深度学习框架 fast.ai 2.0 正式发布
如果你想入门深度学习,这是个难得的好机会。软件、样例、课程,还有配套教材的开源版本,全都免费提供。
发布
经历了长久的等待之后,深度学习框架 fast.ai 2.0 版本终于正式发布了。

fast.ai 课程,是为了践行 Jeremy Howard “让深度学习不再酷”的承诺。这话的意思是也消除掉门槛,让更多没有高等数学和统计专业基础的人,都有机会来了解和应用深度学习。关于这个事儿,我在《如何从零基础学最前沿的 Python 深度学习?》一文中,给你介绍过。
顺便给你介绍一下这个课程的迭代过程。
课程的第一个轮次,使用的是 Keras 作为框架讲解。这在当时是个不错的选项。因为比起当时存在的各种深度学习框架,Keras 是其中最为简单易学的。我也不止一次,在教程里面给你推荐过 Keras 作者 François Chollet 的配套教材。
但是很快,Jeremy Howard 就发现了 Keras 存在的问题。这个框架提供的 API 虽然简单,但是如果用户希望进行深度定制,会比较费劲。因为一旦尝试定制,就必然需要调用后端框架。而 Keras 的后端框架是 Tensorflow (当时还是1.x 版本)。Tensorflow 在当时几乎是以“用户不友好”著称。
可是 Keras 明明已经提供了深度学习的模型建构、训练、调试等功能,为什么用户还需要定制呢?这是因为 fast.ai 并不是一门 101 课程。Jeremy 不会认为只教你调用软件包,做个 "hello world!" 就满足了教学的目标。相反,他总是希望把最前沿的东西融入课堂。
例如文本深度迁移学习 ULMfit,在当时的理念上,着实是划时代的。可以说,后面 BERT 和一系列的 Transformers 架构,都从中吸取了不少有益的特点。
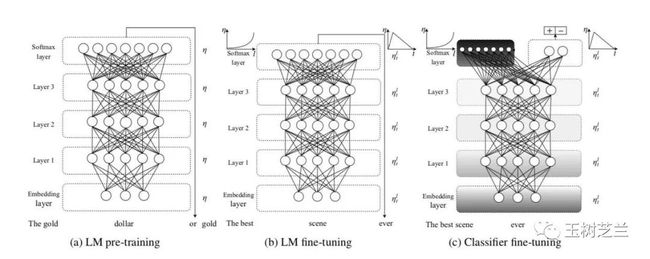
这么重要的一个架构,别人肯定是先把论文发了,然后再找时间看要不要在课上讲解。Jeremy 不是。他先在课程中对 ULMfit 做了介绍,让学生们第一时间尝试这种新的语言模型,然后才受邀发了论文。ULMfit 里面采用了一种“差序训练速率”(discriminative learning rate),即对于不同层次,训练速率都不同。这种对于模型架构的深度修改,没有可扩展定制能力,显然是不行的。
因为用 Keras 不顺手,Jeremy 做出了一个决定:
干脆自己开发一个前端 API 框架。
过程
一开始, Jeremy 是打算基于 Tensorflow 来做的。在准备迭代第二次课程的时候,PyTorch 的出现让他眼前一亮。PyTorch 的 API 更加简洁,一致性更强,用户友好程度比起 Tensorflow 1.x 要好很多。于是 Jeremy 修改了方案,基于 PyTorch 开发前端 API ,名字就叫做 fast.ai 。
这个框架当时是为了上课用的。一边备课一边编写,所以开发的时候非常紧迫。甚至导致他晚上上课,下午还在调代码。进度赶得真叫一个惊心动魄。
好在,尽管过程磕磕碰碰,Jeremy 总算没有因为 fast.ai 的开发进度耽误上课。这一框架受到了初学者与研究界广泛的好评。这好评主要包括两个方面:
首先是低门槛。fast.ai 把一切能自动化完成的过程全都包裹了起来。这种简便性,使得你只要看得懂函数名称,就大致会用了。而且还有完整的课程,从头教起。遇到问题,论坛上的回答氛围也很活跃。
其次是高天花板。简单并不一定意味着能力弱。fast.ai 不断融合吸收大量深度学习领域前沿技术。例如数据增强、模型解释等。
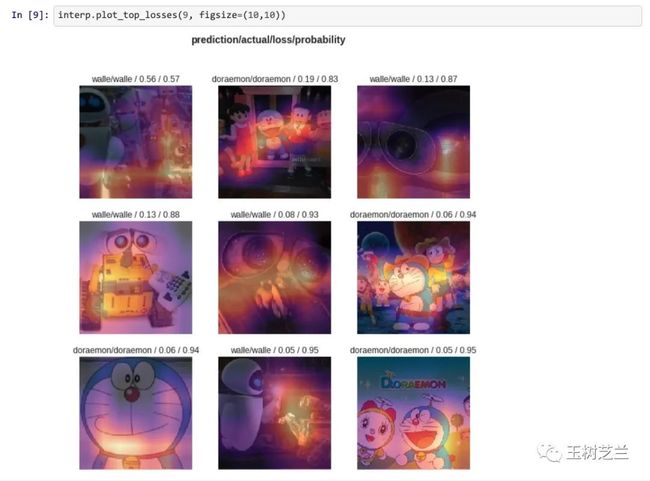
2019 年春天,fast.ai 课程进阶部分第三次迭代。我原本以为这次的迭代,是提供了新的功能讲解,或者更深度和前沿的应用样例。但是没有。Jeremy 尝试带着学生们从头去实现框架的功能。
这个工作,我觉得很有意义。对一个框架从源头掌握起来,学会怎么从底层的 PyTorch 构建 fast.ai API ,对学生深刻理解深度学习的基础知识,大有裨益。但这并不是全部。我发现 Jeremy 确实对于第二轮迭代的时候,因为赶工期做出的代码耿耿于怀。我知道,一次大版本升级,甚至是重构快要开始了。
重构
果不其然,2019 年 9 月,Jeremy 开始在线直播展示自己的 fast.ai v2 重构过程。
这个版本的更新,非同一般。基本上就是重写了一个框架出来。为了保持原有框架的特色和优势,又要保证今后的接口一致性与可扩展性,工作着实繁重。这不,打磨了将近一年之后,正式版才终于上线了。
不过,这中间过程里,fast.ai v2 代码一直是全开放的,也逐渐变得可用了。几个月前,我对比了一下新旧 API,便毫不犹豫地在代码还在持续迭代,文档很不完善的时候,用了起来。于是,正式版还没发布,我用 fast.ai v2 做实验形成的论文都发出来了。
fast.ai 2.0 的许多功能,都变得更加完善。我曾经吐槽过的那些不合逻辑的地方,有了显著的改善。
各种基础功能,变得愈发齐备。例如图像数据读取,原先需要用户自己手动把图片按照某种特定形式来存放,程序才能正常识别。当数据量庞大的时候,你真的想要重新组织文件夹结构,可能都会因为空间限制,闪展腾挪不开,导致无法完成。
现在自带功能就提供了多种不同选项。可以通过目录名、excel 表等多种不同的方式来存储图片分类,fast.ai v2 都能处理。这样一来,数据准备等工作就变得简单多了。

