文本聚类学习过程简述
文本处理
1.去空格,换行符,去停用词
def delstopwordslist(classsstr):
stopwords = [line.strip() for line in open('stop.txt', encoding='UTF-8').readlines()]
outstr = ''
classsstr=classsstr.split(' ')
for word in classsstr:
if word not in stopwords:
outstr += word
outstr += ' '
return outstr
2.jieba分词
for i in filenames:
Single_text_content = ''
with open(path+'/'+i,"r",encoding='UTF-8') as f:
for centence in f.readlines():
centence = centence.strip().replace(' ', '').replace(' ', '') #去除每一句中的空格等
Single_text_content += centence
text = ' '.join(jieba.cut(Single_text_content)) #分词
Fulltext_cut_content.append(delstopwordslist(text)) #去停用词
# jieba.cut会返回一个
# '空格'.join(generator对象) 将generator对象以空格连接生成一个新的字串
注意:在文本处理时,需要先分词,再去停用词。
词频统计
1.Counter()方法
import collections
sorted_words_dict = collections.Counter(seg_list)
2.自定义函数
def count_word(classstr):
result={}
for word in classstr.split():
if word not in result:
result[word]=0
result[word]+=1
return result
词频排序
1.python自带sorted函数
result=sorted(字典名.items(),key=lambda k:k[1],reverse=True)
2.collections库Counter方法
import collectionssorted_words_dict = collections.Counter(字典名) #统计词频
result = sorted_words_dict.most_common(100)
#前100出现频率最高的元素以及他们的次数,返回类型是列表里面嵌套元组
3.pythom堆排序模块heapq
import heapq
result=heapq.nlargest(100,字典名.items(),key=lambda k:k[1])
其排序速度都差不多,但推荐使用和掌握Counter方法
词频数据 矩阵化
1.统计每个大类(假设分为3类)的文本的词+词频(前20),将3类文本词频求并集(获得其词袋模型)(假设求并集后长度为55)(求并集方法:set(字典X).union(字典Y)),之后存入一个1*55列表1中。
2.统计每篇文本的词+词频(比如前60),并为每篇文本构建一个1*60列表2,将每篇文本中提取的词频前60的词存入。
3.得到每篇文本中的与每个大类匹配的1*55列表3
可以这样想,如果一个属于体育类的文本特征构建的列表,它与全文本特征中体育大类特征匹配就会高,则所得到的列表3在体育类的20个列中值就较其他而言更大
例如:

或者(仅求取词的权重方式不同):
![]()
K-Means聚类
详细讲解见 机器学习sklearn19.0聚类算法——Kmeans算法
假设输入T个样本矩阵,将其分为n类,其步骤为:
1.选择初始化n个类别中心A1,A2…An;
2.计算每个样本矩阵与每个类别中心的距离,将样本矩阵标记为距离最近的类别中心的类别
距离计算方式:闵科夫斯距离 标准化欧式距离 夹角余弦相似度 KL距离 杰卡德相关系数 Pearson相关系数
3.更新n个类别中心点为 被标记为该类别样本的平均值
4.重复2,3步骤,直到达到某些终止条件
过程如图所示:

简单来说kmeans会按我们设置的类别,将所有样本(矩阵)相似度高的归为一类,最后返回标记的矩阵
例如:
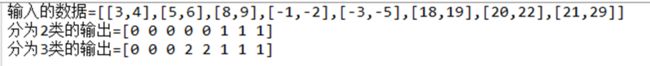
或者
![]()
具体的K-Means库的各种方法,参数大家就自己了解咯
但是,这样数据得到的效果总是不太理想,因为我们仅依靠词频来获取每篇文章/每类文章的特征的方式,得到的结果是不太准确的
比如我们通过词频获取一篇体育类文本的特征时:

这其中会有很多没有区别意义的词和一些单字
如何获取更为具有特征意义的词,便成为了关键
TF-IDF 词频-逆文本频率
TF即词频,反应了一个词在该文本中出现的频率
IDF即逆文本频率,反应了一个词在所有文本中出现的频率,如果一个词很多的文本中出现,那么它的IDF值就会偏低
将TF x IDF,即得到一个词真正的重要性,这排除了许多没有特征性却频率高的词
统计每篇文本的TF-IDF高的词,和每个大类中TF-IDF高的词(具体使用方式大家就自己了解咯)
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
vectorizer=CountVectorizer() #生成该类会将文本中的词语转化为词频矩阵
tranceformer=TfidfTransformer() #该类能计算每个词语的T-idf值
tfidf=tranceformer.fit_transform(vectorizer.fit_transform(文本list))
word=vectorizer.get_feature_names() #获取所有词语的列表
#print(type(word))=list
weight=tfidf.toarray() #获取词语的权重列表
通过TF-IDF得到的一篇体育类文本的特征词如下:

之后,通过KMeans聚类,就能得到极好的效果
==============================================================
以上内容仅是自我梳理,可能会存在一些理解性错误,大家可以在评论区指出,欢迎探讨相关问题。
至于相关代码由于涉及对多个文件夹访问,并且变量太多,自我感觉对别人难于理解,这里就不公开了。不过理解过程之后还是很好完成的。
用于聚类实验的文本:
请在该网站进行下载 THUCTC: 一个高效的中文文本分类工具