NNDL实验 优化算法3D轨迹 鱼书例题3D版
这张图在网络上很流行。代码源自:
深度学习入门:基于Python的理论与实现 (ituring.com.cn)

2D版讲解:NNDL 作业11:优化算法比较
调整学习率等超参数,观察动画,可以加深对各种算法的理解。
配合实验的模型,CS231的模型,基本可以掌握各类算法特点。
NNDL实验 优化算法3D轨迹程序改编自《神经网络与深度学习:案例与实践》(Paddle版)https://blog.csdn.net/qq_38975453/article/details/128179041NNDL实验 优化算法3D轨迹 复现cs231经典动画这个动画很有名气,学习深度学习的朋友大多都见过复现动画,向经典致敬~https://blog.csdn.net/qq_38975453/article/details/128192767真正的了解算法之后,才能在合适的时候选择合适的算法。
3D版展示:
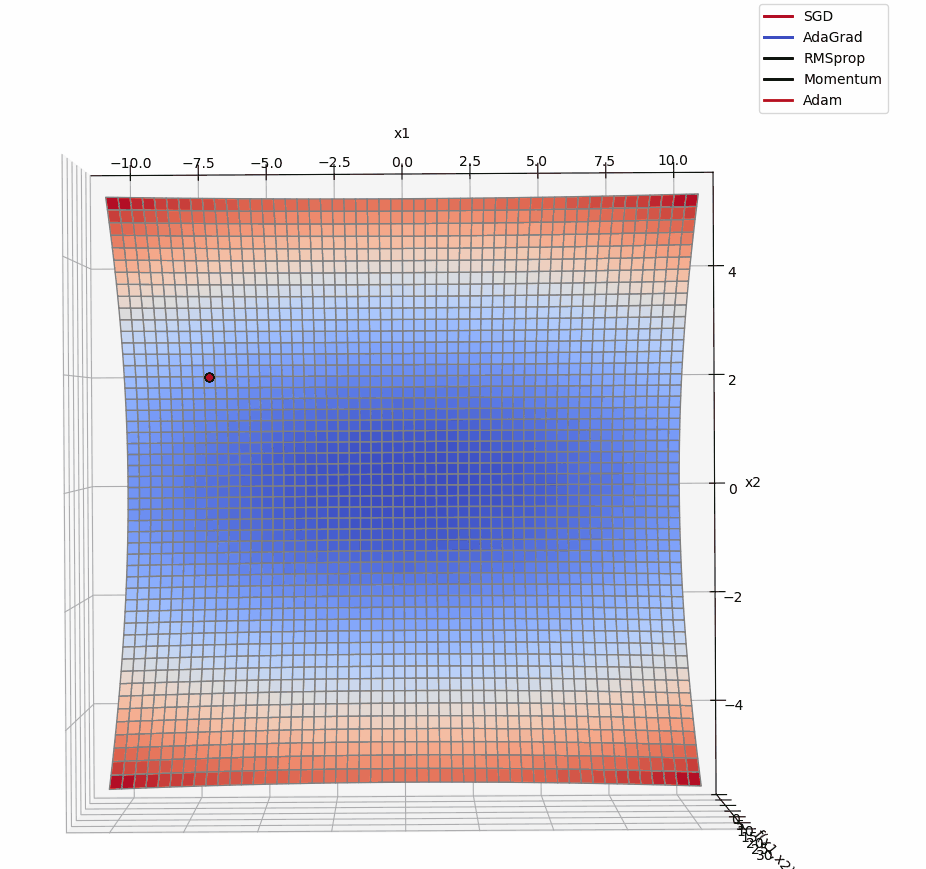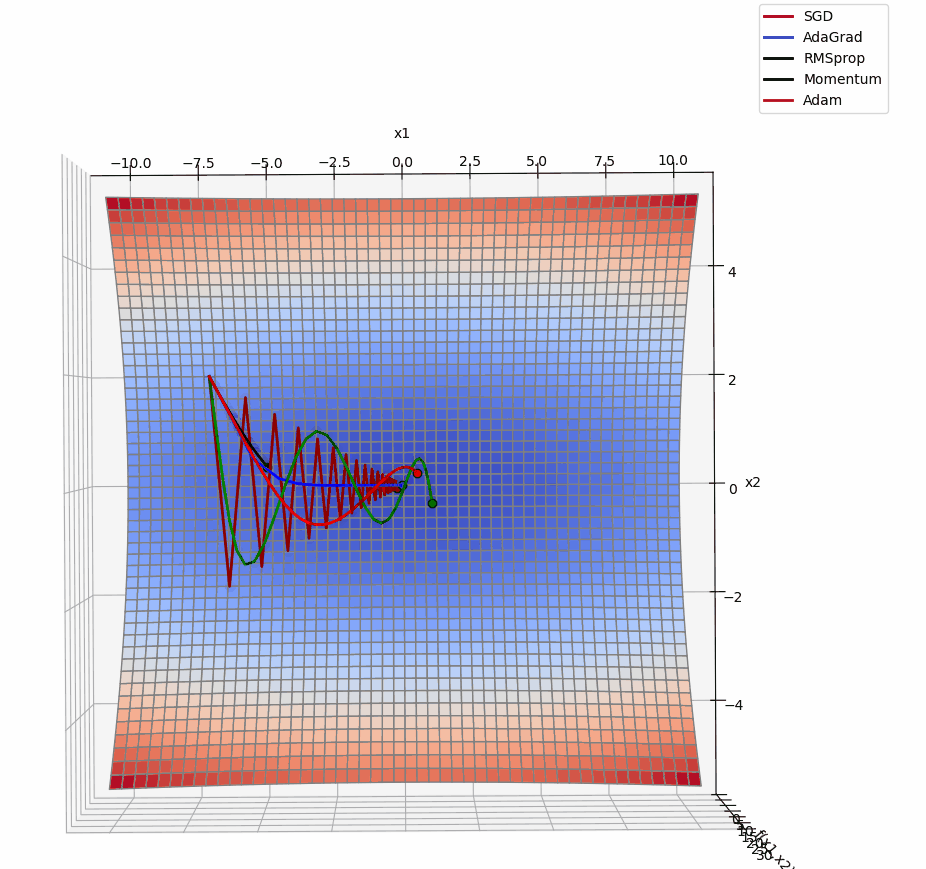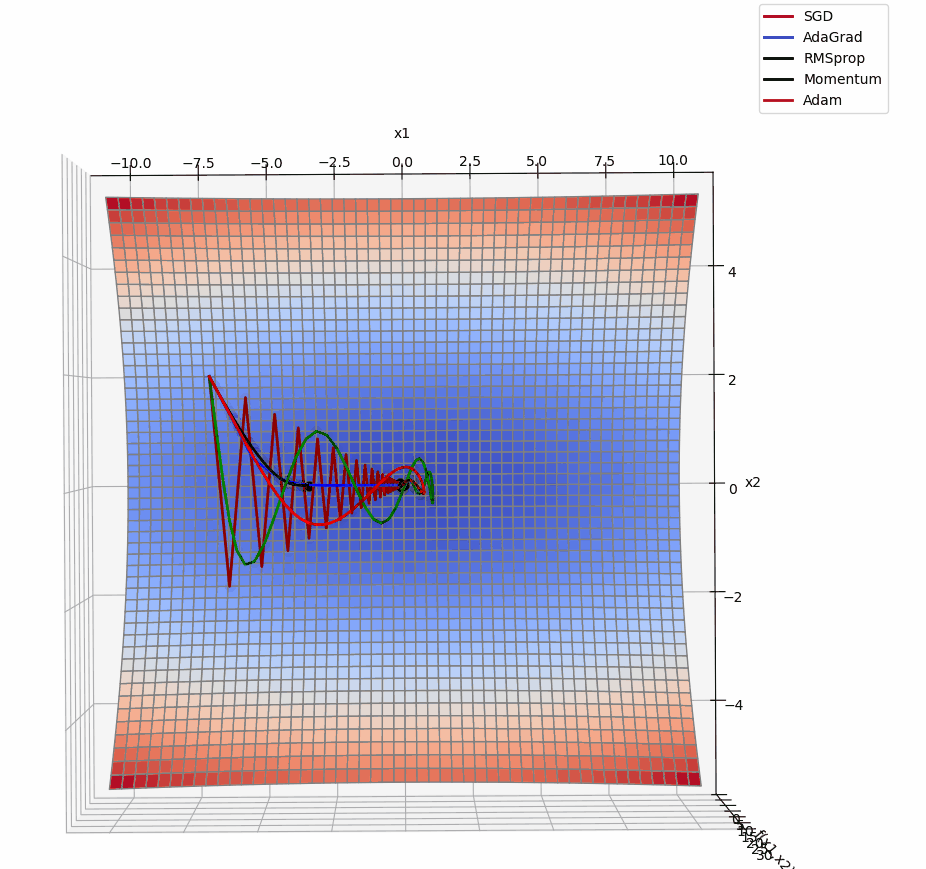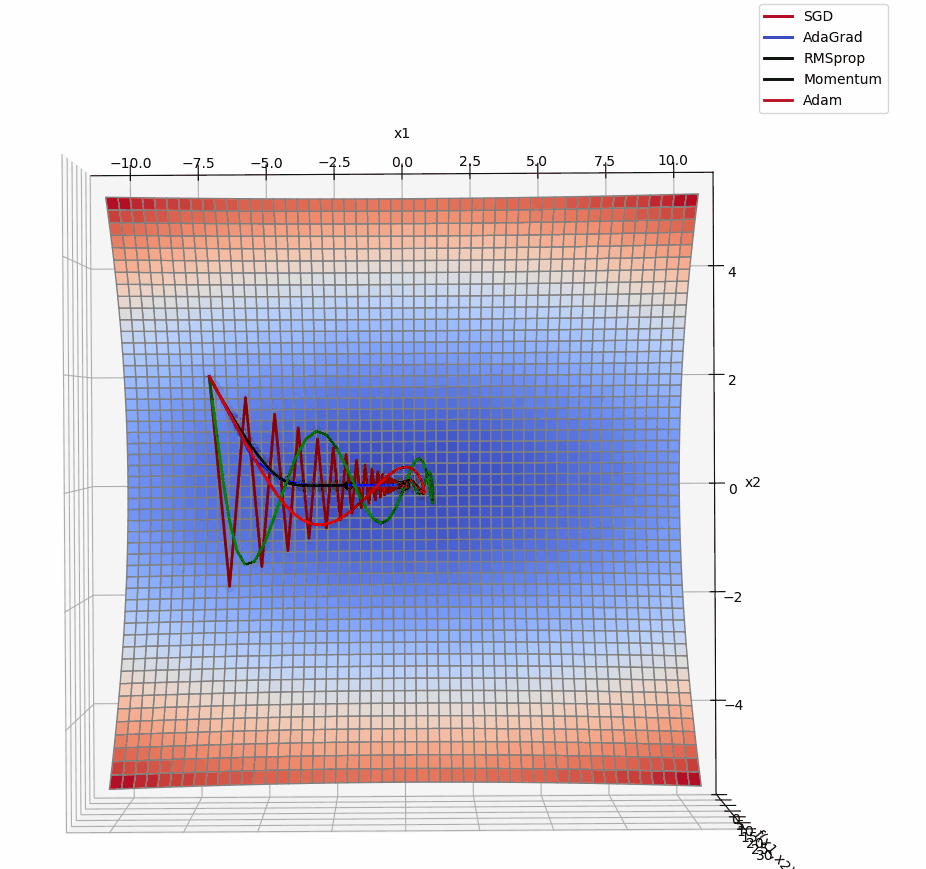
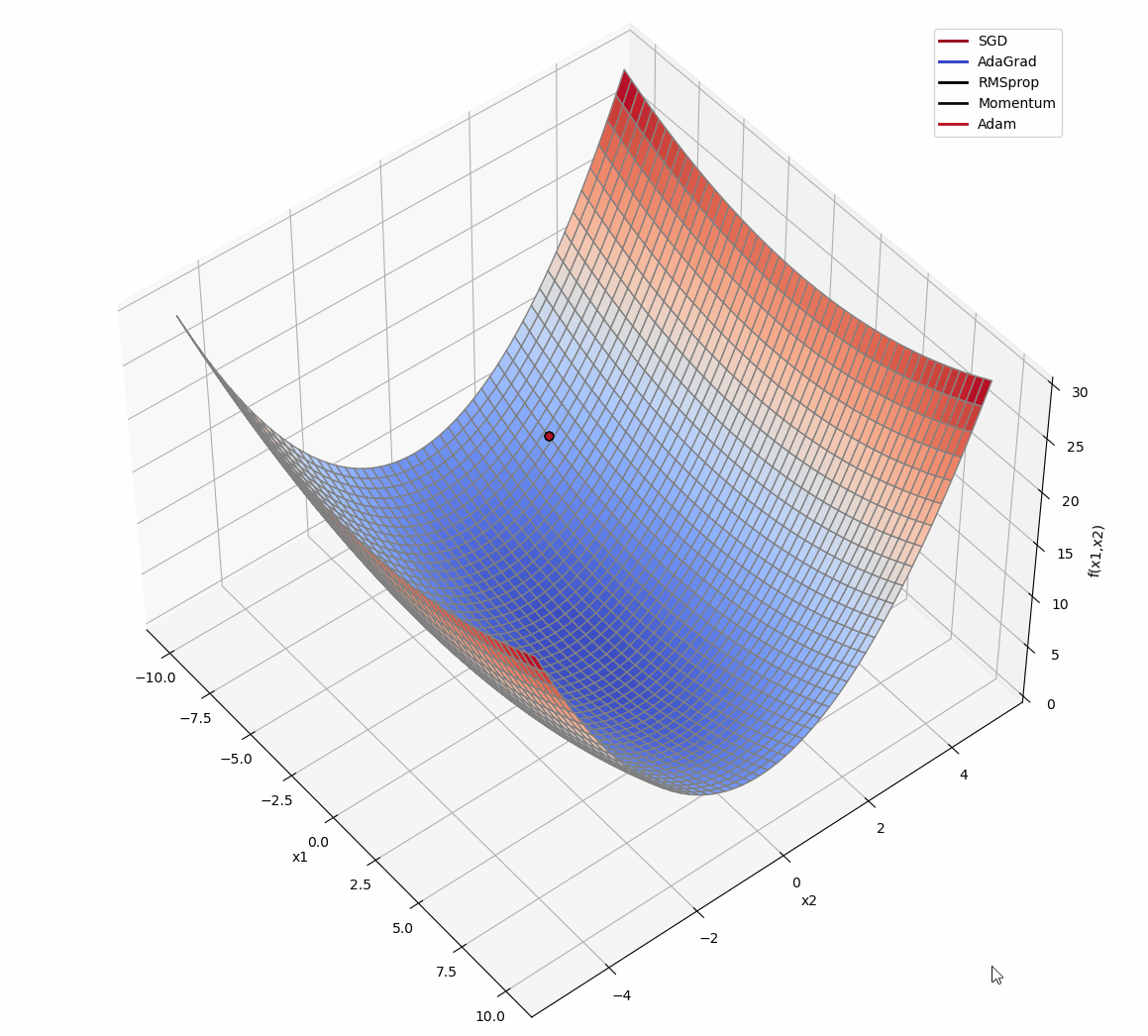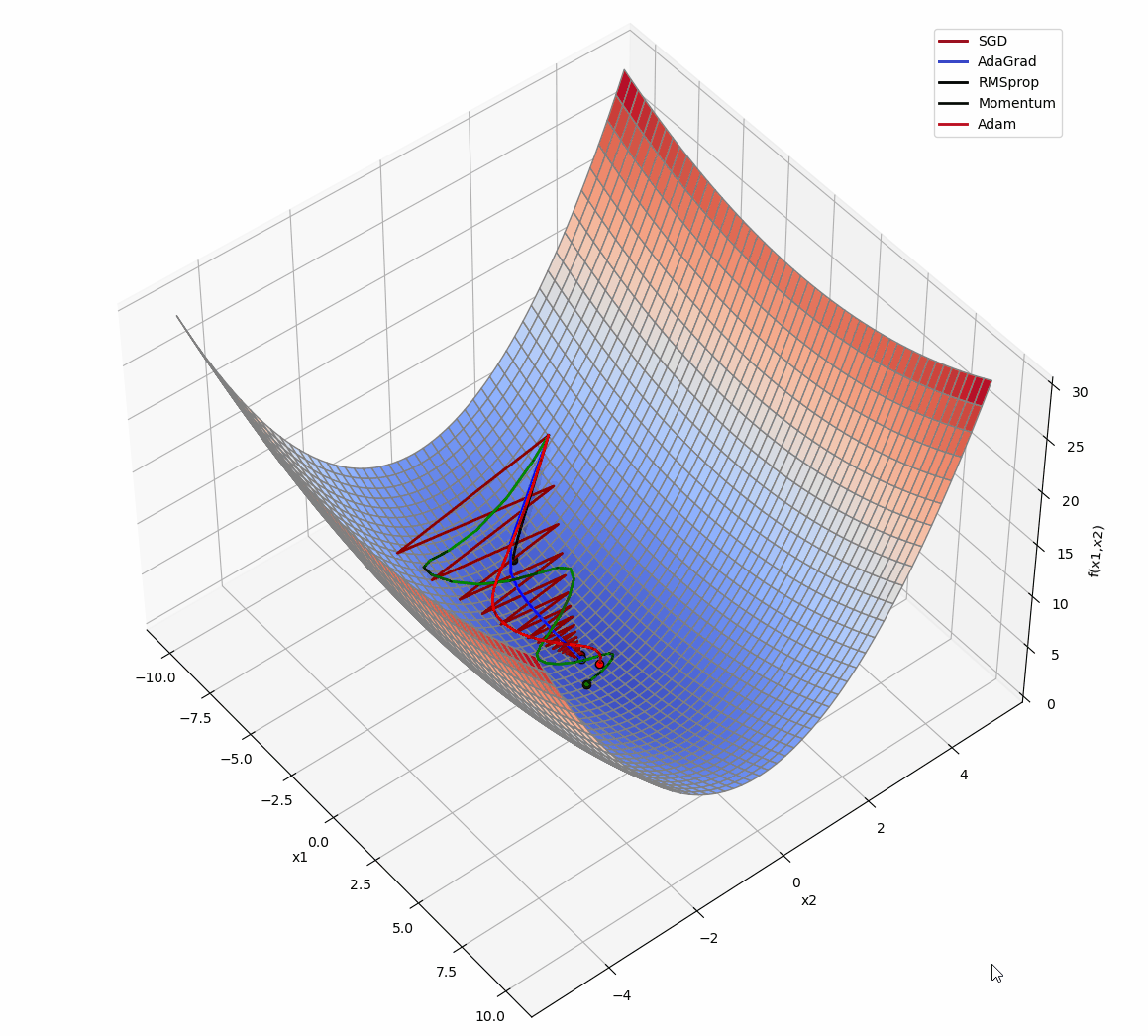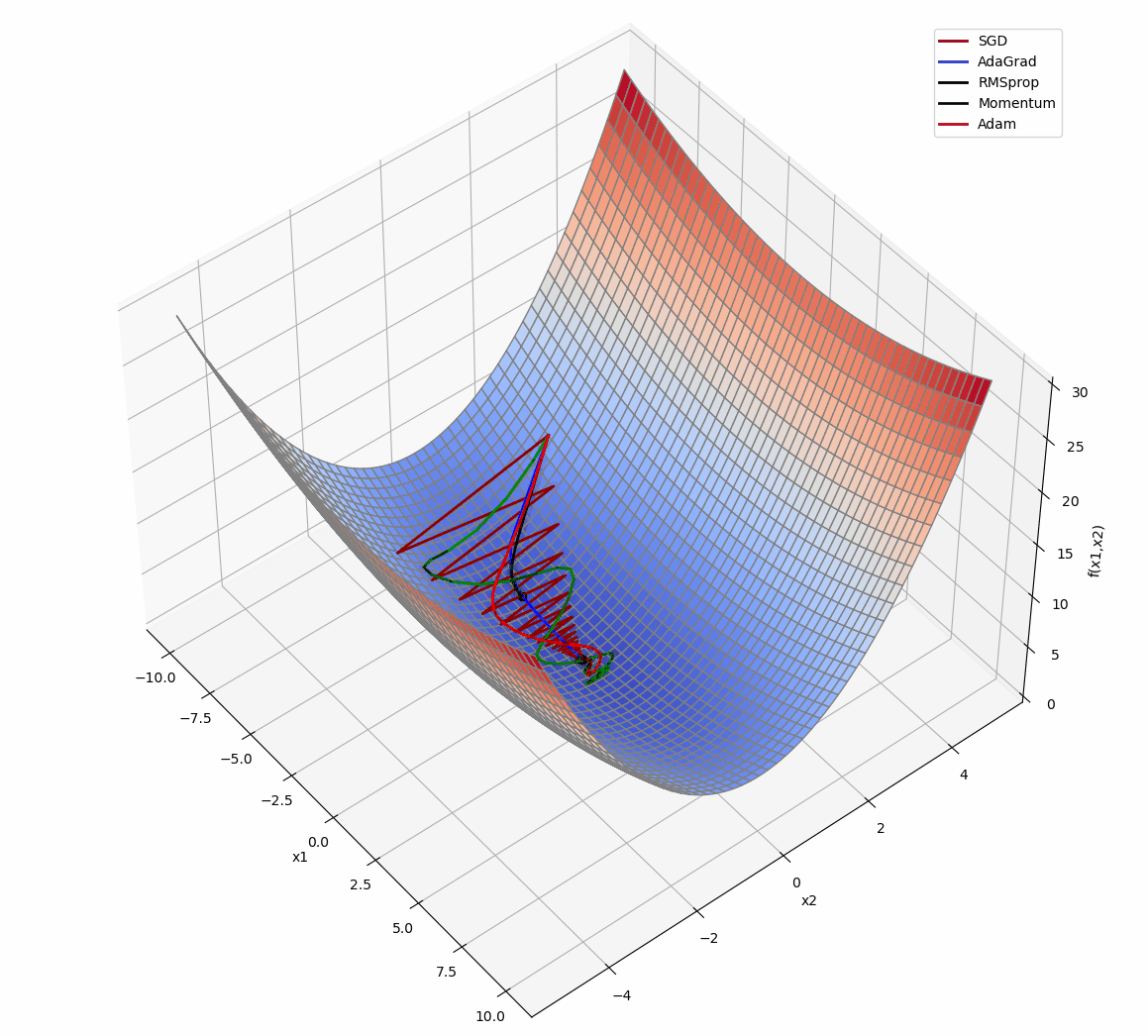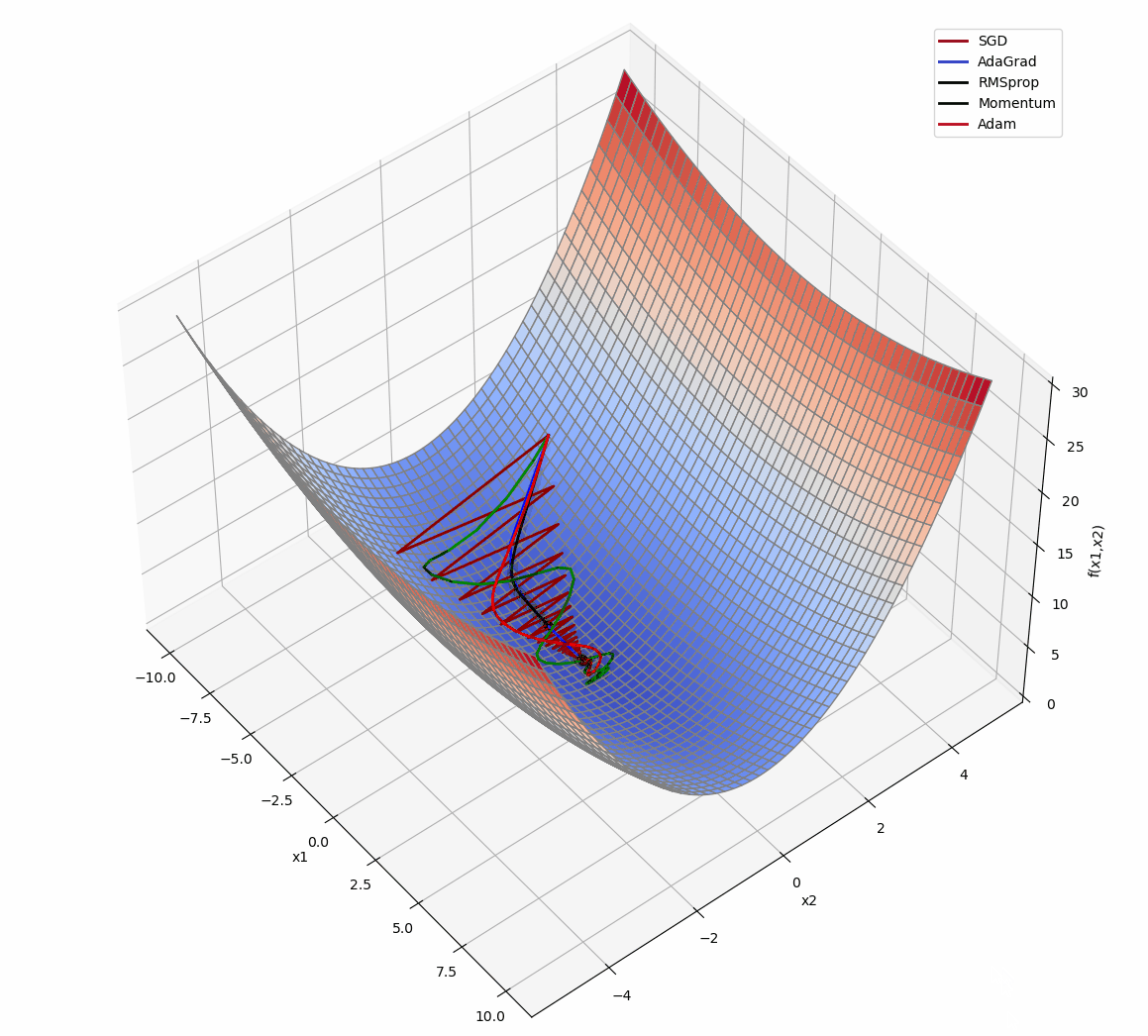
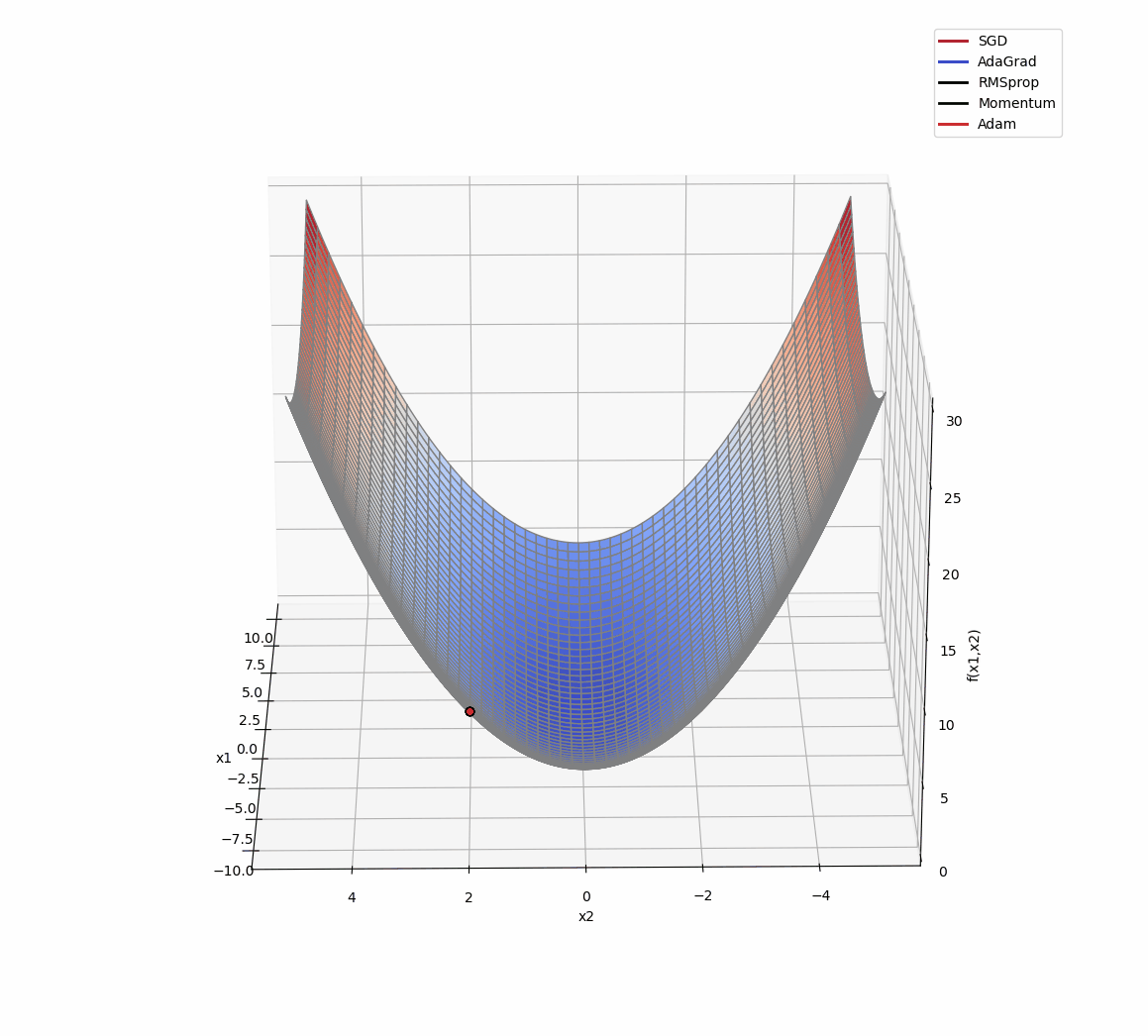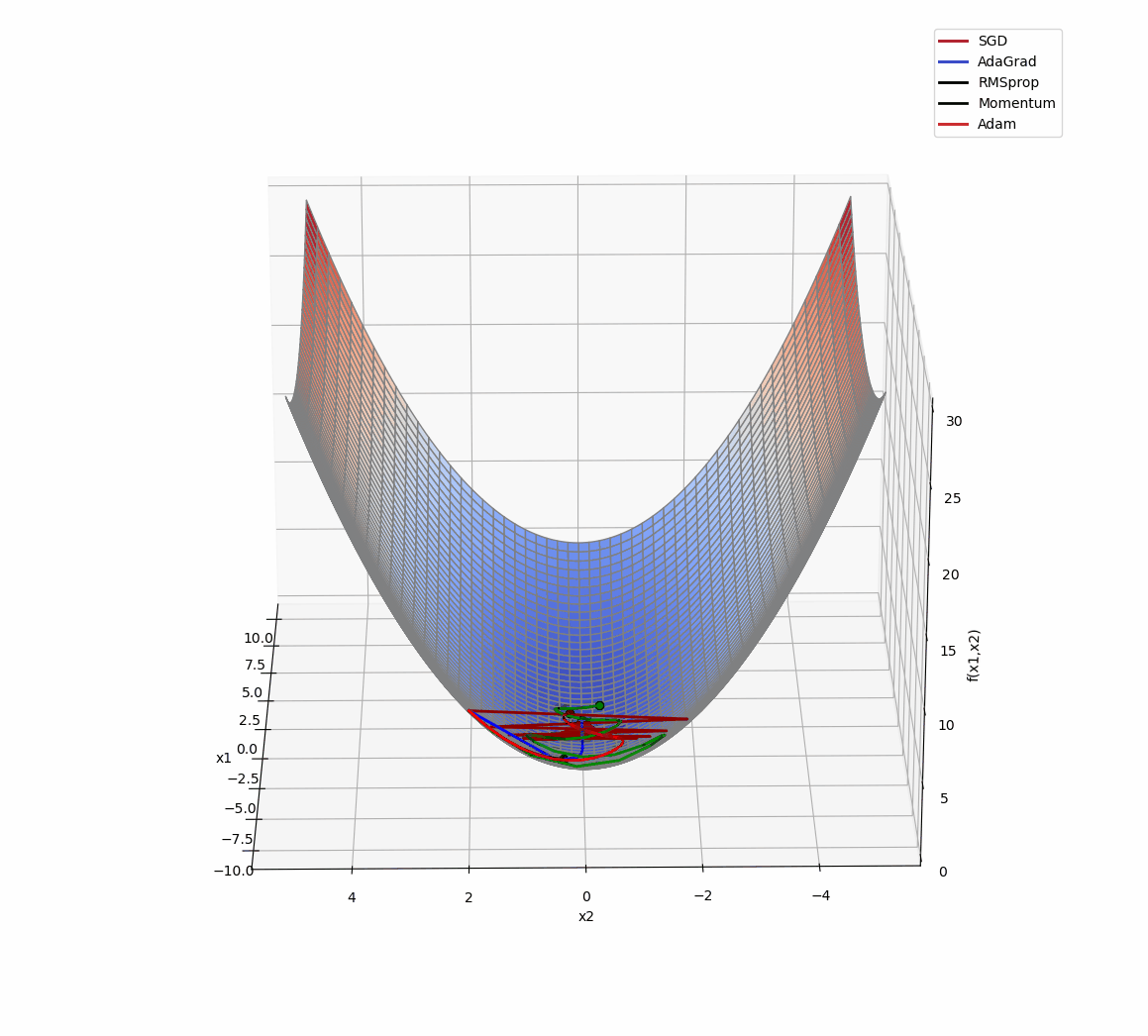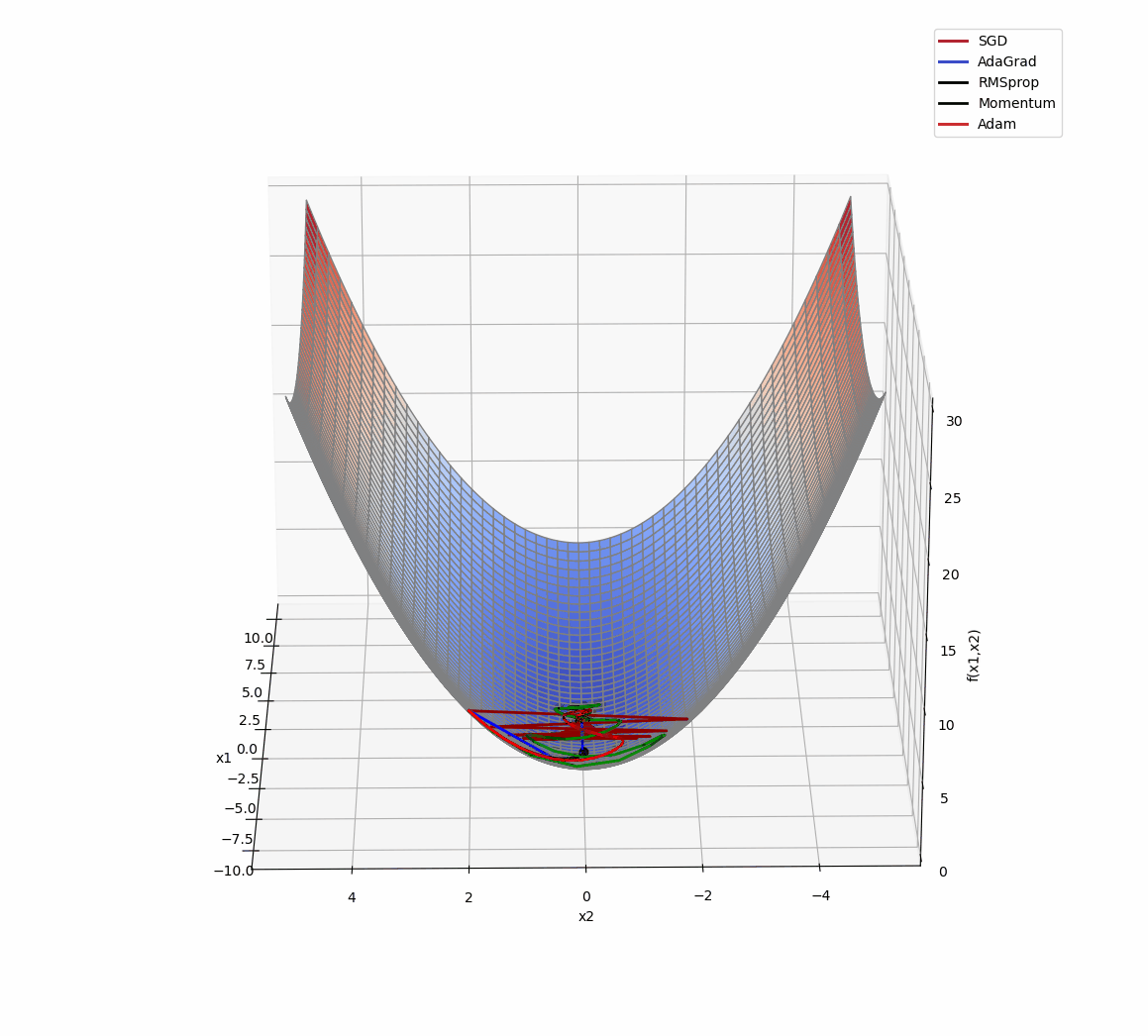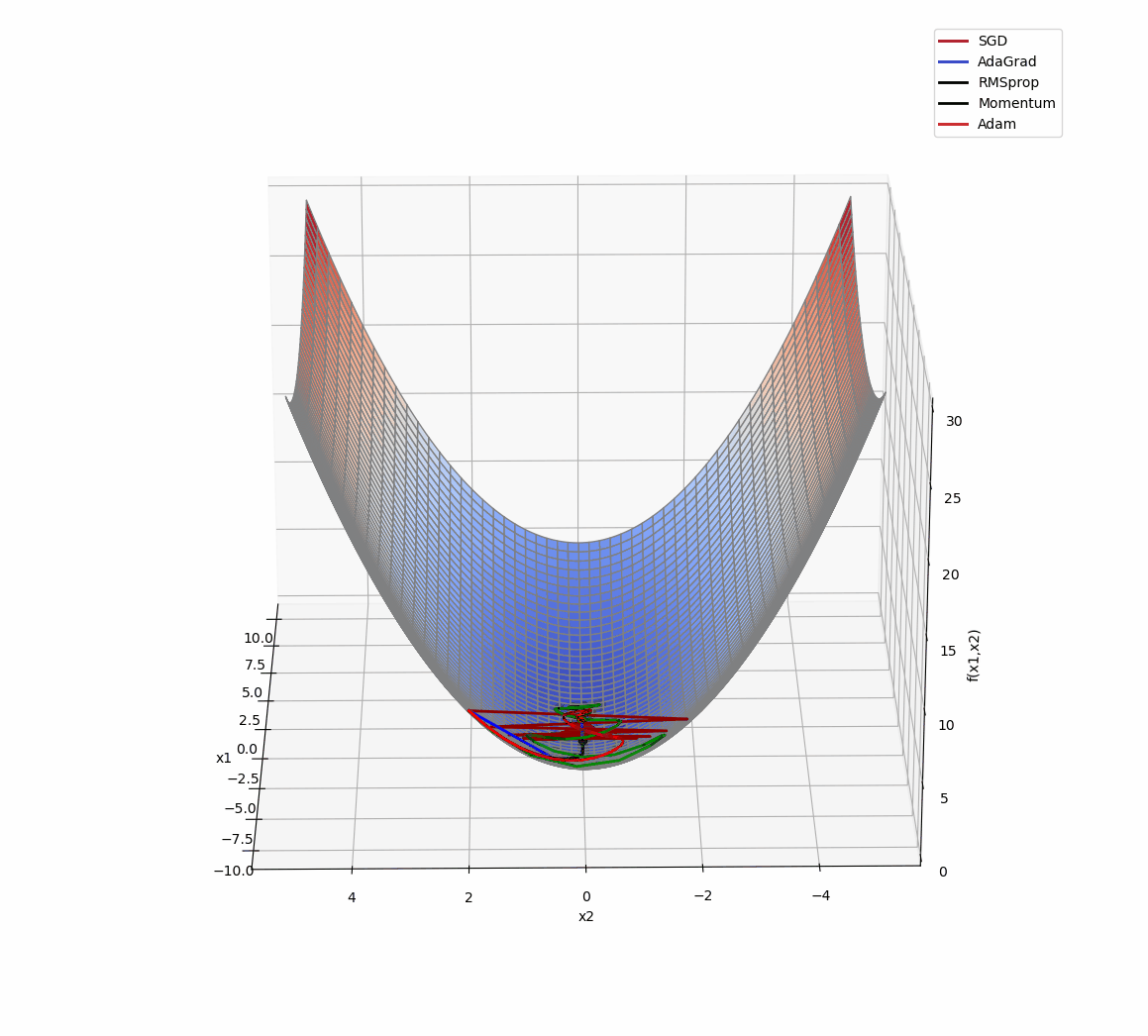
源代码:
import torch
import numpy as np
import copy
from matplotlib import pyplot as plt
from matplotlib import animation
from itertools import zip_longest
from matplotlib import cm
