深度学习论文: RepGhost: A Hardware-Efficient Ghost Module via Re-parameterization及其PyTorch实现
深度学习论文: RepGhost: A Hardware-Efficient Ghost Module via Re-parameterization及其PyTorch实现
RepGhost: A Hardware-Efficient Ghost Module via Re-parameterization
PDF: https://arxiv.org/pdf/2211.06088.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
RepGhostNet通过结构重参数机制实现特征复用,赋能GhostNet达成硬件友好方案。ImageNet与COCO基线任务验证了所提方案的有效性与高效性。
2 RepGhostNet
2-1 Feature Reuse via Re-parameterization
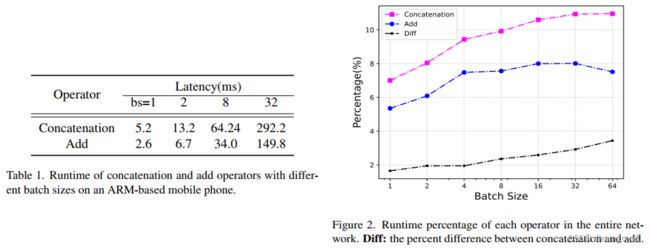
GhostNet通过引入cheap操作进行特征复用,但引入了对硬件不友好的Concat。Concat特征复用虽然是无参、无FLOPs,但其计算耗时却不能忽视,如下图,随着batch_size增大,Concat与Add的运行延时差距越来越大。
Re-parameterization vs. Concatenation
Concatenation可以表示为
![]()
Re-parameterization可以表示为
![]()
因此,激发我们是否可以考虑用Re-parameterization代替Concatenation操作。
2-2 RepGhost Module
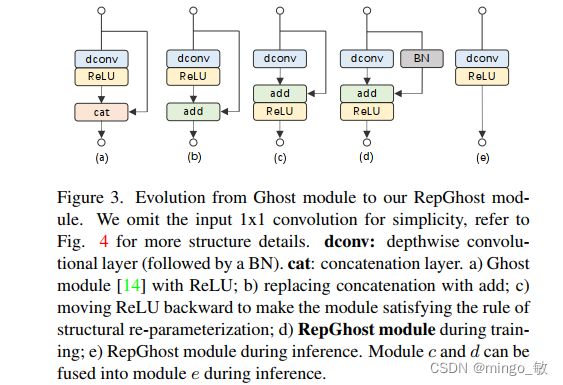
上图给出了Ghost到RepGhost的进化过程,包含以下三点:
- Concat替换为Add以降低耗时;
- ReLU迁移以符合重参数折叠机制;
- shortcut分支引入BN进一步提升非线性。
PyTorch代码:
class RepGhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, dw_size=3, stride=1, act_type=dict(type='ReLU', inplace=True), use_act=True,
deploy=False, reparam_bn=True, reparam_identity=False):
super(RepGhostModule, self).__init__()
init_channels = oup
new_channels = oup
self.deploy = deploy
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False),
nn.BatchNorm2d(init_channels),
build_activation_layer(act_type) if use_act else nn.Sequential(),
)
fusion_conv = []
fusion_bn = []
if not deploy and reparam_bn:
fusion_conv.append(nn.Identity())
fusion_bn.append(nn.BatchNorm2d(init_channels))
if not deploy and reparam_identity:
fusion_conv.append(nn.Identity())
fusion_bn.append(nn.Identity())
self.fusion_conv = nn.Sequential(*fusion_conv)
self.fusion_bn = nn.Sequential(*fusion_bn)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size // 2, groups=init_channels, bias=self.deploy),
nn.BatchNorm2d(new_channels) if not self.deploy else nn.Sequential(),
)
if self.deploy:
self.cheap_operation = self.cheap_operation[0]
self.relu = build_activation_layer(act_type) if use_act else nn.Sequential()
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
for conv, bn in zip(self.fusion_conv, self.fusion_bn):
