RPN定位模块细节回顾
一、主干网络与FPN多尺度特征提取
将一张高宽为H*W的图像输入深度网络,经过主干网络与FPN结构后输出不同级别的特定分辨率特征。
P2:torch.size(1,256,H/4, W/4)
P3:torch.size(1,256,H/8, W/8)
P4:torch.size(1,256,H/16,W/16)
P5:torch.size(1,256,H/32,W/32)
P6:torch.size(1,256,H/64,W/64)

不同级别的特征都是经过了不同尺度的下采样,对应着不同的目标感受野,可适用于不同尺度的目标定位。
二、RPN Head
RPN Head是一个极简神经网络,主要由一个256通道的3x3卷积与两个独立的分别用于前景分类与目标框偏差回归的1x1卷积组成。
其中分类分支的1x1卷积通道数为一个特征点设置的anchor数量K(3)
其中回归分支的1x1卷积通道数为4*K(每个anchor都要回归4个坐标参数)

前面得到的5种级别的特征会依次分别作为RPN Head的输入,并得到对应级别特征的预测输出;
其中分类分支的输出1x3xHixWi对应着三个通道(对应3个不同形状的anchor)的目标存在概率特征图,再经sigmoid函数激活后,每个位置的分数都可以表示此位置感受野中存在前景目标的概率值。
其中回归分支的输出1x12xHixWi的每个位置都对应着3个不同形状anchor的4个坐标回归参数(纠正偏离以接近对应标注框)。
三、正负样本选择与采样
假定输入图像中存在一个前景目标,训练中,我们需要从所有预设的anchor中根据IoU阈值选择对应数量的正样本与负样本,其中正负样本用于前景、背景分类,只有正样本需要进行坐标参数回归。
(1)Anchor生成
首先根据多级特征图的大小与anchor预设参数,使用anchor_generator函数生成对应级别特征上的anchor,然后torch.cat函数将不同级别特征上的anchor按顺序拼接组合,得到此图对应的所有可用anchor。
(2)正负样本选择
在获取到anchor后,先对此图前景目标的标注框gt_bboxes与所有anchor进行IoU重叠率计算得到一个IoU矩阵,然后为每一个anchor匹配一个重叠率最大的标注框,进而根据负样本阈值neg_iou_thr将低于阈值的anchor设定为负样本(标签为0),将大于正样本设定阈值pos_iou_thr的anchor设定为正样本(标签为1),其它anchor(标签为-1)不参与训练。此外,为了避免某些标注框没有超过阈值的正样本匹配anchor,可以考虑与标注匹配的低质量anchor,具体就是为每一个标注框匹配一个具有最大重叠率的anchor,然后将重叠率大于设定阈值min_pos_iou的设置为正样本。
(3)正负样本采样
在经过前面的正负样本选择过程,我们得到了一定数量的正样本与大量的负样本,为了避免正负样本在数量上严重失衡,需要进一步对样本数量与样本比例进行限制。FasterRCNN论文中默认设置共采样256个样本,其中正负样本的比例为1:1。
具体就是如果正样本的数量m少于128个,就全部作为正样本,如果超过128个,就随机选择128个作为正样本,其它设置为-1标签不参与训练;
在采样完所需正样本后,将所需的256个样本中除去正样本数量,得到所需的负样本数量,如果负样本总数量n大于所需数量,随机采样所需数量后,其余设置标签为-1不参与训练,否则全部作为负样本。
通常情况下,传统采样方法得到的正样本数量相对较少,尤其对于小目标来说。
三、训练目标设定
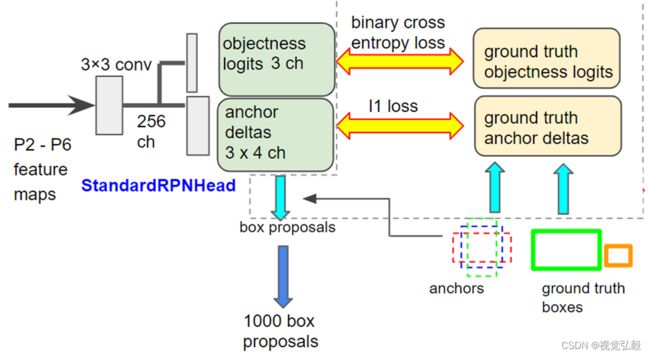
在获取到所需数量的正负样本之后,我们会为对应正负样本的每个anchor设定对应的正负标签(1与0),然后将正负样本重新映射回到对应的不同级别特征上,通过对应特征级别上的分类分支进行判别学习。
同时,基于标注框与正样本anchor,计算出对应anchor的回归目标偏差,然后将正负样本重新映射回到对应的不同级别特征上,通过对应特征级别上的回归分支进行做坐标偏差的回归学习。
由于FPN多尺度融合特征的使用,我们知道在训练过程中,不同尺度的目标通常会在对应级别特征上进行前景分类与坐标回归的学习,很大程度上缓解了单一尺度级别上多尺度目标学习的困难。
参考资料:
1 Digging into Detectron 2 — part 4 | by Hiroto Honda | Medium
2 MMDetection源码