百度飞桨适配登临 GPU+ 系列芯片
点击左上方蓝字关注我们

2021 WAVE SUMMIT 是由深度学习技术及应用国家工程实验室及百度联合主办一场极客盛会 。会间,百度飞桨(PaddlePaddle)发布多项重大更新。其中,登临平台集成代码已经合并,随飞桨开源框架v2.1正式开源。
百度与登临的合作,为飞速增长的 AI 应用市场提供更灵活的硬件平台选择,以及更低 TCO(Total Cost of Ownership,即总拥有成本)的人工智能数据中心方案,可共同推动人工智能应用在更广泛的行业及客户群中落地。
经历五年的迭代和市场培育,百度飞桨已凝聚320万开发者,同时在多个行业中落地并形成活跃成熟的开源社区生态。飞桨开源框架v2.1发布,为开发者带来更完善的本地化深度学习平台。此次联合登临GPU+,能够为国内客户提供完整的高性能AI 应用基础设施。
登临科技GPU+是一系列高性能、高能效比的 AI 通用芯片加速卡,可安装到从边缘计算到云端的各种计算设备中。登临科技创新GPU+(软件定义的片内异构架构体系)通过对高效的Tensor引擎和可编程的GPGPU引擎的有机配合,从而完美地解决通用性和高效率等云端人工智能的关键问题。
Goldwasser作为登临科技GPU+系列首款产品,通过片内异构,解决了传统的系统级异构计算调度和数据交换的开销大及数据的连贯相干性的难题。在整个系统的计算密度极高的基础上,通过软件定义,使各种应用场景(即针对不同神经网络)都能达到硬件性能和能效最大化。同时,硬件支持CUDA加速解决了软件生态的问题,并大大降低了客户的迁移成本。
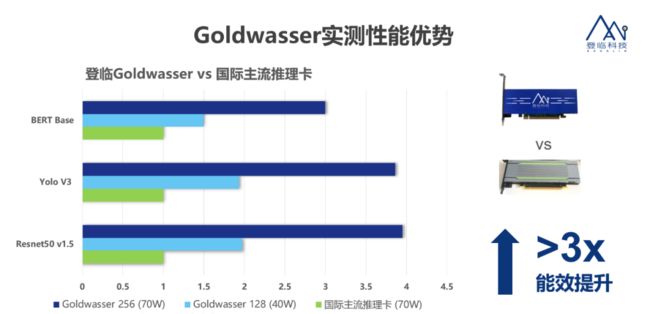
在实测过程中,登临的 Goldwasser 在 40W TDP 时输出了 128TOPS 算力,和国际主流产品对比其功耗更低,性能更高。在同样的工艺上,Goldwasser 可以以更小的芯片面积,在同样功耗下,在不同神经网络上提升 3-10 倍计算效率,并同时可减低芯片性能对外存吞吐的依赖。
Goldwasser系列产品可同时支持推理和训练,包括:边缘计算产品 Goldwasser UL,功率 25-35W,INT8 算力 32-64TOPS;半高半长的服务器计算卡 Goldwasser L,功耗 40-70W,提供 128-256TOPS 算力;另有一种全高全长的 Goldwasser XL,输出 512TOPS 算力。

登临Goldwasser可以广泛应用于视频分析、视频审核、语言识别、内容推荐、人机交互、信息搜索、欺诈检测防范、自然语言处理、无人驾驶以及机器人等重要的 AI 应用场景中,满足高性能计算加速需求。

Paddle-dlNNE通过飞桨原生推理库Paddle Inference集成登临的 AI 网络引擎 (dlNNE) , 支持在任何已安装登临 GPU+ 芯片产品的设备上进行推理部署。一般来说当深度学习模型加载后,神经网络可以表示为由权重变量和运算节点组成的计算图。Paddle-dlNNE 对整个图进行扫描,发现图中可以使用 dlNNE 优化的子图,并使用 dlNNE 节点替换它们。
在模型的推理期间,如果遇到 dlNNE 节点,飞桨会调用 dlNNE 库对该节点进行优化,其他的节点调用 Paddle Inference原生实现。dlNNE 在推理期间能够进行OP的横向和纵向融合,过滤掉冗余的OP,并对登临硬件环境下的特定的OP进行优化,加快模型的推理速度。dlNNE 除了有常见的OP融合以及显存/内存优化外,还针对性的对OP进行了优化加速实现,降低推理延迟,提升推理的吞吐量。

