python数据分析-分组把DataFrame列转行
问题:遇到了一个问题是需要根据DataFrame中的某一列把对应另一列的数据由列转为行。
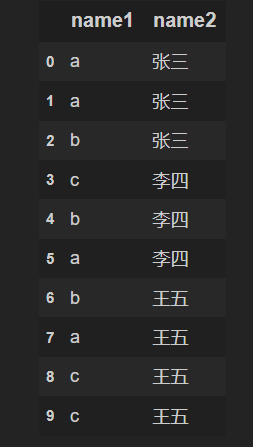
一、数据展示
a = pd.DataFrame({'name1':['a','a','b','c','b','a','b','a','c','c'],
'name2':['张三','张三','张三','李四','李四','李四','王五','王五','王五','王五']})
display(a)
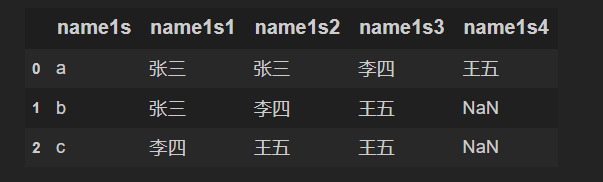
目标样式:
二、解决思路
1、先计算出应该创建最长是多少列,比如举例数据a分组有4个元素b、c分组有三个元素,则按照最大的值创建列数然后不够长的分组用空值填充,并创建新的DataFrame为下面的循环准备。
group_name = 'name1' #用于分组的列名
trans_name = 'name2' #要变为横向的列名
#对要用于分组的数据做排序,目的是可以先查看数据
aa = aa.sort_values(by='%s' %group_name,ascending=True).reset_index(drop=True)
# 取出要转为行的列,并存为DF备用
bb = pd.DataFrame({group_name:aa[group_name],trans_name:aa[trans_name]})
cc = pd.DataFrame({group_name:aa[group_name],trans_name+'_count':aa[trans_name]})
#取出每个id应该被创建几次(即:应该创建的最长是几列)
ee = cc.groupby([group_name],sort=False,as_index=False).count()
a = list(ee[trans_name+'_count'])
#找出id重复最多的次数,即:应该创建多少列
b = a.copy()
b.sort()
print("最大元素为:", b[-1])
#创建准备接收排列数据的空数据框
dd = pd.DataFrame({group_name+'s':[]})
for i in range(1,b[-1]+1):
dd[group_name+'s'+str(i)] = ''
print("dd的维度为:",dd.shape)
2、用循环循环按行取出每组中的元素并添加到空DataFrame中,然后每次做一个新的包含一行数据的DataFrame,把每次取出的数据合并,即可得到最后的按组转为行的数据。
#为上面取出来的数据按照最大的列数创建新的列
ii = 0
loc_num = 0
qqqq = pd.DataFrame({group_name+'s':[1]})
qqq = pd.DataFrame({group_name+'s':[1]})
while ii < len(a):
ee = pd.DataFrame({group_name+'s':[1]})
#先做的空数据框,是有两条空数据的,后面要把这两行删除
qqq = pd.concat([qqq,qqqq],axis=0)
#用切片循环取出要转为行的数据
for i in range(1,a[ii]+1):
ee[group_name+'s'+str(i)] = bb.loc[loc_num,trans_name]
loc_num +=1
qqqq = pd.concat([dd,ee],axis=0)
ii +=1
#合并每次取出的数据,组成新的数据框
qqqqq = pd.concat([qqq,qqqq],axis=0)
qqqqq = qqqqq.reset_index(drop=True)
#删除前面两行数据,因为前面是向含有一行数据的数据框中添加的每条的数据。
qqqqq.drop(labels=range(0,2),inplace=True) #按照索引删除行
qqqqq = qqqqq.reset_index(drop=True)
#####导出去重了的原始表的列,然后去重,用于添加qqq缺失的最后一行数据 #contract_codes
mm = cc.copy()
mm.drop_duplicates([group_name],keep='first',inplace=True)
mm = mm.reset_index(drop=True)
#用mm中的列替换qqqqq中的列,qqqqq就是最后处理完毕的数据
qqqqq[group_name+'s'] = mm[group_name]
print('程序已经执行结束')
3、完整的代码如下,工作中需要处理的数据6000+条,运行速度很快,不知道如果数据量非常大怎么样,后续有需要的话再优化代码,这次要求比较急,所以写的比较简单。
import pandas as pd
import numpy as np
import os
#等待处理的数据
aa = pd.DataFrame({'name1':['a','a','b','c','b','a','b','a','c','c'],
'name2':['张三','张三','张三','李四','李四','李四','王五','王五','王五','王五'],
'name3':[12,223,36,44,5,12,63,2,12,234]})
# aa = pd.read_excel(r'E:\\xxxxxxxxxxxxx\\xxxxxx\\xxxxxxx.xlsx')
group_name = 'name1' #用于分组的列名
trans_name = 'name2' #要变为横向的列名
#对要用于分组的数据做排序,目的是可以先查看数据
aa = aa.sort_values(by='%s' %group_name,ascending=True).reset_index(drop=True)
# 取出要转为行的列,并存为DF备用
bb = pd.DataFrame({group_name:aa[group_name],trans_name:aa[trans_name]})
cc = pd.DataFrame({group_name:aa[group_name],trans_name+'_count':aa[trans_name]})
#取出每个id应该被创建几次(即:应该创建的最长是几列)
ee = cc.groupby([group_name],sort=False,as_index=False).count()
a = list(ee[trans_name+'_count'])
#找出id重复最多的次数,即:应该创建多少列
b = a.copy()
b.sort()
print("最大元素为:", b[-1])
#创建准备接收排列数据的空数据框
dd = pd.DataFrame({group_name+'s':[]})
for i in range(1,b[-1]+1):
dd[group_name+'s'+str(i)] = ''
print("dd的维度为:",dd.shape)
#为上面取出来的数据按照最大的列数创建新的列
ii = 0
loc_num = 0
qqqq = pd.DataFrame({group_name+'s':[1]})
qqq = pd.DataFrame({group_name+'s':[1]})
while ii < len(a):
ee = pd.DataFrame({group_name+'s':[1]})
#先做的空数据框,是有两条空数据的,后面要把这两行删除
qqq = pd.concat([qqq,qqqq],axis=0)
#用切片循环取出要转为行的数据
for i in range(1,a[ii]+1):
ee[group_name+'s'+str(i)] = bb.loc[loc_num,trans_name]
loc_num +=1
qqqq = pd.concat([dd,ee],axis=0)
ii +=1
#合并每次取出的数据,组成新的数据框
qqqqq = pd.concat([qqq,qqqq],axis=0)
qqqqq = qqqqq.reset_index(drop=True)
#删除前面两行数据,因为前面是向含有一行数据的数据框中添加的每条的数据。
qqqqq.drop(labels=range(0,2),inplace=True) #按照索引删除行
qqqqq = qqqqq.reset_index(drop=True)
#####导出去重了的原始表的列,然后去重,用于添加qqq缺失的最后一行数据 #contract_codes
mm = cc.copy()
mm.drop_duplicates([group_name],keep='first',inplace=True)
mm = mm.reset_index(drop=True)
#用mm中的列替换qqqqq中的列,qqqqq就是最后处理完毕的数据
qqqqq[group_name+'s'] = mm[group_name]
print('程序已经执行结束')
最后,如果大家有简单的方法欢迎交流。