资源
与更新的框架代码同时推出的,还有一系列的配套产品。
首先就是第四轮迭代的在线课程。
这次的课程,包括了 8 讲。利用 fast.ai v2.0 新的 API,把深度学习的各个领域应用横扫了一遍,内容覆盖相当全面了。基本上你把这门课学完,别人再想用深度学习中的概念来蒙你,就很难了。甚至,你可能在参加学术报告的时候,发现某些人把深度学习方法完全用错了。
以前 Jeremy 的 fast.ai 课程,都是把课堂录像,放到网上。这种形式的坏处,是你时刻都知道,Jeremy 不是在给你自己讲课。代入感不够强,不容易保持专注。
这次,他就是一直冲着你来讲。幸福吧?
第二个配套产品,是书。
fast.ai 的教材,终于出版了。
当书的第二作者 Sylvain Gugger 在网上宣布这个消息的时候,人们沸腾了。

短短几个小时的时间,点赞数量已经超过 700,而且获得了将近 70 次的转推。这就是奔走相告啊。
我立即在亚马逊 kindle 商店下单,买了一本。
从目录来看,讲的内容比课程更系统全面。而且节奏可以由学习者自行把握,也便于检索内容。

不过,你不要急着下单。因为 fast.ai 给你提供了一项福利:
书的开源版本。
该版本包含了全书的图文内容和代码,采用了 Jupyter Notebook 形式存储。
这是打开以后的样子。
我跟 kindle 版本对照一下,内容没有区别。而且使用 Jupyter Notebook 版本学习,你还能直接复用其中的代码。
你想学这本书的内容,根本就不用花钱。是不是很慷慨?不过如果有实力的话,建议你买书支持一下作者。毕竟,一项事业仅仅依靠热情,而没有经济基础支撑,是无法长期维持的。
fast.ai 还发布了一篇学术论文,讲这次改进后的 API 层级架构。如果你想从专业的角度了解新框架的设计思路,这篇论文值得认真阅读。

另外如果你在自己的研究中使用了 fast.ai v2 框架,别忘了引用该论文。这也算对作者贡献的肯定与回馈吧。上面介绍的相关资源链接,请在公众号后台回复“fv2”获取。
祝深度学习愉快!
感觉有用的话,请点“在看”,并且把它转发给你身边有需要的朋友。
我的视频号已经上线,发布了教程和经验分享视频,欢迎关注。

订阅我的微信公众号“玉树芝兰”,第一时间免费收到文章更新。别忘了加星标,以免错过新推送提示。

如果你希望能与其他热爱学习的小伙伴一起讨论切磋,答疑解惑,欢迎加入知识星球。
延伸阅读
你可能也会对以下话题感兴趣。点击链接就可以查看。
如何高效学 Python ?
学 Python ,能提升你的竞争力吗?
文科生如何理解卷积神经网络?
文科生如何理解循环神经网络(RNN)?
如何高效入门 PyTorch ?