如何利用Paddle Inference
跑通登临GPU+产品
A. 环境准备
请确保您的飞桨开源框架v2.1或更高的版本。Paddle-dlNNE 只能在飞桨开源框架v2.1或更高的版本上运行。
请手动编译源码生成 whl 包。手动编译的方法请参照 编译文档。
注意:
-
手动编译飞桨源码时需要在登临 Hamming™ SDK 环境下执行。Hamming™ SDK由登临官方提供。
cmake 期间,设置 WITH_DLNNE 为 ON,设置 WIHT_GPU 为 OFF,设置 WITH_PYTHON 为 ON。
B. 用Paddle-dINNE进行推理
一般来说Paddle Inference推理流程包含了下面五个步骤:
配置推理选项
创建 predictor
准备模型输入
模型推理
获取模型输出
使用 Paddle-dlNNE 也是遵照这样的流程。我们先用一个简单的例子来介绍这一流程(我们假设您已经对 Paddle Inference 有一定的了解,如果您刚接触 Paddle Inference,请访问 这里 对 Paddle Inference 有个初步认识)。
import numpy as np
import paddle.inference as paddle_infer
#子图转onnx 子图工具
import p2o_converter
def create_predictor():
config = paddle_infer.Config("./resnet50/model", "./resnet50/params")
# 打开dlNNE。此接口的详细介绍请见下文
config.enable_dlnne(max_batch_size = 1,
min_subgraph_size = 3,
precision_mode=paddle_infer.PrecisionType.Float32)
predictor = paddle_infer.create_predictor(config)
return predictor
def run(predictor, img):
# 准备输入
input_names = predictor.get_input_names()
for i, name in enumerate(input_names):
input_tensor = predictor.get_input_handle(name)
input_tensor.reshape(img[i].shape)
input_tensor.copy_from_cpu(img[i].copy())
# 推理
predictor.run()
results = []
# 获取输出
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_handle(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
if __name__ == '__main__':
pred = create_predictor()
img = np.ones((1, 3, 224, 224)).astype(np.float32)
result = run(pred, [img])
print ("class index: ", np.argmax(result[0][0]))
通过例子可以看出,我们通过 enable_dlnne 接口来开启 dlNNE 选项。
config.enable_dlnne(max_batch_size = 1,
min_subgraph_size = 3,
precision_mode=paddle_infer.PrecisionType.Float32)enable_dlnne 接口各参数的介绍如下:
max_batch_size
类型为 int。默认值为1。
需要提前设置最大的 batch 的大小,运行时 batch 的大小不得超过此限定值。
min_subgraph_size
类型为 int。默认值为3。
Paddle-dlNNE 以子图的形式运行。为避免性能损失,只有当子图内部节点个数大于 min_subgraph_size 的时候,才会调用 Paddle-dlNNE 运行。
precision_mode
类型为 paddle_infer.PrecisionType。默认值为 paddle_infer.PrecisionType.Float32。
指定使用 Paddle-dlNNE 的精度,目前支持 FP32 (float32)。int8 量化类型将在后续支持。
遵循以上步骤您就可以利用Paddle-dINNE完成在登临GPU+系列产品上的深度学习推理, 如果您有更多的模型打通需求,欢迎在https://github.com/PaddlePaddle上给我们提Issue反馈,我们会即时跟进,希望这篇文章对您的工作有帮助!

飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件、丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。
目前,飞桨已凝聚超320万开发者,服务企业12万家,产生了36万个模型。飞桨助力开发者快速实现AI想法,高效上线AI业务,帮助越来越多的行业完成AI赋能,实现产业智能化升级。

登临科技是国内首家完全凭借自主创新,构建GPGPU核心技术的云端AI计算平台公司。登临科技的GPU+系列产品开创了新一代 AI通用处理器/加速器的先河,成功填补了国内高性能GPU领域技术和产品方面的空白,并在多个行业应用场景中成功实现了商业化落地。
公司自主创新的GPU+(软件定义的异构人工智能计算平台),完美解决了通用性和高效率的双重难题,在提供具备CUDA/OpenCL硬件加速能力的前提下,全面支持各类流行的人工智能网络框架及底层算子。目前,首款基于GPU+架构的Goldwasser系列产品已在多个行业的领军企业进行量产导入,并得到客户的积极反馈。
如有飞桨相关技术有问题,欢迎在飞桨论坛中提问交流:
http://discuss.paddlepaddle.org.cn/
欢迎加入官方QQ群获取最新活动资讯:793866180。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
·飞桨开源框架项目地址·
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle

????长按上方二维码立即star!????
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END
