第八章:PyTorch生态简介|第九章:PyTorch的模型部署
文章目录
-
- 第八章:PyTorch生态简介
-
- 8.1 torchtext简介
-
- 8.4.1 torchtext的主要组成部分
- 8.4.2 torchtext的安装
- 8.4.3 构建数据集
- 8.4.4 评测指标(metric)
- 8.4.5 其他
- 第九章:PyTorch的模型部署
-
- 9.1 使用ONNX进行部署并推理
-
- 9.1.1 ONNX和ONNX Runtime简介
-
- 9.1.1.1 ONNX简介
- 9.1.1.2 ONNX Runtime简介
- 9.1.1.3 ONNX和ONNX Runtime的安装
- 9.1.2 模型导出为ONNX
-
- 9.1.2.1 模型转换为ONNX格式
- 9.1.2.2 ONNX模型的检验
- 9.1.2.3 ONNX可视化
- 9.1.3 使用ONNX Runtime进行推理
- 9.1.4 代码实战
第八章:PyTorch生态简介
图片和视频处理:TorchVision、TorchVideo
自然语言处理:torchtext
图卷积网络:PyTorch Geometric
8.1 torchtext简介
因为在学NLP,因此主要了解自然语言处理(NLP)的工具包torchtext。
8.4.1 torchtext的主要组成部分
torchtext可以方便的对文本进行预处理,例如截断补长、构建词表等。
torchtext主要包含了以下的主要组成部分:
- 数据处理工具 torchtext.data.functional、torchtext.data.utils
- 数据集 torchtext.data.datasets
- 词表工具 torchtext.vocab
- 评测指标 torchtext.metrics
8.4.2 torchtext的安装
torchtext可以直接使用pip进行安装:
pip install torchtext
8.4.3 构建数据集
Field是torchtext中定义数据类型以及转换为张量的指令。torchtext 认为一个样本是由多个字段(文本字段,标签字段)组成,不同的字段可能会有不同的处理方式,所以才会有 Field 抽象。定义Field对象是为了明确如何处理不同类型的数据,但具体的处理则是在Dataset中完成的。
- Field的使用举例
tokenize = lambda x: x.split()
TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True, fix_length=200)
LABEL = data.Field(sequential=False, use_vocab=False)
其中:
squential:数据是否为序列数据,默认为Ture。如果为False,则不能使用分词。
use_vocab:是否使用词典,默认为True。如果为False,那么输入的数据类型必须是数值类型(即使用vocab转换后的)。
init_token:文本的其实字符,默认为None。
eos_token:文本的结束字符,默认为None。
fix_length:所有样本的长度,不够则使用pad_token补全。默认为None,表示灵活长度。
tensor_type:把数据转换成的tensor类型 默认值为torch.LongTensor。
preprocessing:预处理pipeline, 用于分词之后、数值化之前,默认值为None。
postprocessing:后处理pipeline,用于数值化之后、转换为tensor之前,默认为None。
lower:是否把数据转换为小写,默认为False;
tokenize:分词函数,默认为str.split
include_lengths:是否返回一个已经补全的最小batch的元组和和一个包含每条数据长度的列表,默认值为False。
batch_first:batch作为第一个维度;
pad_token:用于补全的字符,默认为。
unk_token:替换袋外词的字符,默认为。
pad_first:是否从句子的开头进行补全,默认为False;
truncate_first:是否从句子的开头截断句子,默认为False;
stop_words:停用词;
tokenize = lambda x: x.split()*#将英文句子x单词化。*
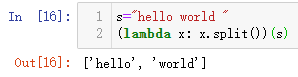
- 构建dataset
from torchtext import data
def get_dataset(csv_data, text_field, label_field, test=False):
fields = [("id", None), # we won't be needing the id, so we pass in None as the field
("comment_text", text_field), ("toxic", label_field)]
examples = []
if test:
# 如果为测试集,则不加载label
for text in tqdm(csv_data['comment_text']):
examples.append(data.Example.fromlist([None, text, None], fields))
else:
for text, label in tqdm(zip(csv_data['comment_text'], csv_data['toxic'])):
examples.append(data.Example.fromlist([None, text, label], fields))
return examples, fields
