python编程问题--第三次
20210528
iter(a,b) a 是可迭代对象,b是哨符,迭代a的时候遇到b 就停止

any和all
g1,g2=itertools.tee(‘ABC’)
产生多个生成器
生成器用完之后就没有了
https://blog.csdn.net/GeorgeAI/article/details/81035422
glob.glob
返回所有匹配的文件路径列表。
if not peaks_list
如果为空值
https://www.cnblogs.com/andylhc/p/9481636.html
计算两个坐标的距离
https://www.cnblogs.com/LaoYuanPython/p/11094168.html
Python类中内置的查看直接父类的__bases__属性:得到直接父类
https://www.runoob.com/python/python-func-staticmethod.html
@staticmethod
https://www.cnblogs.com/elie/p/5876210.html
staticmethod和classmethod的区别
static:在类里面直接当做函数使用 不需要先实例化
类和实例都可以直接调用
class:类本身直接调用,不需要先实例化之后再调用
类中普通方法:需要实例化之后才能调用
https://blog.csdn.net/a__int__/article/details/104600972
python中super().init() 的作用
https://blog.csdn.net/weixin_30451709/article/details/99252255
supper 传参
两个参数的时候并且第一个参数是类(当前类或父类),第二个是实例的时候
即super()是根据第二个参数(obj)来计算MRO,根据顺序查找第一个参数(类)之后的类的方法
https://www.cnblogs.com/miyauchi-renge/p/10923127.html
https://www.cnblogs.com/lovemo1314/archive/2011/05/03/2035005.html
https://blog.csdn.net/lee2315/article/details/83375787
记录python multiprocessing Pool的map和apply_async方法
https://blog.csdn.net/gqixf/article/details/80180640
os.mkdir 和 os.makedirs的区别
makedirs创建多层目录
安装yamL 文件报错:Could not find a version that satisfies the requirement yaml (from versions: ) No matchi…
https://blog.csdn.net/bangqiong7439/article/details/101078306
20210421
break 中断的是当前的for循环值,后面的值仍然继续循环 并不是整个for循环的中断
pycharm爆内存不足
很有可能是保存csv的时候 产生的临时文件过多所致
直接删除就好
20210415
assert isSorted(a) 判断是否成立 返回布尔值
20210408
https://blog.csdn.net/u012111465/article/details/85053824
原则组成的列表转成字典
https://www.php.cn/python-tutorials-423840.html
python字典合并
1《Python 20个专题下载》链接: https://pan.baidu.com/s/1EbnbOClIsR7GSqvxQEwHIA 提取码: fjtw
2 《Pandas数据分析小技巧手册1.0》链接: https://pan.baidu.com/s/16McVmGdhOkXKmAvwF9XNgQ 提取码: erb5
3 可视化选图指南 链接: https://pan.baidu.com/s/1GAApobJ40UlkEB8ZdErVVg 提取码: bjp5
4 泰坦尼克 链接: https://pan.baidu.com/s/1GAApobJ40UlkEB8ZdErVVg 提取码: bjp5
5 《10个可视化作品》链接: https://pan.baidu.com/s/1HFuRn5TR59R3IHRxFVLiSA 提取码: utmk
6 《Python速查表V 0.1》链接: https://pan.baidu.com/s/1l2ihbJ9yeEWI68ro3bm2WQ 提取码: vsw9
7 pandas null问题和extract方法 链接: https://pan.baidu.com/s/1l2ihbJ9yeEWI68ro3bm2WQ 提取码: vsw9 复制这段内容后打开百度网盘手机App,操作更方便哦
8 《图解入门NumPy》 链接: https://pan.baidu.com/s/1tsZ6Juklrtfwubq9PD1EnA 提取码: 2we1
9 《NumPy 100 题原版》 链接: https://pan.baidu.com/s/1fSb-jrikVtJzfW5NYvqXSw 提取码: 99gb
10 《NumPy 100 页精华》 链接: https://pan.baidu.com/s/1fsL2DQxmaW0CvVYyE5il3w 提取码: iy93
11 《爬虫23个小项目》 链接: https://pan.baidu.com/s/1Or-Mk24FRBYJOeToLk9b8w 提取码: nb71
12 《matplotlib Plotting Cookbook》链接: https://pan.baidu.com/s/1BjlgXb8KV-qTmz1rquFJcw 提取码: tyjv
13 《pandas-75-exercises-with-solutions》链接: https://pan.baidu.com/s/1disOjK7l4Ugz4GQXy0CH-A 提取码: tnbp
14 kaggle 数据集精选 链接: https://pan.baidu.com/s/1fzoNZXA1aKQexMYN1LnL8w 提取码: 2416
15 动态规划入门 链接: https://pan.baidu.com/s/11RZ1_ZpyFrXic0EffElB4w 提取码: ehj5
16 pandas-data-align.ipynb 链接: https://pan.baidu.com/s/1TgC-noQDUa_ofBexWs4Abw 提取码: d7nb
17 《Python一行代码》链接: https://pan.baidu.com/s/1zlnMEO4I01gMGvdCRJZyRw 提取码: v5it
18 生命游戏 链接: https://pan.baidu.com/s/1CBHuvx3fEwjg4Q4oWINTZw 提取码: jyui
19 数据分析学习路线 链接: https://pan.baidu.com/s/1mq90AgigzUuL5eRWNxliYg 提取码: 6szn
20 8 张Python高清知识图谱 链接: https://pan.baidu.com/s/1ge0bFamRTKg4ceyKvTX8tA 提取码: 7t4d
21 Google+Python+Style+Guide中文版(4).pdf 链接: https://pan.baidu.com/s/1iJd_lfe_g9VqnXGxyeiJkQ 提取码: d1k8
22 Python基础到进阶90例.zip 链接: https://pan.baidu.com/s/17raLKcPuJvkQkEtpod2WNA 提取码: 7hxy
23 Python之路 链接: https://pan.baidu.com/s/11RROgFE9y1Hf_VyGRK6k7A 提取码: ud48
24 《神经网络与深度学习》链接: https://pan.baidu.com/s/1KjGkUutJEi3Rhfd02YwuSQ 提取码: mudk
25 《统计学习方法》课件链接: https://pan.baidu.com/s/10_WaXBfeyGFSqds9ksbRhA 提取码: ekay
26 Probabilistic Graphical Models - Principles and Techniques.pdf 链接: https://pan.baidu.com/s/1eRPZr3c3_Ki5AHZ3JQMeuA 提取码: pewd
27 算法刷题日记(Day0-Day44).pdf 链接: https://pan.baidu.com/s/1n9UcUzuknmped_8ahMhKPA 提取码: 49ky
28 DataStructuresAndAlgorithmWithPython.pdf 链接: https://pan.baidu.com/s/1t-TjpzDcozHyHa8-xP_6CA 提取码: zqxc
29 Machine learning an algorithmic perspective2.pdf 链接: https://pan.baidu.com/s/1QUDv2-mzMXKyzBbwefivlA 提取码: v4dk
30 《deep learning》链接: https://pan.baidu.com/s/11upcXQw3d2D1cG5GE1qqNQ 提取码: rrdb
31 PRML 链接: https://pan.baidu.com/s/1HbQNyMId5MmfITTfmtnEIQ 提取码: 6tvc
32 Python Projects for Beginners.pdf 链接: https://pan.baidu.com/s/1-T56dAa0sueWQJ5px09ZWw 提取码: ucsq
33 Learn Data Analysis with Python 链接: https://pan.baidu.com/s/1oBgRUXKFCKMx3fv2OSwD1A 提取码: y5ms
https://blog.csdn.net/weixin_40787712/article/details/105020875
最全面的 Python 重点
20210402
pandas.DataFrame.copy
DataFrame.copy(deep=True)
深度复制
20210326
http://pythontutor.com/visualize.html
看python运行过程的网站
内存动态图
Java代码中的Unicode字符表示形式,比如:
\u0022
\u005c
这个unicode_escape是什么?将unicode的内存编码值进行存储,读取文件时在反向转换回来。这里就采用了unicode-escape的方式
open 要以什么样的编码保存的时候在open函数里面进行设置
with open(path_save+'2500.json','w',encoding='utf_8') as f:
json.dump(bc,f,ensure_ascii=False)
设置encoding参数
https://blog.csdn.net/disasters/article/details/85010134
# 写入 JSON 数据
with open('data.json', 'w') as f:
json.dump(data, f)
# 读取数据
with open('data.json', 'r') as f:
data = json.load(f)
20210324
https://www.runoob.com/w3cnote/python-check-whether-a-file-exists.html
判断是否是文件夹
判断是否是目录
20210320
c = c.encode('utf-8').decode('unicode_escape')
编码成unicode
f='\u53eb\u6211'
print f
print(f.decode('unicode-escape'))
unicode 解码
字节码转字符
name_uni=name.encode('unicode_escape')
name_str=str(name_uni,'utf_8')
name_str=name_str.replace('u','uni')
name_str=name_str.replace('\\',',')
name_str=name_str.split(',')
name_str=name_str[1:]
https://baijiahao.baidu.com/s?id=1647737291661719316&wfr=spider&for=pc
创建文件夹
https://blog.csdn.net/weixin_36896856/article/details/108016558
python下载文件
https://blog.csdn.net/wjhsg/article/details/81293341
python 管道

