一个大数据学生的HDFS完全分布式集群搭建流程与问题
目录
- 前言
- 一、HDFS是什么?
- 二、搭建流程
-
- 1.检查系统
-
- 1.1 检查各主机名
- 1.2 检查hosts文件
- 1.3 检查免密登录
- 1.4 检查JDK
- 2. 配置过程
-
- 2.1 创建安装目录
- 2.2 上传并解压文件
- 2.3 配置HADOOP_HOME环境变量
- 2.4 配置hadoop-env.sh
- 2.5 配置yarn-env.sh
- 2.6 配置core-site.xml
- 2.7 配置hdfs-site.xml
- 2.8 配置mapred.site.xml
- 2.9 配置yarn-site.xml
- 2.10 配置slaves
- 2.11 同步配置文件
- 2.12 配置环境变量
- 3.配置集群
-
- 3.1 格式化
- 3.2 启动集群
- 3.3 查看启动情况
- 3.4 上传文件测试
- 三、常见问题
- 总结
前言
HDFS作为Hadoop的核心组件,其搭建是Hadoop集群能够成功运行的基础,本文就描述了我在搭建HDFS集群时的流程与遇到的问题。
一、HDFS是什么?
HDFS是一个完全分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
二、搭建流程
1.检查系统
首先我们应该有一个做好免密登录且互相连接的虚拟机流程详见
链接: https://blog.csdn.net/qq_53879605/article/details/126883887?spm=1001.2014.3001.5501
1.1 检查各主机名
vi /etc/hostname
node01的主机名 (node02,node03同样要检查,为简便后文以01,02,03称呼)
1.2 检查hosts文件
vi /etc /hosts

01,02,03host文件相同
1.3 检查免密登录
ssh node02

用01登录02,03若成功则无误,若不能登录
见链接: https://blog.csdn.net/qq_53879605/article/details/126883887?spm=1001.2014.3001.5501
1.4 检查JDK
java -version

02,03都应检查
2. 配置过程
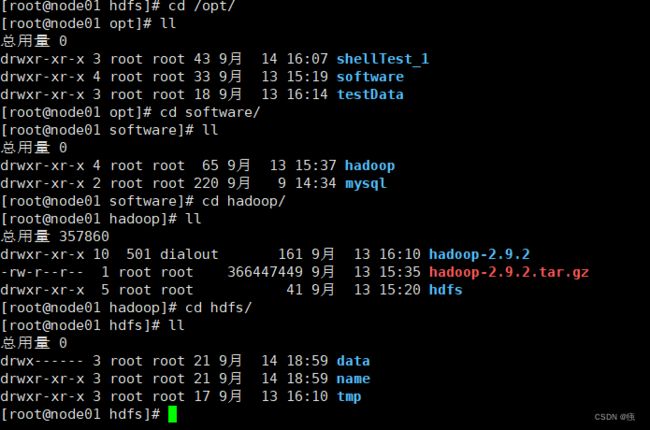
2.1 创建安装目录
cd /opt
mkdir software
cd software/
mkdir hadoop
cd hadoop/
mkdir hdfs
cd hdfs/
mkdir data
mkdir name
mkdir tmp
2.2 上传并解压文件
cd /opt/software/hadoop
yum-y install lrzsz
rz # 上传hadoop-2.9.2.tar.gz
tar -xvzf hadoop-2.9.2.tar.gz
上传Hadoop时只需将hadoop-2.9.2.tar.gz 拖到xshell下即可
文件下载链接: https://pan.baidu.com/s/1kcu2FvwjKTijW-lMd4h6VQ?pwd=yre0
提取码yre0
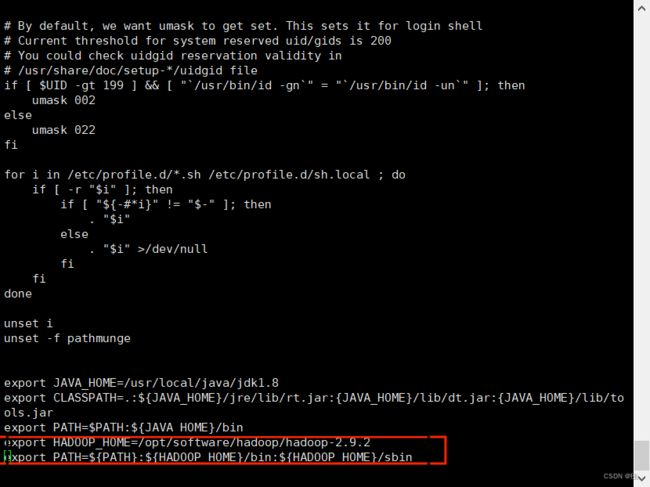
2.3 配置HADOOP_HOME环境变量
vi /etc/profile
#修改的语句为
export HADOOP_HOME=/opt/software/hadoop/hadoop-2.9.2
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
刷新环境变量
source /etc/profile
测试Hadoop是否安装
hadoop version

