublayers()函数,
# 查看LeNet中所包含的子层
print(m.sublayers())
x = paddle.to_tensor(x)
for item in m.sublayers():
# item是LeNet类中的一个子层
# 查看经过子层之后的输出数据形状
try:
x = item(x)
except:
x = paddle.reshape(x, [x.shape[0], -1])
x = item(x)
if len(item.parameters())==2:
# 查看卷积和全连接层的数据和参数的形状,
# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数b
print(item.full_name(), x.shape, item.parameters()[0].shape, item.parameters()[1].shape)
else:
# 池化层没有参数
print(item.full_name(), x.shape)
输出结果:
# -*- coding: utf-8 -*-
# LeNet 识别手写数字
import os
import random
import paddle
import numpy as np
# 定义训练过程
def train(model):
# 开启0号GPU训练
use_gpu = True
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
print('start training ... ')
model.train()
epoch_num = 5
opt = paddle.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameters=model.parameters())
# 使用Paddle自带的数据读取器
train_loader = paddle.batch(paddle.dataset.mnist.train(), batch_size=10)
valid_loader = paddle.batch(paddle.dataset.mnist.test(), batch_size=10)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
# 调整输入数据形状和类型
x_data = np.array([item[0] for item in data], dtype='float32').reshape(-1, 1, 28, 28)
y_data = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)
# 将numpy.ndarray转化成Tensor
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 计算模型输出
logits = model(img)
# 计算损失函数
loss = F.softmax_with_cross_entropy(logits, label)
avg_loss = paddle.mean(loss)
if batch_id % 1000 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
avg_loss.backward()
opt.step()
opt.clear_grad()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
# 调整输入数据形状和类型
x_data = np.array([item[0] for item in data], dtype='float32').reshape(-1, 1, 28, 28)
y_data = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)
# 将numpy.ndarray转化成Tensor
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 计算模型输出
logits = model(img)
pred = F.softmax(logits)
# 计算损失函数
loss = F.softmax_with_cross_entropy(logits, label)
acc = paddle.metric.accuracy(pred, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
# 保存模型参数
paddle.save(model.state_dict(), 'mnist.pdparams')
# 创建模型
model = LeNet(num_classes=10)
# 启动训练过程
train(model)
通过运行结果可以看出,LeNet在手写数字识别MNIST验证数据集上的准确率高达92%以上。
LeNet在眼疾识别数据集上的应用
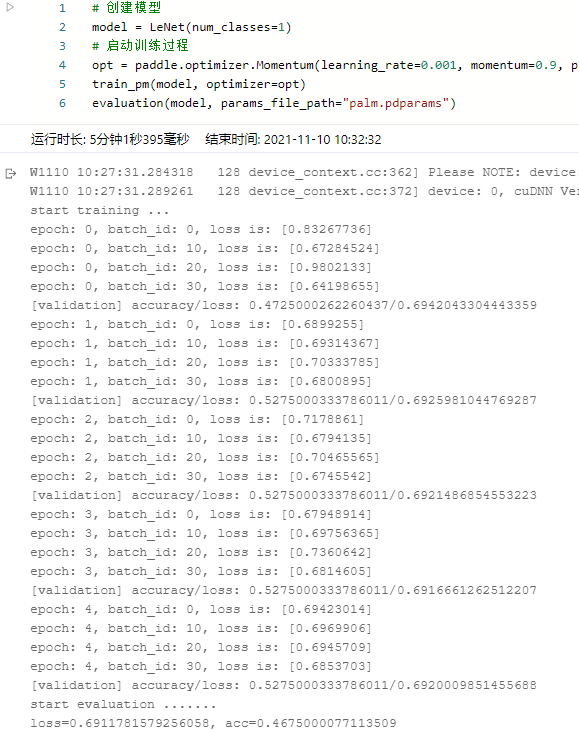
通过运行结果可以看出,LeNet的loss很难下降,模型没有收敛。
这是因为MNIST数据集的图片尺寸比较小(28×28)
但是眼疾筛查数据集图片尺寸比较大(原始图片尺寸约为2000×2000,经过缩放之后变成224×224)
LeNet模型很难进行有效分类。
这说明在图片尺寸比较大时,LeNet在图像分类任务上存在局限性。

AlexNet(8)
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接。
AlexNet做出的改变:
-
引入了ReLU激活函数。
-
使用了一些抑制过拟合的方法,如Dropout
-
有imagenet
-
大数据集的训练
-
其他:使用GPU加速训练
(具有更深的网络结构,包括5层卷积和3层全连接)
-
数据增广:深度学习中常用的一种处理方式。
通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。
通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
-
使用Dropout抑制过拟合。
-
使用ReLU激活函数减少梯度消失现象。