gen1:挂起生成器1
next(gen1): 挂起gen2
gen1和gen2 都有yield 相当于两个生成器的嵌套 像协程但不是
协程在一个线程中跳转
异步协程:全局生成器变量以便在模块所有地方都能调用.
next 方法激活生成器,运行到 yield的时候创建线程并暂停(挂起),同时相应后面的请求
,gen.send 再唤醒生成器 并返回数据,A在继续往下执行

回调:函数嵌套函数,传入的也是函数,待run执行完之后得到的
数据再传给 cb函数执行
通过继承,装饰器,添加新的功能,
空值的判断
if not none:
orm:高层封装 封装成简单的对象调用方法 对用户屏蔽细节

isinstance:判断数据的类型
单例类:当前程序任何地点创建的当前类的对象是唯一的
多个线程的时候可能会创建出多个 线程冲突 不安全
要安全加线程锁
类方法:直接类调用的方法 而不是实例调用的方法
代码规范化参考tornado精讲
20210317

r可以理解为正则表达式把

作为包来用的时候 需要有个_init_文件 空白的

类名大写?
模块名小写?
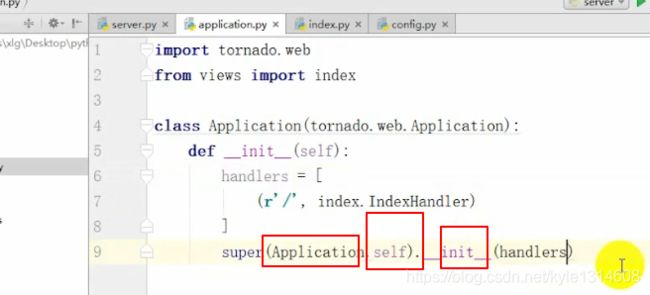
子类,子类实例 调用 父类的 init

形参命名可以比较随意一点
变量也可以通过一个包直接导入和调用
单引号和双引号功能差不多 同时出现的时候 交替包裹对方 里面作为一个整体
解决redis-cli连接时出现Could not connect to Redis at 127.0.0.1:6379: Connection refused
卸载掉控制台安装的redis 使用系统环境安装的redis 二者冲突
modin问题
https://blog.csdn.net/W_317/article/details/104294525
路径 windows和linux都支持反斜杠 就都用反斜杠好了
http状态码
https://www.runoob.com/http/http-status-codes.html
给变量赋值 两种方式
通过命令行或者配置文件
https://blog.csdn.net/weixin_41010198/article/details/89359586
python 判断是否属于某个类或者实例
https://www.cnblogs.com/xiao-xue-di/p/11414210.html
字符串转字典
json转
eval转
if data.__class__.__name__=='bytes':
data = eval(data)
elif data.__class__.__name__=='str':
data = json.loads(data)
while 不清楚具体的循环次数 for知道具体的循环次数
20210316