class Op(object):
def __init__(self):
pass
def __call__(self, inputs):
return self.forward(inputs)
# 输入:张量inputs
# 输出:张量outputs
def forward(self, inputs):
# return outputs
raise NotImplementedError
# 输入:最终输出对outputs的梯度outputs_grads
# 输出:最终输出对inputs的梯度inputs_grads
def backward(self, outputs_grads):
# return inputs_grads
raise NotImplementedError
class Optimizer(object): # 优化器基类
def __init__(self, init_lr, model):
"""
优化器类初始化
"""
# 初始化学习率,用于参数更新的计算
self.init_lr = init_lr
# 指定优化器需要优化的模型
self.model = model
def step(self):
"""
定义每次迭代如何更新参数
"""
pass
class SimpleBatchGD(Optimizer):
def __init__(self, init_lr, model):
super(SimpleBatchGD, self).__init__(init_lr=init_lr, model=model)
def step(self):
# 参数更新
if isinstance(self.model.params, dict):
for key in self.model.params.keys():
self.model.params[key] = self.model.params[key] - self.init_lr * self.model.grads[key]
class Adagrad(Optimizer):
def __init__(self, init_lr, model, epsilon):
"""
Adagrad 优化器初始化
输入:
- init_lr: 初始学习率 - model:模型,model.params存储模型参数值 - epsilon:保持数值稳定性而设置的非常小的常数
"""
super(Adagrad, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.epsilon = epsilon