这里使用数据csv_data中有"comment_text"和"toxic"两列,分别对应text和label。
train_data = pd.read_csv('train_toxic_comments.csv')
valid_data = pd.read_csv('valid_toxic_comments.csv')
test_data = pd.read_csv("test_toxic_comments.csv")
TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True)
LABEL = data.Field(sequential=False, use_vocab=False)
# 得到构建Dataset所需的examples和fields
train_examples, train_fields = get_dataset(train_data, TEXT, LABEL)
valid_examples, valid_fields = get_dataset(valid_data, TEXT, LABEL)
test_examples, test_fields = get_dataset(test_data, TEXT, None, test=True)
# 构建Dataset数据集
train = data.Dataset(train_examples, train_fields)
valid = data.Dataset(valid_examples, valid_fields)
test = data.Dataset(test_examples, test_fields)
定义Field对象完成后,通过get_dataset函数可以读入数据的文本和标签,将二者(examples)连同field一起送到torchtext.data.Dataset类中,即可完成数据集的构建。
使用以下命令可以看下读入的数据情况:
# 检查keys是否正确
print(train[0].__dict__.keys())
print(test[0].__dict__.keys())
# 抽查内容是否正确
print(train[0].comment_text)
- 词汇表(vocab)
在NLP中,将字符串形式的词语(word)转变为数字形式的向量表示(embedding)是非常重要的一步,被称为Word Embedding。这一步的基本思想是收集一个比较大的语料库(尽量与所做的任务相关),在语料库中使用word2vec之类的方法构建词语到向量(或数字)的映射关系,之后将这一映射关系应用于当前的任务,将句子中的词语转为向量表示。
在torchtext中可以使用Field自带的build_vocab函数完成词汇表构建。
TEXT.build_vocab(train)
- 数据迭代器
可以理解为torchtext中的DataLoader
from torchtext.data import Iterator, BucketIterator
# 若只针对训练集构造迭代器
# train_iter = data.BucketIterator(dataset=train, batch_size=8, shuffle=True, sort_within_batch=False, repeat=False)
# 同时对训练集和验证集进行迭代器的构建
train_iter, val_iter = BucketIterator.splits(
(train, valid), # 构建数据集所需的数据集
batch_sizes=(8, 8),
device=-1, # 如果使用gpu,此处将-1更换为GPU的编号
sort_key=lambda x: len(x.comment_text), # the BucketIterator needs to be told what function it should use to group the data.
sort_within_batch=False
)
test_iter = Iterator(test, batch_size=8, device=-1, sort=False, sort_within_batch=False)
torchtext支持只对一个dataset和同时对多个dataset构建数据迭代器。
- 使用自带数据集
torchtext提供若干常用的数据集方便快速进行算法测试。可以查看官方文档寻找想要使用的数据集。
8.4.4 评测指标(metric)
NLP中部分任务的评测不是通过准确率等指标完成的,比如机器翻译任务常用BLEU (bilingual evaluation understudy) score来评价预测文本和标签文本之间的相似程度。torchtext中可以直接调用torchtext.data.metrics.bleu_score来快速实现BLEU,下面是一个官方文档中的一个例子:
from torchtext.data.metrics import bleu_score
candidate_corpus = [['My', 'full', 'pytorch', 'test'], ['Another', 'Sentence']]
references_corpus = [[['My', 'full', 'pytorch', 'test'], ['Completely', 'Different']], [['No', 'Match']]]
bleu_score(candidate_corpus, references_corpus)
0.8408964276313782
8.4.5 其他