要把类中一部分处理过程放到类外面传入的是self,类实例 而不是 myrequests 类本身
https://www.runoob.com/python3/python3-func-sorted.html
sort和sorted
https://blog.csdn.net/qq_20412595/article/details/82990515
python os 路径
os.listdir(path)
列出path下所有子路径
https://blog.csdn.net/zyx_ly/article/details/87286607
递归列出所有路径
中文报错SyntaxError: Non-UTF-8 code starting with '\xe6' in file
代码最上面加上编码格式
#coding:utf-8
from run_lgbm import lgbm_mode
可以直接import 类和模块
from 包
20210315
https://blog.csdn.net/qq_24499417/article/details/81428594
pandas处理json
20210315
错误redis.exceptions.AuthenticationError: Client sent AUTH, but no password is set
https://blog.csdn.net/lang_niu/article/details/104430305
redis.exceptions.ConnectionError: Error 10061 connecting to 127.0.0.1:6379. 由于目标计算机积极拒绝,无法连接
https://blog.csdn.net/qq_41192383/article/details/86559296
20210304
cycle_nums=[int(normal_nums/3) for i in range(1) if normal_nums>3][0]
判断要传出来 用 列表生成式解决
TypeError: unhashable type: 'list'
字典的key键是可变对象
bisect:python 二分查找
https://docs.python.org/zh-cn/3/reference/
Python 语言参考手册
https://www.runoob.com/python/python-func-exec.html
exec :执行字符串里面的Python语句
eval
硬编码:就是某个参数被写死
https://segmentfault.com/q/1010000010645067
aiohttp.request()
aiohttp.ClientSession().get()
区别
函数可以传入函数 传入的是函数名
def func_name( input_func_name):
sys.stdout.flush()
刷新缓冲区的意思是 把缓冲区的内容读出来(或者打印出来) 清空缓冲区
只有不能改变的对象才能做为字典的key
列表就不行
[[1,1],[1,1]]
list中有列表,且子列表都相同的时候
改变其中一个子列表 所有子列表都会改变?
列表最好深度copy
20210224
python and or & | 区别
字典直接转换为列表 就把 键转换为了列表
Python中,&是位运算,而and 是依据是否非0来输出。
代码
// An highlighted block
print(8&9)
结:1:8
print(8 and 9)
结果2:9
print(0 and 9)
结果3:0
结果1:8的二进制是1000,9的二进制是1001,对应每个二进制位上进行与操作,得到二进制1000,转化十进制就是8
结果2:8不为0,则输出后面一个9
结果3:and前一个是0为否,输出0
当运算符两边的值为True 和False的时候 两种方式的结果都可以用
2
0210224
ValueError: setting an array element with a sequence
append的时候,前后数组 shape不一致导致的。导致输入训练集不同文本,维度不一致
20210222
https://blog.csdn.net/qm5132/article/details/100557950
getsizeof:并非按元素个数大小成比例增加
(1)sys.getsizeof只计算实际使用的内存大小,引用所消耗的内存大小不计算。
(2)sys.getsizeof只能作为计算内存大小的参考~
20210210
https://blog.csdn.net/weixin_42615068/article/details/90667186
鸭子类型和白鹅类型
白鹅必须继承自某个类 然后实现此类所涉及的方法,而鸭子只需要有某些方法的实现即可
鸭子类型
https://blog.csdn.net/handsomekang/article/details/40270009
https://www.jianshu.com/p/e97044a8169a
在面向对象编程中,协议是非正式的接口,只在文档中定义,在代码中
不定义。例如,Python 的序列协议只需要 __len__ 和 __getitem__ 两
个方法。
https://blog.csdn.net/weixin_38104872/article/details/78826948
itertools.chain
20210206
编码只能在原始字符串上面编码?
比如数字转字节码
而不能字节码转字节码?
数字 字节码a 字节码b 不行?
数字 字节码a
数字 字节码b 可以?
http://www.cocoachina.com/articles/48010
base64可以把数字转成8位字节码 存入数据库
base64.b16encode(x))
也可以是b16或b32编码
https://www.cnblogs.com/Kingfan1993/p/9795541.html
python转二进制
实例属性:就是已经实例化对象的属性
https://www.cnblogs.com/dogecheng/p/11441088.html
classmethod:只和本类自身的属性和方法发生交互
和 staticmethod:和类和其实例都不发生交互 但是关系上
很近
20210205
直接float(x) x是科学计数的字符串 转成普通数字
驻留:字符串相同居然是同一个对象 用is的时候
_repr
直接显示打印
20210203
电脑卡死 程序卡死 cpu和内存都占用不多的时候
很有可能就是磁盘占用100%导致的 会出现各种问题
这个时候最好不好再有其他操作
https://zhuanlan.zhihu.com/p/152340673
https://blog.csdn.net/fang_chuan/article/details/88889391
weakref:意思就是弱引用
弱引用
被引用的对象被删除了,引用的对象也会显示不存在
20210527
引用始终和等号相关联