x2 = x2 + bn(conv(x1))
return self.relu(x2)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.cheap_operation[0], self.cheap_operation[1])
for conv, bn in zip(self.fusion_conv, self.fusion_bn):
kernel, bias = self._fuse_bn_tensor(conv, bn, kernel3x3.shape[0], kernel3x3.device)
kernel3x3 += self._pad_1x1_to_3x3_tensor(kernel)
bias3x3 += bias
return kernel3x3, bias3x3
@staticmethod
def _pad_1x1_to_3x3_tensor(kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
@staticmethod
def _fuse_bn_tensor(conv, bn, in_channels=None, device=None):
in_channels = in_channels if in_channels else bn.running_mean.shape[0]
device = device if device else bn.weight.device
if isinstance(conv, nn.Conv2d):
kernel = conv.weight
assert conv.bias is None
else:
assert isinstance(conv, nn.Identity)
kernel_value = np.zeros((in_channels, 1, 1, 1), dtype=np.float32)
for i in range(in_channels):
kernel_value[i, 0, 0, 0] = 1
kernel = torch.from_numpy(kernel_value).to(device)
if isinstance(bn, nn.BatchNorm2d):
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
assert isinstance(bn, nn.Identity)
return kernel, torch.zeros(in_channels).to(kernel.device)
def switch_to_deploy(self):
if len(self.fusion_conv) == 0 and len(self.fusion_bn) == 0:
return
kernel, bias = self.get_equivalent_kernel_bias()
self.cheap_operation = nn.Conv2d(in_channels=self.cheap_operation[0].in_channels,
out_channels=self.cheap_operation[0].out_channels,
kernel_size=self.cheap_operation[0].kernel_size,
padding=self.cheap_operation[0].padding,
dilation=self.cheap_operation[0].dilation,
groups=self.cheap_operation[0].groups,
bias=True)
self.cheap_operation.weight.data = kernel
self.cheap_operation.bias.data = bias
self.__delattr__('fusion_conv')
self.__delattr__('fusion_bn')
self.fusion_conv = []
self.fusion_bn = []
self.deploy = True
2-3 RepGhost Bottleneck
Bottleneck改进主要体现在通道数,这是因为Concat到Add的过渡会导致通道数发生变换。作者主要是针对中间通道数进行调整,而输入与输出通道数相同。
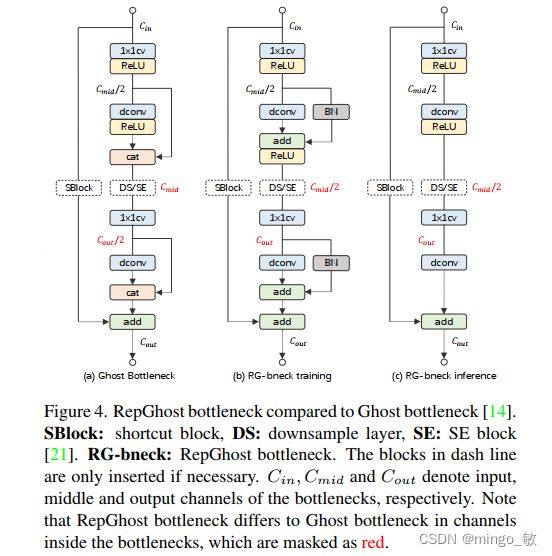
2-4 RepGhostNet
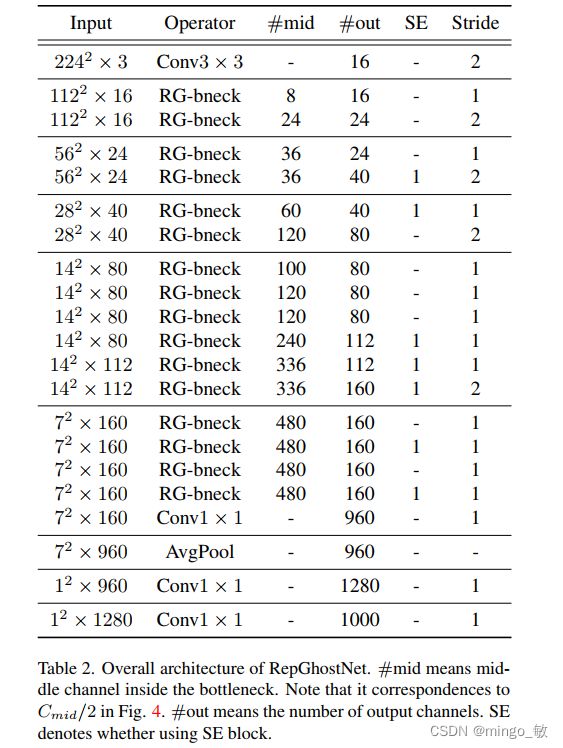
提出的RepGhostNet结构
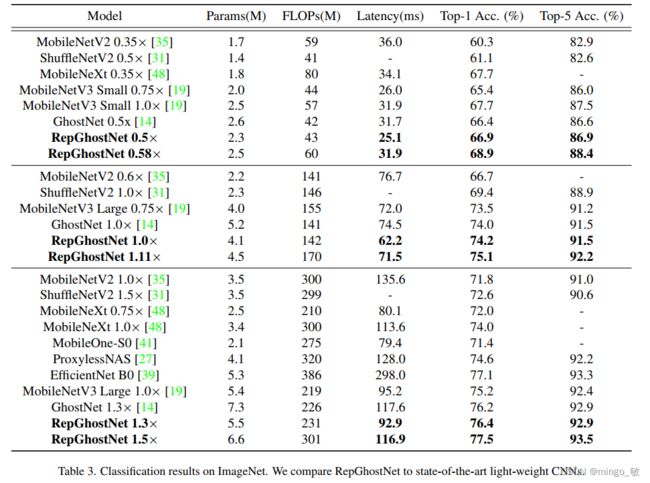
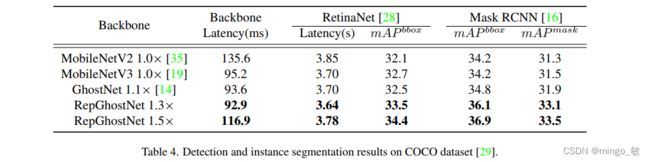
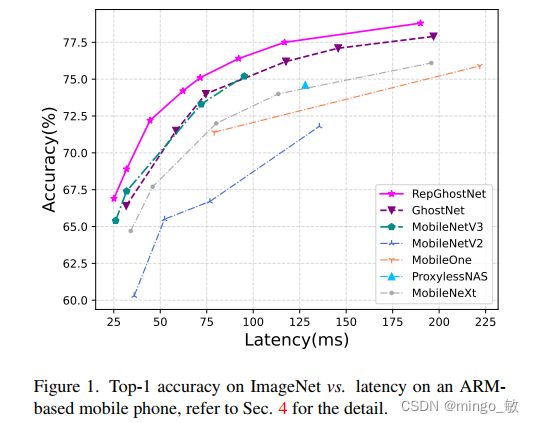
3 Experiments
ImageNet与COCO数据集上的性能如下