def adagrad(self, x, gradient_x, G, init_lr):
"""
adagrad算法更新参数,G为参数梯度平方的累计值。
"""
G += gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""
参数更新
"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.adagrad(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
class RMSprop(Optimizer):
def __init__(self, init_lr, model, beta, epsilon):
"""
RMSprop优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta:衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(RMSprop, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.beta = beta
self.epsilon = epsilon
def rmsprop(self, x, gradient_x, G, init_lr):
"""
rmsprop算法更新参数,G为迭代梯度平方的加权移动平均
"""
G = self.beta * G + (1 - self.beta) * gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
class Momentum(Optimizer):
def __init__(self, init_lr, model, rho):
"""
Momentum优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- rho:动量因子
"""
super(Momentum, self).__init__(init_lr=init_lr, model=model)
self.delta_x = {}
for key in self.model.params.keys():
self.delta_x[key] = 0
self.rho = rho
def momentum(self, x, gradient_x, delta_x, init_lr):
"""
momentum算法更新参数,delta_x为梯度的加权移动平均
"""
delta_x = self.rho * delta_x - init_lr * gradient_x
x += delta_x
return x, delta_x
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key],
self.model.grads[key],
self.delta_x[key],
self.init_lr)
class Adam(Optimizer):
def __init__(self, init_lr, model, beta1, beta2, epsilon):
"""
Adam优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta1, beta2:移动平均的衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(Adam, self).__init__(init_lr=init_lr, model=model)
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.M, self.G = {}, {}
for key in self.model.params.keys():
self.M[key] = 0
self.G[key] = 0
self.t = 1
def adam(self, x, gradient_x, G, M, t, init_lr):
"""
adam算法更新参数
输入:
- x:参数
- G:梯度平方的加权移动平均
- M:梯度的加权移动平均
- t:迭代次数
- init_lr:初始学习率
"""
M = self.beta1 * M + (1 - self.beta1) * gradient_x
G = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2
M_hat = M / (1 - self.beta1 ** t)
G_hat = G / (1 - self.beta2 ** t)
t += 1
x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hat