弱引用不增加引用计数
20210131
dis 模块 字节码 的作用
比较两个函数的不同 查看细节
查看耗时多的语句
20210130
import bobo
@bobo.query('/')
def hello(person):
return 'Hello %s!' % person
模拟浏览器访问
20210128
https://blog.csdn.net/zhengqiqiqinqin/article/details/9816937
在windows下的命令控制台使用linux命令
https://www.runoob.com/python/python-func-eval.html
eval
https://www.runoob.com/python/att-string-rjust.html
rjust
。在 UTF-8 编码中,A(U+0041)的码位编码成
单个字节 \x41,而在 UTF-16LE 编码中编码成两个字节
\x41\x00。
码位和字节码
把码位转换成字节序列的过程是编码;把字节序列转换成码位的过程是解码
20210128
assert d1d2 and d2d3
判定是否相等 各个组成部分是否都全部对应相等
timeit
https://www.cnblogs.com/Uncle-Guang/p/8796507.html
20210127
append 和 popleft 都是原子操作,也就说是 deque 可以在多线程程序
中安全地当作先进先出的栈使用,而使用者不需要担心资源锁的问题。
20210125
字节码:0X…
机器码:01110101 等
Python randrange() 函数
https://www.runoob.com/python/func-number-randrange.html
给定范围的一个随机数
https://www.cnblogs.com/zhaoyingjie/p/9468935.html
bisect
找出需要插入的位置 只返回位置 而不插入
import dis
dis.dis('s[a] +=b')
查看语句运行过程的字节码
http://www.pythontutor.com/

python运行变量可视化
object = 1 + 2
print(id(object)) #4304947776
查看对象在内存中的引用地址
20210119
label = label.replace('\n', '')
去掉换行符 不需要转义
元组里面不只是两个元素可以有很多个元素
(a,b,c…)
for line in reader:
if len(line) != 4:
with open(os.path.join(FLAGS.output_dir, "error_data.log"), "a", encoding="utf-8") as f:
f.write("数据行(%d):%s\n" % (int(line['id']), str(line)))
continue
疑难杂症
程序不报错 但返回错误结果
说明存在 try,except 且把错误写到文件中去了
或者存在continue 且把错误写到文件中去了
20210115
https://so.csdn.net/so/search/blog?q=%E3%80%8APython%E9%AB%98%E7%BA%A7%E7%BC%96%E7%A8%8B%E3%80%8B%20%E2%80%94%E2%80%94%E9%80%9F%E6%9F%A5%E7%AC%94%E8%AE%B0&t=blog&p=1&s=0&tm=0&lv=-1&ft=0&l=&u=bf96163
全
三头六臂的小白 CSDN ID
python高级编程速查
20210114
https://mp.weixin.qq.com/s?src=11×tamp=1610595623&ver=2827&signature=4fLHYgouCmRS6jdAlHgkriXHjD6SBcM6cl950IlNmYaTyOUfKBrxLAf95dIXErKUz368FbnRG4zDlHKkE1eb6R47AtG7FeVXQbqFc63h4ilmQbGzSb*HoxCRQEsv7q5S&new=1
python基础技巧生成式
https://mp.weixin.qq.com/s?src=11×tamp=1610595623&ver=2827&signature=bMt38Da1dOBs1TUKyLMxiKVjYh3HNDH-L0NyownknUolT-Z-IVjSByKEhRzvItD5xxUZjkNk0H0qK890BnuL8zSkk271Uxp5ILLvGTfDEYPv5stvD8DpbEXRyvUqvk&new=1
python生成式的12个小功能
20210111
路径目录
windows 是正斜杠,linux 是反斜杠
TypeError: not all arguments converted during string formatting
print ‘strs= %s’ % (strs,)
strs= (1, 2, 3,4)
也可以用:
print ‘strs= %s,%s,%s,%s’ % sstr
strs= 1,2,3,4
前后参数位置个数要对应
20200109
https://blog.csdn.net/qq_36627886/article/details/80402959
编译器:编钟
解释器:
字节码
机器码
https://zhidao.baidu.com/question/10297593.html
转义字符编码\x
https://blog.csdn.net/weixin_44612441/article/details/105354195
connecting to console
https://www.jb51.net/article/66683.htm
批量去除剔除注释
if isinstance(value,type(tf.constant(0))):
判断是什么对象类型
https://www.cnblogs.com/yhleng/p/11940020.html
python指定限制cpu使用率,与内存占用率
https://blog.csdn.net/weixin_34320724/article/details/91709515
文本文件和二进制文件的区别
最终存储都是以二进制形式存储的 区别在于逻辑上的编码
二进制文件相当于存储的时候不用转换成二进制格式了
文本文件的可读性要好些,存储要花费转换时间(读写要编译码),而二进制文件可读性差,存储不存在转换时间(读写不要编解码,直接写值).这里的可读性是从软件使用者角度来说的,因为我们用通用的记事本工具就几乎可以浏览所有文本文件,所以说文本文件可读性好;而读写一个具体的二进制文件需要一个具体的文件解码器,所以说二进制文件可读性差,比如读BMP文件,必须用读图软件.
store = pd.HDFStore('store.h5')
#生成一个1亿行,5列的标准正态分布随机数表
df = pd.DataFrame(np.random.rand(100000000,5))
start1 = time.clock()
store['df'] = df
store.close()
print(f'HDF5存储用时{time.clock()-start1}秒')
start2 = time.clock()
df.to_csv('df.csv',index=False)
print(f'csv存储用时{time.clock()-start2}秒')
记录时间
20210108
迭代器的作用就能分块小批量地处理数据
在windows系统的命令行下面可以运行的时候
换到linux下不能运行 主要原因就是环境的变化
比如用的库的问题和路径的问题
如果是编码成utf-8的字符 那么len的长度是字节个数
而不是可视的字符个数
乱码因为编码和解码格式不一致导致的
![]()
字节码

