每天一篇论文 333/365 Multi-object Monocular SLAM for Dynamic Environments
Multi-object Monocular SLAM for Dynamic Environments
每天一篇论文汇总list
摘要
动态环境下的多体单目SLAM在感知和状态估计方面仍然是一个长期的挑战。尽管存在理论上的解决方案,但实践却滞后,主要原因是缺乏动态参与者的稳健感知和预测模型。动态场景中的多体单目SLAM的典型挑战源于不可观测性问题,因为不可能从移动的单目摄像机中三角化运动对象。在物体运动的限制下,这个问题是可以解决的,但即使在这里也需要一个相对尺度问题的单族解来解决。由于用单目相机重建的动态物体相对于重建静止场景的尺度空间具有不同的尺度,因此存在相对尺度问题。我们通过对象SLAM框架在度量尺度上重建单视图中的动态车辆/参与者来解决这个相当棘手的问题。此外,我们还利用地平面特征将单目ORB-SLAM获得的ego车辆轨迹提升到度量尺度,从而解决了相对尺度问题。提出了一种多姿态图优化方法,用于估计环境中的姿态和跟踪动态目标。这种优化方法有助于减少KITTI跟踪序列中多个目标轨迹的平均误差。据我们所知,我们的方法是第一个实际的单目多体SLAM系统,在统一的度量尺度框架下执行动态多目标和自我定位。
贡献
1) 利用米制尺度下的三维深度得到静态地平面特征对应关系估计里程。
2) 以姿势图的形式恰当地描述各种动态车辆与自我车辆之间的关系。
3) 利用单个优化问题对场景中的多个动态车辆和动态ego车辆进行定位和映射。
4) 实用性:我们从KITTI驱动数据集[13]中评估了我们的挑战性序列方法,并提出了第一个实用的单目多体SLAM系统。
方法

本文框架主要有三部分组成
A、 地平面上点的深度估计
为了估计边界框里的点的深度做一个假设,即在整个序列中,ego相机始终与地平面保持恒定的高度。假设摄像机距地平面的高度为h米,距地平面的法向量为n,摄像机内禀校准矩阵为K,图像空间中的二维均匀坐标为xt,如下方法获得图像空间中对应点的三维深度
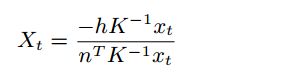
B、 里程估计
里程计作者提出一种从ORB-SLAM2输入中通过最小化每对连续帧之间的接地点对应的重新投影误差来缩放自我运动的方法。在给定t-1和t帧的情况下,在ORBSLAM2中分别以Tt-1和Tt的形式在ORB尺度的3D中初始化了odometry。得到两帧之间的相对里程,如下所示:

在获得ORB特征来匹配两帧t-1和t之间的点对应,并使用最新的语义分割网络来检索位于地平面上的点xt-1和xt。使用Song等人在相应的相机帧t-1和t中估计出3D中的对应点Xt-1和Xt。为了得出上述方法所包含的噪声,我们只考虑距摄像机12米深度内的点。

C、 位姿和形状自适应框架
本文从Murthy等人的方法中得到灵感,通过调整形状和姿势来获得目标的定位。本文对象表示遵循[30]-[32],它基于由K个有序关键点组成的形状先验,每个关键点代表一个特定的视觉可分辨特征,而我们的对象主要由汽车和小型货车组成。对于这项工作,我们坚持使用来自Ansari等人的相同的36个关键点结构。[32]。我们使用基于叠加沙漏结构的CNN在2D图像空间中获得目标的关键点定位[33],并使用针对Ansari等人240多万个渲染图像训练的相同模型。[32]。


多目标位姿图优化

结果

**姿势和形状自适应:**我们通过将基本形状先验值拟合到场景中的每个非遮挡和非截断的车辆,从而获得ego相机帧中的精确定位,而不考虑其相对于ego相机的方向。虽然管道依赖于这些车辆上的关键点定位,但像来自摄像机的大深度这样的因素必然会影响地面真实度的精度。然而,这种方法确保了相当精确的车辆定位,以便姿势图优化器应用其边缘约束。图6示出了由多辆车组成的交通场景的ego帧中的线框拟合和随后的建图。

里程计