由于NLP常用的网络结构比较固定,torchtext并不像torchvision那样提供一系列常用的网络结构。模型主要通过torch.nn中的模块来实现,比如torch.nn.LSTM、torch.nn.RNN等。
第九章:PyTorch的模型部署
9.1 使用ONNX进行部署并推理
我们会将PyTorch训练好的模型转换为ONNX 格式,然后使用ONNX Runtime运行它进行推理。
9.1.1 ONNX和ONNX Runtime简介
9.1.1.1 ONNX简介
- ONNX官网:https://onnx.ai/
- ONNX GitHub:https://github.com/onnx/onnx
ONNX( Open Neural Network Exchange) 是 Facebook (现Meta) 和微软在2017年共同发布的,用于标准描述计算图的一种格式。ONNX通过定义一组与环境和平台无关的标准格式,使AI模型可以在不同框架和环境下交互使用,ONNX可以看作深度学习框架和部署端的桥梁,就像编译器的中间语言一样。由于各框架兼容性不一,我们通常只用 ONNX 表示更容易部署的静态图。硬件和软件厂商只需要基于ONNX标准优化模型性能,让所有兼容ONNX标准的框架受益。目前,ONNX主要关注在模型预测方面,使用不同框架训练的模型,转化为ONNX格式后,可以很容易的部署在兼容ONNX的运行环境中。目前,在微软,亚马逊 ,Facebook(现Meta) 和 IBM 等公司和众多开源贡献的共同维护下,ONNX 已经对接了下图的多种深度学习框架和多种推理引擎。
9.1.1.2 ONNX Runtime简介
- ONNX Runtime官网:https://www.onnxruntime.ai/
- ONNX Runtime GitHub:https://github.com/microsoft/onnxruntime
ONNX Runtime 是由微软维护的一个跨平台机器学习推理加速器,它直接对接ONNX,可以直接读取.onnx文件并实现推理,不需要再把 .onnx 格式的文件转换成其他格式的文件。PyTorch借助ONNX Runtime也完成了部署的最后一公里,构建了 PyTorch --> ONNX --> ONNX Runtime 部署流水线,我们只需要将模型转换为 .onnx 文件,并在 ONNX Runtime 上运行模型即可。
9.1.1.3 ONNX和ONNX Runtime的安装
ONNX和ONNX Runtime作为python的一个包与其他包的安装方法相同,我们可以选择使用conda或者pip进行安装,只需要输入以下命令即可:
# 激活虚拟环境
conda activate env_name # env_name换成环境名称
# 安装onnx
pip install onnx
# 安装onnx runtime
pip install onnxruntime # 使用CPU进行推理
# pip install onnxruntime-gpu # 使用GPU进行推理
除此之外,我们还需要注意ONNX和ONNX Runtime之间的适配关系。我们可以访问ONNX Runtime的Github进行查看,链接地址如下:
ONNX和ONNX Runtime的适配关系:https://github.com/microsoft/onnxruntime/blob/master/docs/Versioning.md
当我们想使用GPU进行推理时,我们需要先将安装的onnxruntime卸载,再安装onnxruntime-gpu,同时我们还需要考虑ONNX Runtime与CUDA之间的适配关系,我们可以参考以下链接进行查看:
ONNX Runtime和CUDA之间的适配关系:https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html
9.1.2 模型导出为ONNX
9.1.2.1 模型转换为ONNX格式
在接下来的部分,我们将使用torch.onnx.export()把模型转换成 ONNX 格式的函数。模型导成onnx格式前,我们必须调用model.eval()或者model.train(False)以确保我们的模型处在推理模式下,避免因为dropout或batchnorm等运算符在推理和训练模式下的不同产生错误。
import torch.onnx
# 转换的onnx格式的名称,文件后缀需为.onnx
onnx_file_name = "xxxxxx.onnx"
# 我们需要转换的模型,将torch_model设置为自己的模型
model = torch_model
# 加载权重,将model.pth转换为自己的模型权重
# 如果模型的权重是使用多卡训练出来,我们需要去除权重中多的module. 具体操作可以见5.4节
model = model.load_state_dict(torch.load("model.pth"))
# 导出模型前,必须调用model.eval()或者model.train(False)
model.eval()
# dummy_input就是一个输入的实例,仅提供输入shape、type等信息
batch_size = 1 # 随机的取值,当设置dynamic_axes后影响不大
dummy_input = torch.randn(batch_size, 1, 224, 224, requires_grad=True)
# 这组输入对应的模型输出
output = model(dummy_input)
# 导出模型
torch.onnx.export(model, # 模型的名称
dummy_input, # 一组实例化输入
onnx_file_name, # 文件保存路径/名称
export_params=True, # 如果指定为True或默认, 参数也会被导出. 如果你要导出一个没训练过的就设为 False.