补码的计算 快速看成对应的十进制 2的n-1次幂
20210108
try catch 就是这步执行失败了
后面的继续执行
20210105
self.wfile.write(json.dumps(p,ensure_ascii=False).encode('utf-8'))
json 序列化的数据只能是字典的格式 而且值不能是 数组
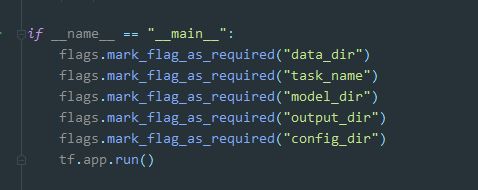
flags.mark_flag_as_required("data_dir")
flags.mark_flag_as_required("task_name")
flags.mark_flag_as_required("model_dir")
flags.mark_flag_as_required("output_dir")
flags.mark_flag_as_required("config_dir")
windows 命令行 as_required 可有可没有
OSError: [Errno 22] Invalid argument: 'D:\\code12temp\\rongxiang\\multilabelA\\engineering_process\\sc_server\\data"
data_dir="D:\code12temp\rongxiang\multilabelA\engineering_process\sc_server\data\\"
在windows命令行下面最后如果是文件夹必须用双正斜杠 data\\ 单反斜杠不行 \r 不用转义?
File "D:\myenv\py36tf12gpu\lib\site-packages\numpy\lib\npyio.py", line 416, in load
fid = stack.enter_context(open(os_fspath(file), "rb"))
OSError: [Errno 22] Invalid argument: "'D:\\code12temp\\rongxiang\\multilabelA\\engineering_process\\sc_server\\data\\'trainset.npy"
在命令行 如果路径用单引号是不行的 需要用双引号 不能双引号里面存着单引号
这种情况下是不能拼接在一起的 遇到有拼接的时候必须用双引号 其他普通情况直接用单引号
File "conv_run_classifier.py", line 298, in main
with open(FLAGS.config_dir, 'r') as load_f:
OSError: [Errno 22] Invalid argument: "'D:\\code12temp\\\\rongxiang\\multilabelA\\engineering_process\\sc_server\\config\\conv_config.json'"
在命令行用于json文件打开的时候,路径要用双引号 普通情况下用单引号
r'D:; Invalid argument
命令行或者linux下面路径前面不能加r
OSError: [Errno 22] Invalid argument: 'D:\\code12temp\rongxiang\\multilabelA\\engineering_process\\sc_server\\config\\conv_config.json'
在命令行直接在路径前加r是没有用的 最好是所有地方都是双斜杠
在这里 \r 就需要用两个反斜杠
json读取

ModuleNotFoundError: No module named 'engineering_process'
命令行下面导包可以理解为直接在linux上运行
二者导包方式不一样,在pycharm 里面需要指明模块的上层目录
如果在命令行里面 如果二者在同一个目录下 则直接导包 和linux环境一样操作
但是在pycharm 里面表示会报错
20210105
https://www.cnblogs.com/bigberg/p/6430095.html
读取json文件

json文件读取
def test():
try:
return print('abc')
except Exception as e:
print('sample data is generating....Fail ! {}'.format(e))
finally:
print('ccc')
test()
abc
ccc
函数里面有try finally
return执行完之后 还会执行finally
20210105

finally 下面编码cursor 报错事前没有声明 可以通过放在类里来解决
但是在linux 下面好像可以直接运行不会报错
return 放在try 最后 不要放在finally的close后面
20201228
ImportError: DLL load failed: 页面文件太小,无法完成操作。
显存的问题 先释放显存或内存
#one-hot 转换为多分类
def change_to_right(wrong_labels):
right_labels=[]
for x in wrong_labels:
for i in range(0,len(wrong_labels[0])):
if x[i]==1:
right_labels.append(i+1)
return right_labels
wrong_labels =np.array([[0,0,1,0], [0,0,1,0], [1,0,0,0],[0,1,0,0]])
right_labels =tf.convert_to_tensor(np.array(change_to_right(wrong_labels)))
https://blog.csdn.net/m0_46172703/article/details/109025472
python内置类型
https://blog.csdn.net/kyle1314608/article/details/111871823
类的标准范例
20201227
编码规范
变量第一次出现时候用全拼
后面再出现的时候 用简写比如前面三字母或者 首字母加数字
acct_mat 多个单词的时候
loss_train,acc_train
交换
estimator_config 写成 est_config
20201223
RuntimeError: The current Numpy installation ('D:\\myenv\\py36tf12\\lib\\site-packages\\numpy\\__init__.py') fails to pass a sanity check due to a bug in the windows runtime.
numpy 版本问题 改成 1.19.3
python 官网下载安装文件位置
python 所有版本参考
20201222
存储换算
https://cunchu.51240.com/
kb 到 mb 先除以1000 再乘以 0.97
kb 到 gb 先除以 10的7次方 再乘以 0.95
mb 到 gb 直接除以 10000 就好了
猴子补丁在运行时候修改类和模块,而不改变源代码
20201221
class Solution:
def minCostClimbingStairs(self, cost: List[int]) -> int:
n = len(cost)
dp = [0] * (n + 1)
for i in range(2, n + 1):
dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2])
return dp[n]
aa=Solution()
bb=aa.minCostClimbingStairs([1, 100, 1, 1, 1, 100, 1, 1, 100, 1])
print(bb)
代码注释
cost 是一个 list 里面的值是 int 最后函数返回的是int
ImportError: Failed to import pydot. You must install pydot and graphviz for pydotprint to work.
先把图注释掉 不画图
软件发布版本中rc的含义
RC=Release Candidate,含义是”发布候选版”,它不是最终的版本,而是最终版(RTM=Release To Manufacture)之前的最后一个版本。
广义上对测试有三个传统的称呼:alpha、beta、gamma,用来标识测试的阶段和范围。
alpha 是指内测,即现在说的CB,指开发团队内部测试的版本或者有限用户体验测试版本。此版本表示该软件在此阶段主要是以实现软件功能为主,通常只在软件开发者内部交流,一般而言,该版本软件的Bug较多,需要继续修改。
beta 是指公测,即针对所有用户公开的测试版本。该版本相对于α版已有了很大的改进,消除了严重的错误,但还是存在着一些缺陷,需要经过多次测试来进一步消除,此版本主要的修改对像是软件的UI
gamma是指对beta做过一些修改,成为正式发布的候选版本,现在叫做RC(Release Candidate)。和Beta版最大的差别在于Beta阶段会一直加入新的功能,但是到了RC版本,几乎就不会加入新的功能了,而主要着重于除错!
https://blog.csdn.net/iteye_12058/article/details/82675932
ERROR: Can not perform a ‘–user’ install. User site-packages are not visible in this virtualenv.
虚拟环境下本来就是 --user的安装方式
Consider using the --user option or check the permissions.
在命令行中添加 --user