return x, G, M, t
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key],
self.model.grads[key],
self.G[key],
self.M[key],
self.t,
self.init_lr)
class OptimizedFunction3D(Op):
def __init__(self):
super(OptimizedFunction3D, self).__init__()
self.params = {'x': 0}
self.grads = {'x': 0}
def forward(self, x):
self.params['x'] = x
return x[0] * x[0] / 20 + x[1] * x[1] / 1 # x[0] ** 2 + x[1] ** 2 + x[1] ** 3 + x[0] * x[1]
def backward(self):
x = self.params['x']
gradient1 = 2 * x[0] / 20
gradient2 = 2 * x[1] / 1
grad1 = torch.Tensor([gradient1])
grad2 = torch.Tensor([gradient2])
self.grads['x'] = torch.cat([grad1, grad2])
class Visualization3D(animation.FuncAnimation):
""" 绘制动态图像,可视化参数更新轨迹 """
def __init__(self, *xy_values, z_values, labels=[], colors=[], fig, ax, interval=100, blit=True, **kwargs):
"""
初始化3d可视化类
输入:
xy_values:三维中x,y维度的值
z_values:三维中z维度的值
labels:每个参数更新轨迹的标签
colors:每个轨迹的颜色
interval:帧之间的延迟(以毫秒为单位)
blit:是否优化绘图
"""
self.fig = fig
self.ax = ax
self.xy_values = xy_values
self.z_values = z_values
frames = max(xy_value.shape[0] for xy_value in xy_values)