VGG(16)
通过 重复使用简单地基础块来构建深度模型 为深度神经网络的构建提供了方向
-
整个网络借故偶可以分为5个VGG块,再加上全连接层
-
整个VGG块包含多层3×3的卷积层 + 2×2最大池化层

注:VGG网络的设计严格使用3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。
在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。
使用小的卷积核能够有效地减少参数的个数,使得训练和测试变得更加有效。


GoogleNet(22)
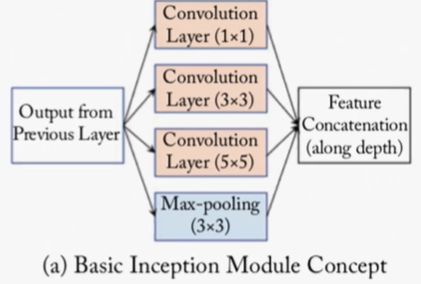
主要特点是网络不仅有深度,还在横向上具有“宽度”。

Inception块的设计思想

-
改进:
-
简单地多通路拼接,会造成通道数目的迅速增长,通过额外添加1×1的卷积层来控制通道数
-
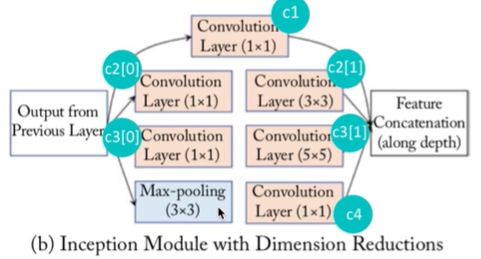
GoogLeNet架构
在主体卷积部分中使用5个模块(block),每个模块之间使用最大池化层(步幅为2的3 ×3)(k=3,s=2)来减小输出高宽。
-
模块1:7×7卷积(64通道)
-
模块2:两层卷积1×1 , 3×3(64通道)
-
模块3:2个Inception块(串联起来)
-
模块4:5个Inception块(串联起来)
-
模块5:2个Inception块(串联起来)
-
全局平均池化 + 全连接(全局平均池化层将每个通道的高和宽变成1,最后接上一个输出个数为标签类别数的全连接层。)

ResNet(残差网络)
引入了残差块(瓶颈结构)
输入x通过跨层连接,能更快的向前传播数据,或者向后传播梯度。
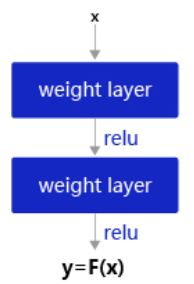
表示增加网络的时候,将 x 映射成 y=F(x) 输出。

输出 y=F(x)+x 。这时不是直接学习输出特征 y 的表示,而是学习 y−x 。
ResNet中使用了BatchNorm层,在卷积层的后面加上BatchNorm以提升数值稳定性
num_channels, 卷积层的输入通道数
num_filters, 卷积层的输出通道数
stride, 卷积层的步幅
groups, 分组卷积的组数,默认groups=1不使用分组卷积
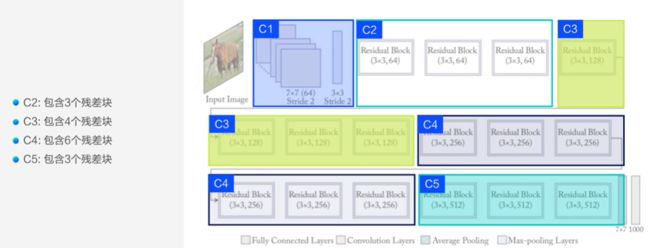
ResNet-50
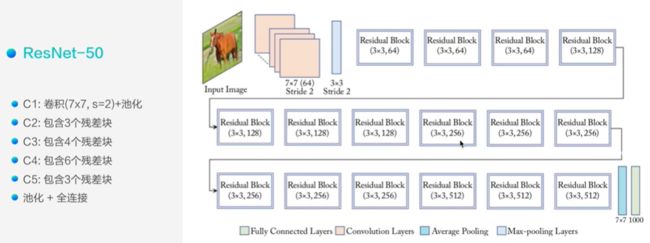
(ResNet还有ResNet-101和ResNet-152,只简要介绍ResNet-50)