opset_version=10, # ONNX 算子集的版本,当前已更新到15
do_constant_folding=True, # 是否执行常量折叠优化
input_names = ['input'], # 输入模型的张量的名称
output_names = ['output'], # 输出模型的张量的名称
# dynamic_axes将batch_size的维度指定为动态,
# 后续进行推理的数据可以与导出的dummy_input的batch_size不同
dynamic_axes={'input' : {0 : 'batch_size'},
'output' : {0 : 'batch_size'}})
9.1.2.2 ONNX模型的检验
当上述代码运行成功后,我们会得到一个ONNX 模型文件。我们需要检测下我们的模型文件是否可用,我们将通过onnx.checker.check_model()进行检验,具体方法如下:
import onnx
# 我们可以使用异常处理的方法进行检验
try:
# 当我们的模型不可用时,将会报出异常
onnx.checker.check_model(self.onnx_model)
except onnx.checker.ValidationError as e:
print("The model is invalid: %s"%e)
else:
# 模型可用时,将不会报出异常,并会输出“The model is valid!”
print("The model is valid!")
9.1.2.3 ONNX可视化
在将模型导出为onnx格式后,Netron可以实现onnx的可视化。
9.1.3 使用ONNX Runtime进行推理
使用ONNX Runtime运行一下转化后的模型,看一下推理后的结果。
# 导入onnxruntime
import onnxruntime
# 需要进行推理的onnx模型文件名称
onnx_file_name = "xxxxxx.onnx"
# onnxruntime.InferenceSession用于获取一个 ONNX Runtime 推理器
ort_session = onnxruntime.InferenceSession(onnx_file_name)
# 构建字典的输入数据,字典的key需要与我们构建onnx模型时的input_names相同
# 输入的input_img 也需要改变为ndarray格式
ort_inputs = {'input': input_img}
# 我们更建议使用下面这种方法,因为避免了手动输入key
# ort_inputs = {ort_session.get_inputs()[0].name:input_img}
# run是进行模型的推理,第一个参数为输出张量名的列表,一般情况可以设置为None
# 第二个参数为构建的输入值的字典
# 由于返回的结果被列表嵌套,因此我们需要进行[0]的索引
ort_output = ort_session.run(None,ort_inputs)[0]
# output = {ort_session.get_outputs()[0].name}
# ort_output = ort_session.run([output], ort_inputs)[0]
在上述的步骤中,我们有几个需要注意的点:
- PyTorch模型的输入为tensor,而ONNX的输入为array,因此我们需要对张量进行变换或者直接将数据读取为array格式,我们可以实现下面的方式进行张量到array的转化。
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
- 输入的array的shape应该和我们导出模型的
dummy_input的shape相同,如果图片大小不一样,我们应该先进行resize操作。 - run的结果是一个列表,我们需要进行索引操作才能获得array格式的结果。
- 在构建输入的字典时,我们需要注意字典的key应与导出ONNX格式设置的input_name相同,因此我们更建议使用上述的第二种方法构建输入的字典。
9.1.4 代码实战
本部分代码选自PyTorch官网示例代码,访问链接可点击下方推荐阅读2进行查看和使用官网提供的Colab对onnx导出进行进一步理解。
具体参考:https://datawhalechina.github.io/thorough-pytorch/%E7%AC%AC%E4%B9%9D%E7%AB%A0/9.1%20%E4%BD%BF%E7%94%A8ONNX%E8%BF%9B%E8%A1%8C%E9%83%A8%E7%BD%B2%E5%B9%B6%E6%8E%A8%E7%90%86.html