(tf2_ner) D:\myenv\tf2_ner\Scripts>python3 -m pip install --upgrade pip
上面一行 运行之后没有反应
(tf2_ner) D:\myenv\tf2_ner\Scripts>python37 -m pip install --upgrade pip
要写正确 多个python版本 自己修改后的结果
pip 升级的写法
ERROR: Could not install packages due to an EnvironmentError: [WinError 5] 拒绝访问。: ‘d:\myenv\tf2_ner\lib\site-packages\~=mpy\.libs\libopenblas.NOIJJG62EMASZI6NYURL6JBKM4EVBGM7.gfortran-win_amd64.dll’
Consider using the --user option or check the permissions.
python37 -m pip install numpy==1.19.0
报–user 的错误 或者拒绝访问的错误的时候 就用 -m的形式安装
20201218
https://blog.csdn.net/sinat_29957455/article/details/97558787
tqdm
20201217
在一个模块内部
在前面的函数可以调用下面的函数?
def hs1():
hs2()
def hs2():
pass
20201211
try except 用于 当尝试做某个动作的时候 可能会出错
excepct 是捕获的try 里面语句的错误
X[embeding] = X[embeding].apply(lambda x: x.replace("[", “”))
现在的python 都可以深入到apply 里面去了
代码跑起来不出错 或者说import 错误
很可能是当前目录下import的文件名称和上层中有文件的名称相同造成的
但是却直接错误地import 当前目录的模块
python数组array.array
https://blog.csdn.net/kyle1314608/article/details/111028806
20201208
属性__getattribute__
属性访问拦截器
https://blog.csdn.net/kyle1314608/article/details/110875008
20201204
ModuleNotFoundError: No module named ‘sklearn.neighbors._base‘解决过程记录
No module named 'sklearn.neighbors._base’说明sklearn模块版本过低。
解决办法一:
升级一下sklearn,使用pip install --upgrade scikit-learn或conda update scikit-learn。
20201126
在命令行输入参数运行 如果输出之后,没有反应一下而过
(一闪而过)
则说明 python名称没有写对 比如之前写的 python3 实际Python名称为python37
在windows下面 运行的模块路径要写完整
https://www.cnblogs.com/xueweihan/p/4981704.html
pip 所有命令
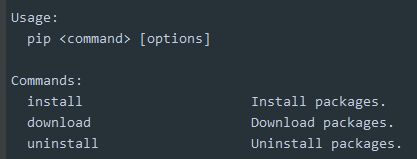
语法规则 command 表示 pip 后面直接跟命令
options 表示有很多命令可选
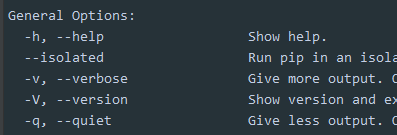
- h或 --h 用在 command之后 - 是单字母简写,–是字母全拼写
python 帮助命令
dir /?
pip --help
python获取命令行参数的方法
想用python处理一下文件,发现有argv这个用法,搜来学习一下。
如果想对python脚步传参数,那么就需要命令行参数的支持了,这样可以省的每次去改脚步了。
用法是:python xx.py xxx
#-*- coding:utf-8 -*-
from sys import argv
script,first = argv
print "the script is called:", script
print "the first variable is:", first
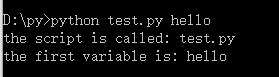
这里argv接收到的是一个列表变量
#-- coding:utf-8 --
from sys import argv
f = open(argv[1], ‘r’)
print f.read()
f.close()
比方说这里我读取文件名,开始写成了 open(argv, ‘r’),会提示类型错误,改成argv[1]就好了
当运行py程序的时候,我们一般使用python xx.py这种方式,而这里的xx.py就是一个参数,当然
我们还可以传递另外的参数,这里就相当于传递进了一个参数列表,而文件名则是第一个参数,也
就是argv[0],如果有更多的参数则按顺序排列
环境变量配置之后要重启之后才能生效
https://pypi.tuna.tsinghua.edu.cn/simple/tensorflow/
https://pypi.tuna.tsinghua.edu.cn/simple/torch/
pytorch,tensorflow 国内镜像
https://blog.csdn.net/kyle1314608/article/details/110163220
python -m 参数
直接启动是把run.py文件,所在的目录放到了sys.path属性中。
模块启动是把你输入命令的目录(也就是当前路径),放到了sys.path属性中***
第一种更好
20201125
https://blog.csdn.net/kyle1314608/article/details/110121840
解压缩
SyntaxError: EOL while scanning string literal的解决
路径最好一个斜杠的处理
![]()
20201124
不能解析路径或者不是一个文件夹
说明路径写的不对
ValueError: Wrong number of items passed 3, placement implies 1

等号左右的列数不相同
改成相同
20201125

mark directory as 为空时候 是因为directory 没有设置
20200729

类也可以作为字典的构成部分

调用类的某个属性时候,其属性里面可以调用类的其他属性

类本身
传参的时候也可以 加上if 语句
label_map = {label: i for i, label in enumerate(label_list)}
列表生成式 字典
20200722

run_ner_distill.py: error: the following arguments are required: --model_type
去掉required=True

r 指示 \t 为其本身的含义

继承后都有了
确定是包的问题的时候,列出所有的包,一个一个版本的试验,看是否还报错
20200714
没有抛错 很可能是自己把异常处理了
20200608


分支不想处理的情况下
continue 或者 输出默认值
20200604
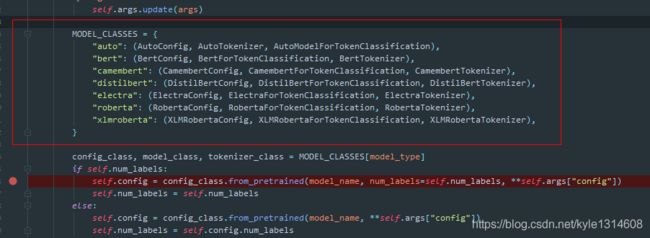
类的初始化函数中可以直接放内部对外部隐身的变量
ModuleNotFoundError: No module named ‘utils’”
自己本身文件夹里面有utils,但是不能导入 很有可能是因为系统中本来就是utils包
只要把自己当utils包改个名称就好了
20200529
python:如何将列表中的所有项相乘
from functools import reduce
lis=[1,2,3,4,5]
r=reduce(lambda x,y:x*y,lis)#对序列lis中元素逐项相乘lambda用法请自袭行度娘
print®
20200226

