pytorch的权重/梯度值查看,梯度清零model.zero_grad()
参考:https://www.jianshu.com/p/5460b7fa3ec4、https://blog.csdn.net/weixin_41990278/article/details/111414592、
https://www.cnblogs.com/picassooo/p/14153787.html、
https://editor.csdn.net/md/?articleId=117135289、
https://blog.csdn.net/weixin_36411839/article/details/103834679
网络参数保存加载、梯度/权重查看
网络参数保存和加载:
>只加载名称相同的部分
>model.load_state_dict(torch.load(weight_path), strict=False)
> torch.save(myNet.state_dict(),'pakage_pkl/net_parameter.pkl') # 网络参数保存
> myNet.load_state_dict(torch.load('pakage_pkl/net_parameter.pkl'))
> torch.save(myNet,'pakage_pkl/net.pkl') # 先保存网络后,才能加载
> myNet1 = torch.load('pakage_pkl/net.pkl')
参数查看
有网络框架后加载的参数查看
model.parameters(), model.named_parameters()
for parameters in net.parameters():
print(parameters)
for name,parameters in net.named_parameters():
print(name,':',parameters)
print(name, ':', parameters.size())
仅仅加载的参数查看,无需建立网络框架
model_dict.items()
import torch
model_dict = torch.load('Final_LPRNet_model.pth',map_location = 'cpu')
for name, para in model_dict.items():
print(name,':',para.size())
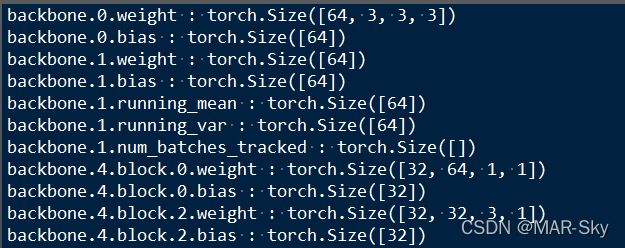
常用几个命令功能
optimizer.zero_grad() # 网络梯度清零
loss.backward() # 误差的反向传播
optimizer.step() # 根据反向传播的误差更新参数
梯度置零两种方式
model.zero_grad()
optimizer.zero_grad()
两种的区别
参考:https://www.jianshu.com/p/c59b75f1064c
1、当使用optimizer = optim.Optimizer(net.parameters())设置优化器时,此时优化器中的param_groups等于模型中的parameters(),此时,二者是等效的,从二者的源码中也可以看出来。
2、当多个模型使用同一个优化器时,二者是不同的,此时需要根据实际情况选择梯度的清除方式。
3、当一个模型使用多个优化器时,二者是不同的,此时需要根据实际情况选择梯度的清除方式。
一个实例
功能:拟合一个有噪声的直线
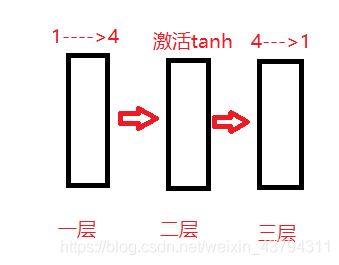
结构图如下,
import torch
w = 2
b = 1
torch.manual_seed(1)
noise = torch.rand(100, 1)
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
# 因为输入层格式要为(-1, 1),所以这里将(100)的格式转成(100, 1)
y = w*x + b + noise
# 拟合分布在y=2x+1上并且带有噪声的散点
model = torch.nn.Sequential(
torch.nn.Linear(1, 4),
torch.nn.Tanh(),
torch.nn.Linear(4, 1),
)
# 自定义的网络,带有2个全连接层和一个tanh层
loss_fun = torch.nn.MSELoss()
# 定义损失函数为均方差
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 使用adam作为优化器更新网络模型的权重,学习率为0.01
for _ in range(2):
# ax = plt.axes()
output = model(x)
# 数据向后传播(经过网络层的一次计算)
loss = loss_fun(output, y)
# 计算损失值
model.zero_grad()
loss.backward()
# 向后传播,计算当前梯度,如果这步不执行,那么优化器更新时则会找不到梯度
optimizer.step()
print(list(model.children())[0].weight.grad)
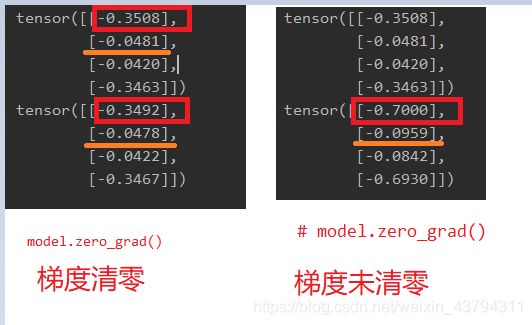
从数值来看,两次的梯度值,第二次不清零的梯度值是清零梯度值两次之和,若梯度值一直不清零,那么梯度值是一直累加,在到达目标点之前一直增大,这样不可能逼近目标点,因为在目标点的梯度最大,会出现震荡。
查看梯度值
没有各层的名称时
上例中没有定义每层的名字,因为model.children()返回一个生成器,需要使用list后查看,而且总数 表示的是定义的层数,这里的最多是3层,查看梯度
list(model.children())[0].weight.grad
有各层名称时
网络结构图如下图
class Simple(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, 3, 1, padding=1, bias=False)
self.conv2 = nn.Conv2d(16, 32, 3, 1, padding=1, bias=False)
self.linear = nn.Linear(32*10*10, 20, bias=False)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.linear(x.view(x.size(0), -1))
return x
model = Simple()
查看梯度值,
print(model.conv1.weight.grad)