附
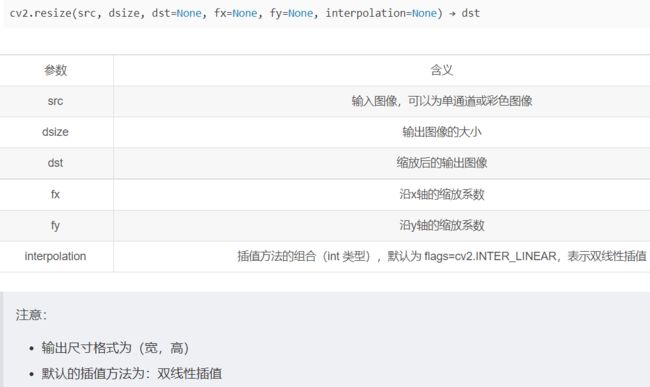
Opencv:
cv2.resize() 函数
line.strip().split(‘,‘)
strip()用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。 split(‘ ’): 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串。
通俗点:
strip()表示删除掉数据中的换行符
>>> a = '123abc'
>>> a.strip('21')
'3abc'
>>> a.strip('12')
'3abc'
split(‘,’)则是数据中遇到 ‘,’ 就隔开
>>> str = ('www.google.com')
>>> print str
www.google.com
>>> str_split = str.split('.')
>>> print str_split
['www', 'google', 'com']
str.split()[0]
str = "hello boy and.girls"
a = str.split(".")[0]
print(a)
![]()
str = "hello boy and.girls"
a = str.split(".")[0][-1]
print(a)
![]()
str.split(“.”)[0] 得到的是第一个.之前的内容 str.split(“.”)[1] 得到的是第一个.和第二个.之间的内容 str.split(“.”)[3] 得到的是第三个.后和第四个.前之间的内容 str.split(".")[0] 得到的是第一个.之前的内容
str.split(".")[0:2]得到的是第一个.之前的内容 + 第一个.和第二个.之间的内容,这里第三个.前内容取不到,是一个左闭右开区间。
Image.open()和cv2.imread()
img = cv2.imread(path),这是opencv中的处理图片的函数,使用时需 import cv2 img = Image.open(path),这是PIL中的一个处理图片的函数,使用时需 from PIL import Image
图像读取
cv2.imread()读取的是图像的真实数据。
Image.open()函数只是保持了图像被读取的状态,但是图像的真实数据并未被读取,因此如果对需要操作图像每个元素,如输出某个像素的RGB值等,需要执行对象的load()方法读取数据
img = Image.open("lena.jpg")
img = img.load()
print(img[0,0])
读入图片类型
Image.open()得到的img数据类型呢是Image对象,不是普通的数组。 cv2.imread()得到的img数据类型是np.array()类型。
通道
对于Image.open()函数默认彩色图像读取通道的顺序为RGB
cv2.imread()读取通道的顺序为BGR。
显示方法
一种是matplotlib的plt.imshow()方法,一种是opencv的cv2.imshow()。
两个函数的输入都要求是数组。
因此Image读取的图片要先转化为数组,再进行图片的显示。
add.sublayer
是fluid.dygraph.Layer的一个函数,
其作用是添加子层实例。
nn.Sequential()模块
nn.Sequential()可以将一系列的操作打包,这些操作可以包括Conv2d()、ReLU()、Maxpool2d()等,打包后方便调用吧,就相当于是一个黑箱,forward()时调用这个黑箱就行了。例如:
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
#nn.Sequential()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(48, 128, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(128, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
......
def forward(self, x):
x = self.features(x)
......
return x
Leaky_ReLU
ReLU是将所有的负值都设为零,相反,Leaky_ReLU是给所有负值赋予一个非零斜率。
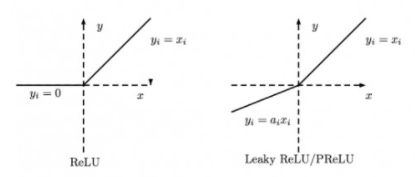
negative_slope=0.1 代表 负斜率为0.1
解决了Relu的神经元死亡问题,但结果不一致,无法为正负输入值提供一致的关系预测(不同区间函数不同)
Leaky Relu激活函数引入一个固定斜率a,具有Relu激活函数所有的优点,但并不保证效果比Relu激活函数好
优点:跟Relu激活函数想比,输入值小于0也可以进行参数更新,不会造成神经元死亡。
缺点:输出非0均值,收敛慢。
Layers
网络层数
在ResNet中可以是50、101或152
class_dim
分类标签的类别数