R数据分析:tableone包的详细使用介绍
tableone是帮助我们快速生成文章中table1表格的一个包,通常来说一篇SCI文章的第一个表都会给出样本的基线情况。而tableone就是可以帮我们快速地汇总描述所有样本的基线变量的一个包。
今天就给大家写写tableone,其实还有一个包叫做table1,功能差不多,以后给大家写。
实例解析
还是写一个例子帮助大家理解,用到的数据是R自带的pbc数据集。这个数据集是梅奥诊所收治的肝硬化病人的数据,共424个。
This data is from the Mayo Clinic trial in primary biliary cirrhosis (PBC) of the liver conducted between 1974 and 1984. A total of 424 PBC patients, referred to Mayo Clinic during that ten-year interval, met eligibility criteria for the randomized placebo controlled trial of the drug D-penicillamine。
这个数据集大概长这样:

现在我想要看看整个数据集的描述性分析,那么我就可以:
CreateTableOne(data = pbc)输出如下:
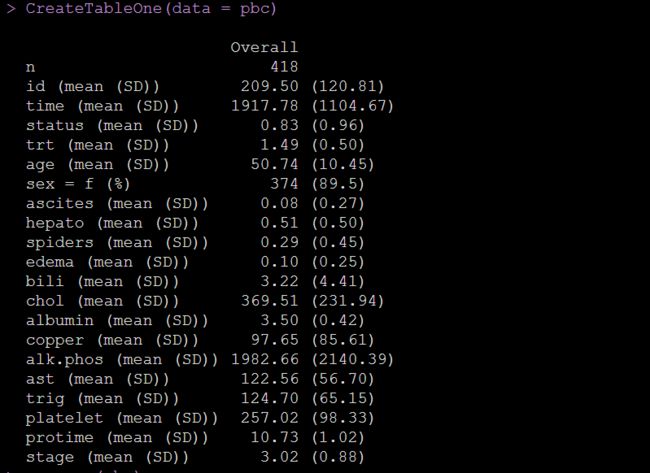
看到没,所有的数值变量都给你以均值标准差的形式描述好了,因子变量频数百分比也描述好了,不用你再用什么SPSS一个一个来描述统计了。
等等,问题还是有滴,比如:
- 数据库中其实有很多变量应该是因子类型的,但是都给整成整数型了
- 连ID都给描述了,这玩意我不需要
我们来调整一下,比如我论文中只需要描述如下的变量:
myVars <- c("time", "status", "trt", "age", "sex", "ascites", "hepato",
"spiders", "edema", "bili", "chol", "albumin", "copper", "alk.phos",
"ast", "trig", "platelet", "protime", "stage")并且,其中有些变量是因子类型:
catVars <- c("status", "trt", "ascites", "hepato",
"spiders", "edema", "stage")好了,规定好了以后我们重新进行描述:
tab2 <- CreateTableOne(vars = myVars, data = pbc, factorVars = catVars)
看到没,此时所有我们规定的因子类型的变量都是用频数百分比进行表述的了。但是要注意的是,这个描述中所有的双水平因子都是只描述第二个水平,比如性别sex图中就只给出了女性f的水平,3水平及以上的因子所有水平都会描述。
当然啦,这个默认设定也是可以改的,比如我就是想要输出全水平,我就可以在打印的时候加上showAllLevels参数。
print(tab2, showAllLevels = TRUE, formatOptions = list(big.mark = ","))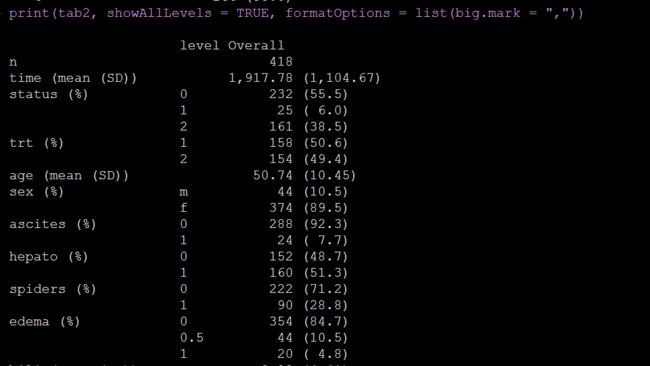
现在二水平因子的所有水平都在图中了。男女占比都有啦。
超级详细的描述
有可能你还想要看看每个你感兴趣的变量的分布什么的,缺失值什么的,tableone也可以做得到哦,直接给CreateTableOne对象进行summary,简单粗暴。
summary(tab2)

看看看,这个时候对于数值变量,缺失值数量,占比,均值标准差,四分位间距,偏度峰度全部给你;对于因子变量,缺失值数量,占比,水平数,频率和累计频率都在,要啥有啥。太好了。