同一个类内部,某个函数需要输出多个变量
另一个变量要引用可以使用加方括号的办法,或者使用下面的方法 避免重复调用函数

在类内部 可以在任意位置 实例化,如果要公用某些部分就放到初始化
20200518
https://blog.csdn.net/u011085172/article/details/70911949
python 判断参数为Nonetype类型或空
if hostip is None:
print “no hostip,is nonetype”
elif hostip:
print “hostip is not null”
else:
print " hostip is null"
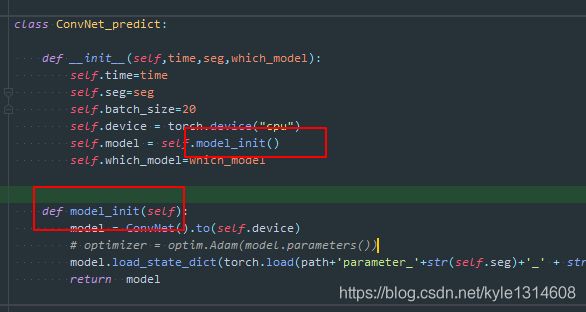
在类内部,调用可以先于定义
20200514
list(set(pbzd))
[set(pbzd)]
集合变列表 第一种 结果为一个纯净的列表
第二种 里面的元素是集合
pbzd.remove(0)
bbzd.pop(0)
列表的删除只能索引

列表转字符 不能在列表的两边加引号
python 导入excel的时候,要注意单元格左边的空格
20200513
full bleu test on references and candidate
predict_sentence =df.iloc[i,1]
ps=[ i for i in predict_sentence if i!=' ' ] #按字符打散
ps = ' '.join(ps) #按空格拼接成一个完整的字符

列表生成式的另一种书写方式 不满足条件的值不处理 if 和 for 交换位置
20200512
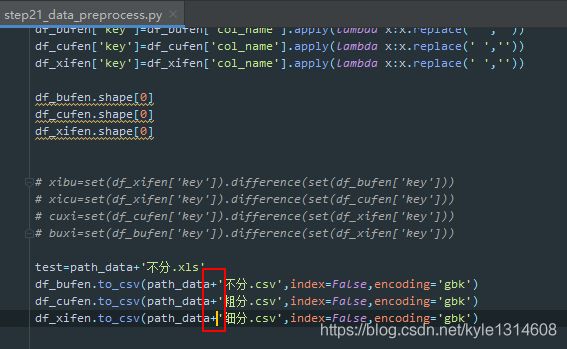
路径这里不是逗号 是完整的路径
PermissionError: [Errno 13] Permission denied: ‘D:/code12temp/pytorch/col_predict_medical/data/20200512/’
https://blog.csdn.net/appleyuchi/article/details/71513228?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
ValueError: No engine for filetype: ‘’
https://www.cnblogs.com/wanderingfish/p/9334736.html
差集
20200424
python 的
a.append(‘x’) 前面不需要等号 排空
dataframe append 需要等号
a=a.append(’‘x’)
容易报错的地方
1.数据处理中被除数可能为零
2.数据处理中,for 循环的时候,索引可能不存在
20200423
python 路径不能含有分号和空格
https://www.cnblogs.com/jszfy/p/11143048.html
python 如何获取当前系统的时间
如何判定变量是Nonetype类型
if text is None:
print('test is ’ + None)
else:
print('test is not ’ + None)
20200410

excel 中 看似相同 其实有可能含有空格 导入python之后一定要注意清理空格
这就是为什么 从数据库中读取数据出来有些字段会少了
就可能是因为空格而没有读取成功
20202409
路径中一个点与两个点的区别
转载djjj123456789 最后发布于2018-07-08 11:11:49 阅读数 5499 收藏
发布于2018-07-08 11:11:49
在导入js或者样式表的时候,如果我们放在文件夹下面,有时会涉及路径问题找不到我们的引入,曾经我也遇到过相应的问题。解决方法就是在路径前面加点。那么在这个路径中一个点和两个点到底有什么区别呢?
1、一个点:表示当前目录。即类似使用:./juqery.min.js。
2、两个点:表示当前目录的上级目录。类似:
20200408
https://www.cnblogs.com/xifengxixia/p/10918117.html
向上取整
对各种数据情况进行测试的时候
人为把数据只保留测试的情况 其他所有不符合的数据全部删除
简化问题,提高效率
20200408
在当前层考虑问题的时候如果情况太多,太复杂
是否可以考虑再往上抽象一层 也就是当你发现某些操作
是被很多种情况进行共有的时候 那就要抽象了 把这些情况
单独抽象出来
编程技巧效率提升
要从多个地方取数据,最好是先统一算出每个地方要取多少条
最后再统一取出
而不要去遍历,先取一遍 然后记录状态 再去取一遍 这样保存的
状态太多,太复杂
20200319
一个函数内部多个分支选择return的时候,可以用一个变量
在函数最后return
20200313
模块名称里面不能加点号,会误认为为引用方法
20200312
list两种方法的区别
a=[1,2]
b=[3,4]
c=a.append(b) 直接整个列表追加
c=[[1,2],[3,4]]
a.extend([1,2,3,4]) 去掉中间列表,全部元素放在一个列表里面
20200312
日志打印和输出
def log():
#创建logger,如果参数为空则返回root logger
logger = logging.getLogger(“nick”)
logger.setLevel(logging.DEBUG) #设置logger日志等级
#这里进行判断,如果logger.handlers列表为空,则添加,否则,直接去写日志
if not logger.handlers:
#创建handler
fh = logging.FileHandler(“test.log”,encoding=“utf-8”)
ch = logging.StreamHandler()
#设置输出日志格式
formatter = logging.Formatter(
fmt="%(asctime)s %(name)s %(filename)s %(message)s",
datefmt="%Y/%m/%d %X"
)
#为handler指定输出格式
fh.setFormatter(formatter)
ch.setFormatter(formatter)
#为logger添加的日志处理器
logger.addHandler(fh)
logger.addHandler(ch)
return logger #直接返回logger
logger = log()
logger.info(‘交叉验证得分:{}’.format(avg_score))
https://www.cnblogs.com/Nicholas0707/p/9021672.html
20200311
def data_transform_merge():
listfile = os.listdir(path)
count=0
for i_file in listfile:
if ('补充数据' in i_file) & ('csv' in i_file) :
print(i_file)
df_=pd.read_csv(path+i_file)
min_max_scaler = preprocessing.MinMaxScaler()
df_minmax = min_max_scaler.fit_transform(df_)
df_minmax = pd.DataFrame(df_minmax)
df_minmax.columns =df_.columns
df_minmax=df_minmax.T
df_minmax=df_minmax.iloc[1:,:]
df_minmax.columns=range(1,(seg+1))
df_minmax.insert(loc=0,column='0',value=df_.iloc[0,0])
if count==0:
df_sample=df_minmax
else:
df_sample=pd.concat([df_sample,df_minmax],axis=0,ignore_index=True)
count+=1
df_sample.to_csv(path + '归一化补充数据合并'+str(time_)+'.csv', index=False)
df_sample
只要不出函数空间,在里面的变量都可以随处引用的
如果不是在一个函数空间内部,那么if,for 等超出了
其范围都不能引用了
函数要在函数外引用,必须通过returen 返回
20200309
引用一个变量之前,必须先定义和赋值