self.lines = [ax.plot([], [], [], label=label, color=color, lw=2)[0]
for _, label, color in zip_longest(xy_values, labels, colors)]
self.points = [ax.plot([], [], [], color=color, markeredgewidth =1, markeredgecolor='black', marker='o')[0]
for _,color in zip_longest(xy_values, colors)]
# print(self.lines)
super(Visualization3D, self).__init__(fig, self.animate, init_func=self.init_animation, frames=frames,
interval=interval, blit=blit, **kwargs)
def init_animation(self):
# 数值初始化
for line in self.lines:
line.set_data_3d([], [], [])
for point in self.points:
point.set_data_3d([], [], [])
return self.points + self.lines
def animate(self, i):
# 将x,y,z三个数据传入,绘制三维图像
for line, xy_value, z_value in zip(self.lines, self.xy_values, self.z_values):
line.set_data_3d(xy_value[:i, 0], xy_value[:i, 1], z_value[:i])
for point, xy_value, z_value in zip(self.points, self.xy_values, self.z_values):
point.set_data_3d(xy_value[i, 0], xy_value[i, 1], z_value[i])
return self.points + self.lines
def train_f(model, optimizer, x_init, epoch):
x = x_init
all_x = []
losses = []
for i in range(epoch):
all_x.append(copy.deepcopy(x.numpy())) # 浅拷贝 改为 深拷贝, 否则List的原值会被改变。 Edit by David 2022.12.4.
loss = model(x)
losses.append(loss)
model.backward()
optimizer.step()
x = model.params['x']
return torch.Tensor(np.array(all_x)), losses
# 构建5个模型,分别配备不同的优化器
model1 = OptimizedFunction3D()
opt_gd = SimpleBatchGD(init_lr=0.95, model=model1)
model2 = OptimizedFunction3D()
opt_adagrad = Adagrad(init_lr=1.5, model=model2, epsilon=1e-7)
model3 = OptimizedFunction3D()
opt_rmsprop = RMSprop(init_lr=0.05, model=model3, beta=0.9, epsilon=1e-7)
model4 = OptimizedFunction3D()
opt_momentum = Momentum(init_lr=0.1, model=model4, rho=0.9)
model5 = OptimizedFunction3D()
opt_adam = Adam(init_lr=0.3, model=model5, beta1=0.9, beta2=0.99, epsilon=1e-7)
models = [model1, model2, model3, model4, model5]
opts = [opt_gd, opt_adagrad, opt_rmsprop, opt_momentum, opt_adam]
x_all_opts = []
z_all_opts = []
# 使用不同优化器训练
for model, opt in zip(models, opts):
x_init = torch.FloatTensor([-7, 2])
x_one_opt, z_one_opt = train_f(model, opt, x_init, 100) # epoch
# 保存参数值
x_all_opts.append(x_one_opt.numpy())
z_all_opts.append(np.squeeze(z_one_opt))