2.4 配置hadoop-env.sh
无需修改配置 只是修改JAVAHOME和HADOOPCONF_DIR的值
cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/
vi hadoop-env.sh
修改配置值为
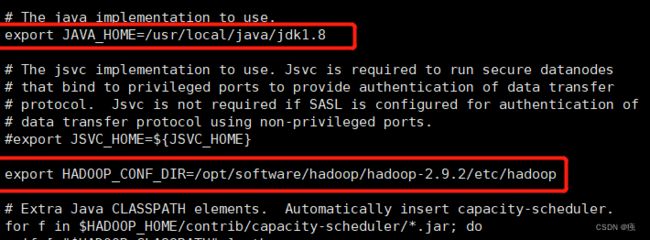
export JAVA_HOME=/usr/local/java/jdk1.8
export HADOOP_CONF_DIR=/opt/software/hadoop/hadoop-2.9.2/etc/hadoop
2.5 配置yarn-env.sh
此步新增JAVAHOME
需找到#export JAVAHOME=/home/y/libexec/jdk1.6.0/
并在下面添加JAVAHOME的配置文件
cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/
vi yarn-env.sh
#添加配置文件为
export JAVA_HOME=/usr/local/java/jdk1.8
![]()
2.6 配置core-site.xml
此步是将文件系统节点改为node01
•fs.defaultFS表示指定集群的文件系统类型是分布式文件系统(HDFS),datanode发送到namenode的地址
•hadoop.tmp.dir表示hadoop临时文件目录
vi core-site.xml
#添加配置文件为
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop/hdfs/tmp</value>
</property>
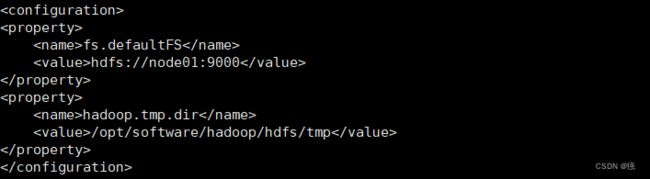
2.7 配置hdfs-site.xml
dfs.replication原本配置是1,修改为3,表示副本数是3
dfs.datanode.max.locked.memory配置添加,配置值根据自己机器情况配置
dfs.permissions配置添加,值配置false,不开启文件权限
cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/
vi hdfs-site.xml
#添加的配置文件为
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/software/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/software/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>65536</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
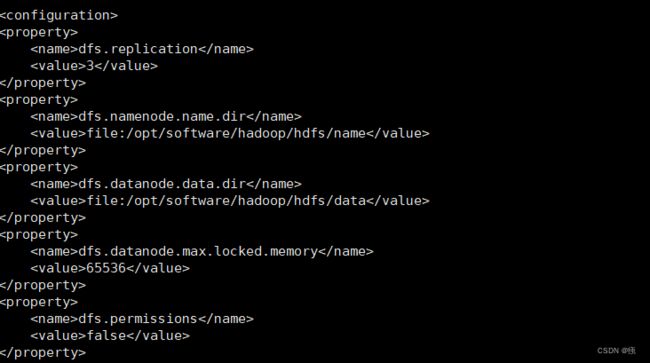
其中dfs.datanode.max.locked.memory需要与自身机型配置
利用ulimit -l 参数查询
value是字节数(Byte),那么64*1024=65536 Byte
2.8 配置mapred.site.xml
首先需要吧mapred-site.xml.template拷贝成mapred-site.xml
cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
#添加的配置文件为
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