20200302
https://www.runoob.com/python/att-string-endswith.html
要不 if 或者 for 里面的变量给弄出来唯一的办法是在这个循环的外面
加上变量保存进去
20200228
jupyter 快捷键

20200227
AttributeError : ‘GridSearchCV’ object has no attribute ‘grid_scores_’
之所以出现以上问题,原因在于grid_scores_在sklearn0.20版本中已被删除,取而代之的是cv_results_。
A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
用reshape 或者reval
y_train=y_train.reshape(-1)
y_train=np.reval(y_train)
https://blog.csdn.net/dta0502/article/details/82966790
series 转 dataframe
ValueError: Expected 2D array, got 1D array instead:
serise 改成 dataframe
决No module named ‘sklearn.cross_validation’
sklearn中已经废弃cross_validation,将其中的内容整合到model_selection中
将sklearn.cross_validation 替换为 sklearn.model_selection
20210527
协议可理解为一套的方法和属性? 实现了这一套协议就认为是某种类型
20200219
https://www.runoob.com/python/python-func-range.html
range的用法
20200119 执行一个.py文件只能在命令行模式中执行。(这是结论不是原因。)
Python交互模式中,代码是输入一行,执行一行,而命令行模式下直接运行.py文件是一次性执行该文件内的所有代码。即使说,交互模式方便攻城狮们调试Python代码。
20100110 各种包名,路径等根据其具体的用途命名不要和官方名称重复了
20200709 1.要改变for循环的起始位置,比如回退之后重新定位
那通过韩式递归来实现
2.函数内部包函数 可以让所有函数使用最外层的同一套变量,所有更改操作都作用在这一套唯一的变量身上,可以改成类?
3.当递归牵扯到的变量超过5个,当if 分支超过3个判断条件时候,
当嵌套if 超过3层的时候 就只能通过一步一步最简单的调试来
保证程序的正确了,无法通过空间想象来完成
4.测试的时候,最好把数据和各种牵扯到软件复杂度增加的变量都设置到
最小的水平,同时最好保证保留能测出所有的问题
#获取环境变量
trainers = int(os.getenv(“PADDLE_TRAINERS”, “1”))
对于列表如果追加的元素也是列表的话 如果循环的中间结果一直保存在内存中的话 直到最后一次才保存那么 中间结果中的追加列表的元素全部都会变成最后一次的结果
列表 [:-1] 是包含倒数第二个元素的列表
[-1:] 包含最后一个元素的列表
[len(a)-1:len(a)] 最后一个元素
countinue 不能放到函数里作为嵌套放到for 循环里面
直接放在for循环里面就可以了
20191021 函数调用函数 最好写到一个类里面
某个函数的变量被其他多函数调用等
python 字符拼接
路径里面的拼接 os.path.join

格式化拼接
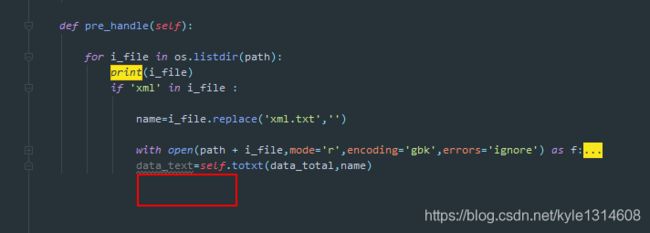
这里不能加return 如果加return 那么for一次之后就会退出循环
#如果output_all_encoded_layers == True:则将每一层的结果添加到all_encoder_layers中
if output_all_encoded_layers:
if 的表达式 就相当于是True 的表达
if not a:相当 if aFalse
函数return 之后就是回到上一个调用函数了

init的地方可以写成函数的形式实现


上面一种只答应一个空行
下面打印两个
https://www.cnblogs.com/notzy/p/9312049.html
orderdict 是指的加入字典的元素对保持加入时候的次序
20191217 编程规范的问题
设置环境变量 或者命令

参数1=1;参数2=2
命令行中 linux 用 export 参数1=1
windows 用 set 参数1=1

有默认值的参数和没有默认值的参数要在一起
对象方法:实例化对象之后 才有用的方法
这里结束