分组描述加比较
tableone另外一个不可错过的功能就是分组描述并做统计检验,有可能你把你的研究对象分了两组,写文章的时候首先你要分组对比两组的基线资料撒,就用它啦,全部帮你搞定,包括所有基线资料的组间比较:
tab3 <- CreateTableOne(vars = myVars, strata = "trt" , data = pbc, factorVars = catVars)
print(tab3, formatOptions = list(big.mark = ","))看输出:
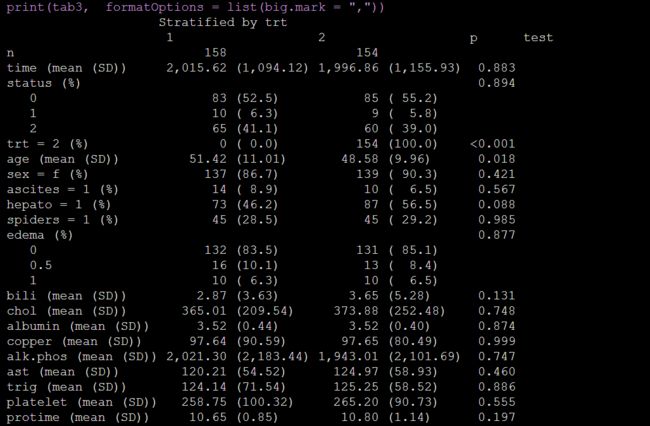
简直美滋滋。
描述数据的导出
其实你大可以直接在你的CONSOLE中进行结果的复制粘贴,但是我还要给你写写如何导出描述表格,还不快快关注我。
运行下面的代码后你就可以看到描述的结果全在你的工作目录中了。
tab3Mat <- print(tab3, quote = FALSE, noSpaces = TRUE, printToggle = FALSE)
write.csv(tab3Mat, file = "myTable.csv")
看到没,你再稍微做一调整立马就可以往你的论文中放了。
小结
今天给大家写了tableone包的基本用法,感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请关注后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞转发。
也欢迎大家的意见和建议。
如果你是一个大学本科生或研究生,如果你正在因为你的统计作业、数据分析、论文、报告、考试等发愁,如果你在使用SPSS,R,Python,Mplus, Excel中遇到任何问题,都可以联系我。因为我可以给您提供好的,详细和耐心的数据分析服务。
如果你对Z检验,t检验,方差分析,多元方差分析,回归,卡方检验,相关,多水平模型,结构方程模型,中介调节,量表信效度等等统计技巧有任何问题,请私信我,获取详细和耐心的指导。
If you are a student and you are worried about you statistical #Assignments, #Data #Analysis, #Thesis, #reports, #composing, #Quizzes, Exams.. And if you are facing problem in #SPSS, #R-Programming, #Excel, Mplus, then contact me. Because I could provide you the best services for your Data Analysis.
Are you confused with statistical Techniques like z-test, t-test, ANOVA, MANOVA, Regression, Logistic Regression, Chi-Square, Correlation, Association, SEM, multilevel model, mediation and moderation etc. for your Data Analysis...??
Then Contact Me. I will solve your Problem...
加油吧,打工人!
猜你喜欢:
R数据分析:如何在R中使用mutate
R数据分析:再写stargazer包,如何输出漂亮的表格
R数据分析:用R语言做meta分析
R数据分析:何为Tidy data,它又有什么好处
R数据分析:stargazer给你一个漂亮的可以直接发表的结果表格
R数据分析:如何用R语言做meta分析,写给小白
R文本挖掘:文本主题分析topic analysis