# 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-3, 3],以0.1为间隔的数值
x1 = np.arange(-10, 10, 0.01)
x2 = np.arange(-5, 5, 0.01)
x1, x2 = np.meshgrid(x1, x2)
init_x = torch.Tensor(np.array([x1, x2]))
model = OptimizedFunction3D()
# 绘制 f_3d函数 的 三维图像
fig = plt.figure()
ax = plt.axes(projection='3d')
X = init_x[0].numpy()
Y = init_x[1].numpy()
Z = model(init_x).numpy() # 改为 model(init_x).numpy() David 2022.12.4
surf = ax.plot_surface(X, Y, Z, edgecolor='grey', cmap=cm.coolwarm)
# fig.colorbar(surf, shrink=0.5, aspect=1)
# ax.set_zlim(-3, 2)
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_zlabel('f(x1,x2)')
labels = ['SGD', 'AdaGrad', 'RMSprop', 'Momentum', 'Adam']
colors = ['#8B0000', '#0000FF', '#000000', '#008B00', '#FF0000']
animator = Visualization3D(*x_all_opts, z_values=z_all_opts, labels=labels, colors=colors, fig=fig, ax=ax)
ax.legend(loc='upper right')
plt.show()
# animator.save('teaser' + '.gif', writer='imagemagick',fps=10) # 效果不好,估计被挡住了…… 有待进一步提高 Edit by David 2022.12.4
# save不好用,不费劲了,安装个软件做gif https://pc.qq.com/detail/13/detail_23913.html