2.9 配置yarn-site.xml
vi yarn-site.xml
#添加的配置文件
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
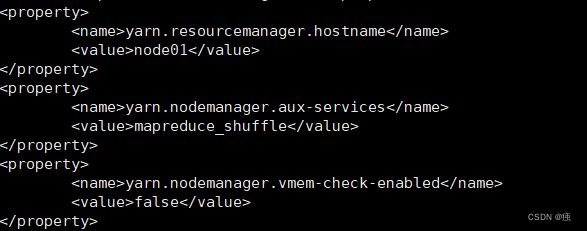
2.10 配置slaves
配置3台机器主机名,此配置表示三台机器都作为DataNode
cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/
vi slaves
node01
node02
node03

2.11 同步配置文件
在02 03上创建software目录
cd /opt/
mkdir software
将01上的hadoop分发到02,03
使用scp进行分发同步
cd /opt/software/
scp -r hadoop/ node02:$PWD
scp -r hadoop/ node03:$PWD
2.12 配置环境变量
之前只在01上配置了hadoop环境变量,现在需要在02和03上添加hadoop环境变量
vi /etc/profile
#添加配置文件
export HADOOP_HOME=/opt/software/hadoop/hadoop-2.9.2
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
配置完后添加位置文件使配置生效
source /etc/profile
3.配置集群
3.1 格式化
在01上进行格式化
hdfs namenode -format

出现如图 格式化成功
3.2 启动集群
只在01上启动即可
start-dfs.sh
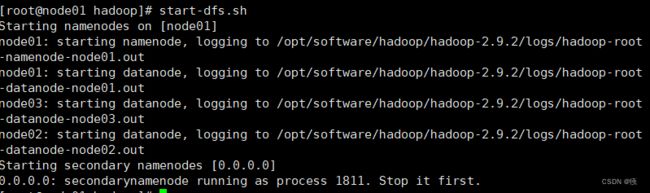
3.3 查看启动情况
jps
node01
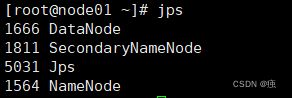
node02

node03

使用浏览器访问管理台
链接: http://192.168.67.110:50070/


3.4 上传文件测试
创建目录
cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/
hdfs dfs -mkdir /test
![]()

上传文件
cd /opt/
mkdir testData
cd testData/
mkdir hdfs
cd hdfs
上传文件将文件拖入Xshell中即可

文件上传后检查datanode节点情况
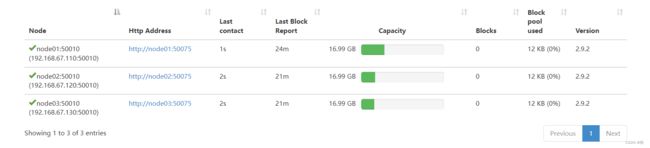
!!!注意在完成所有步骤后在虚拟机中拍摄快照,如果出现问题可以从快照中恢复。
三、常见问题
1.配置文件时,Hadoop的目录是
/opt/software/hadoop/hadoop-2.9.2/etc/hadoop
2.注意在分发hadoop文件后要配置02,03的环境变量,并重新加载。
3.若虚拟机出现启动时输入密码后出现无法登录,可能是该虚拟机的配置文件出了问题,挑选一个好的虚拟机分发配置文件,并重新加载。
scp -r /etc/profile node03:$PWD
总结
以上就是HDFS完全分布式集群搭建的大概流程,有许多问题没有遇到,可能问题写的不够详细,如果有文章和流程中有任何的问题以及心得欢迎评论交流。