ElasticStack运维必备技能-集群版
一、背景介绍
首先,我们为什么要用这个产品呢?生产业务中必然会遇到大量业务日志需要分析,在日志量非常大的场景中,直接使用工具,如cat、grep、awk 就可以获得想要的信息,效率非常低,在这种情况下,如何快速搜索想要信息,如查询、排序、归档、展现等,开源实时日志分析ELK就可以很好的解决上面的场景问题。
二、为何使用Elasticsearch
Elasticsearch 很快。由于 Elasticsearch 是在 Lucene 基础上构建而成的,所以在全文本搜索方面表现十分出色。Elasticsearch 同时还是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。因此,Elasticsearch 非常适用于对时间有严苛要求的用例,例如安全分析和基础设施监测。
Elasticsearch 具有分布式的本质特征。Elasticsearch 中存储的文档分布在不同的容器中,这些容器称为分片,可以进行复制以提供数据冗余副本,以防发生硬件故障。Elasticsearch 的分布式特性使得它可以扩展至数百台(甚至数千台)服务器,并处理 PB 量级的数据。
Elasticsearch 包含一系列广泛的功能。除了速度、可扩展性和弹性等优势以外,Elasticsearch 还有大量强大的内置功能(例如数据汇总和索引生命周期管理),可以方便用户更加高效地存储和搜索数据。
Elastic Stack 简化了数据采集、可视化和报告过程。通过与 Beats 和 Logstash 进行集成,用户能够在向 Elasticsearch 中索引数据之前轻松地处理数据。同时,Kibana 不仅可针对 Elasticsearch 数据提供实时可视化,同时还提供 UI 以便用户快速访问应用程序性能监测 (APM)、日志和基础设施指标等数据。
收集-采集多种来源的日志数据
传输-能够稳定的把日志数据传输到中央系统
存储-如何存储日志数据
分析-可以支持 UI 分析
警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
应用程序搜索
网站搜索
企业搜索
日志处理和分析
基础设施指标和容器监测
应用程序性能监测
地理空间数据分析和可视化
安全分析
业务分析
…
三、ELK介绍和Elastic Stack的由来
那么,ELK 到底是什么呢? “ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。Elasticsearch 是一个搜索和分析引擎。Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
Elastic Stack 是 ELK Stack 的更新换代产品。
2015 年,我们向 ELK Stack 中加入了一系列轻量型的单一功能数据采集器,并把它们叫做 Beats。之后ELK 多了一个新成员,并改名为 Elastic Stack(下文中部分简写为ES)
- Elasticsearch 基于java开发,是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能,提供索引自动分片,索引副本机制,restful风格接口,支持多数据源导入
- Logstash 基于java开发,主要是用来日志的搜集、分析、存储日志的工具,支持大量的数据获取方式,c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去
- Kibana 基于nodejs开发,也是一个开源和免费的工具,配合Elasticsearch和Logstash,提供web展示界面
Beats 是elastic公司开发的采集系统监控数的代理agent,运行在被采集的机器中,把数据直接或者经过Logstash发送给Elasticsearch,进行后续的数据分析,在没Beats出现前,数据采集是由Logstash进行获取的
Beats子项
1)Packetbeat:是一个网络数据包分析器,用户监控和收集网络流量信息
2)Filebeat:用于监控和收集服务器日志文件,已取代Logstash forwarder
3)Metricbeat:定期获取外部系统的监控指标信息,如Apache HAProxy、Mysql、Nginx、redis等等
4)Winlogbeat:用户收集和监控windows系统的日志信息


四、工作原理和产品架构
4.1 工作原理
原始数据会从多个来源(包括日志、系统指标和网络应用程序)输入到 Elasticsearch 中。数据采集指在 Elasticsearch 中进行索引之前解析、标准化并充实这些原始数据的过程。这些数据在 Elasticsearch 中索引完成之后,用户便可针对他们的数据运行复杂的查询,并使用聚合来检索自身数据的复杂汇总。在 Kibana 中,用户可以基于自己的数据创建强大的可视化,分享仪表板,并对 Elastic Stack 进行管理。
数据处理流程:
数据由Beats采集后,可以选择直接推送给Elasticsearch检索,或者先发送给Logstash处理,再推送给Elasticsearch,最后都通过Kibana进行数据可视化的展示
4.2 产品架构
ES集群由多节点组成,每个节点通过node.name指定节点的名称
节点类型主要有4种:
1、master节点
- 配置文件中node.master属性为true,就有资格被选为
- master节点用于控制整个集群的操作,比如创建和删除索引,以及管理非master节点
2、data节点
- 配置文件中node.data属于为true,就有资格被选为data节点
- 主要用于执行数据相关的操作
3、客户端节点
- 配置文件中node.master和node.data均为false(既不能为master也不能为data)
- 用于响应客户的请求,把请求转发到其他节点
4、部落节点
- 当一个节点配置tribe.*的时候,它是一个特殊的客户端,可以连接多个集群,在所有集群上执行索引和操作
五、Elastic Stack平台搭建
5.1 环境准备
1)系统环境
| IP地址 | 主机名 | 系统版本 | cpu | 内存配置 | 磁盘 |
|---|---|---|---|---|---|
| 192.168.10.134 | elk-01 | centos7.4_x64 | 4 | 2G | 60G |
| 192.168.10.135 | elk-02 | centos7.4_x64 | 4 | 2G | 60G |
| 192.168.10.136 | elk-03 | centos7.4_x64 | 4 | 2G | 60G |
说明:
1、 关闭防火墙和selinux
#systemctl stop firewalld.service
#setenforce 0
2、 host绑定
#192.168.10.134 elk-01
#192.168.10.135 elk-02
#192.168.10.136 elk-03
3、 yum源配置
#wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
2)软件环境
| 软件名称 | 版本 |
|---|---|
| jdk | jdk-8u211-linux-x64.rpm |
| elasticsearch | elasticsearch-7.15.2-linux-x86_64.tar.gz |
| elasticsearch-head | elasticsearch-head:5 |
| logstash | logstash-7.15.2-linux-x86_64.tar.gz |
| kibana | kibana-7.15.2-linux-x86_64.tar.gz |
注:由于ELK 5.0之前版本管理比较混乱,所有组件没有统一版本,而Elastic Stack版本之后,进行了统一,本次实践版本均采用7.15.2
5.2 Elasticsearch
5.2.1 elasticsearch安装准备
1)创建用户
#useradd elsearch
2)创建/home/elsearch/es/所需目录
#mkdir -p /home/elsearch/es
#mkdir -p /home/elsearch/data
#mkdir -p /home/elsearch/log
#chown -R elsearch:elsearch /home/elsearch
3)将elasticsearch-7.15.2-linux-x86_64.tar.gz上传至es目录(elsearch用户操作)
下载地址: https://www.elastic.co/cn/downloads/
4)解压tar包(elsearch用户操作)
注意:两台机器内均需完成以上操作#tar -zxvf elasticsearch-7.15.2-linux-x86_64.tar.gz
5.2.2 修改系统配置文件
1) 虚拟内存区域创建内存映射最大数量
vim /etc/sysctl.conf
vm.max_map_count=655360
#sysctl - p
2) 使用root用户修改/etc/security/limits.conf文件,添加或修改如下内容:
注意:所有elk机器均需要做sysctl.conf和limits.conf修改,elsearch代表对应的登录名elsearch hard nofile 65536
elsearch soft nofile 65536

5.2.3 修改elasticsearch配置文件
1) 在elk-01机器中备份elasticsearch/elasticsearch.yml文件(elsearch用户操作)
#cp elasticsearch.yml elasticsearch.yml.bak
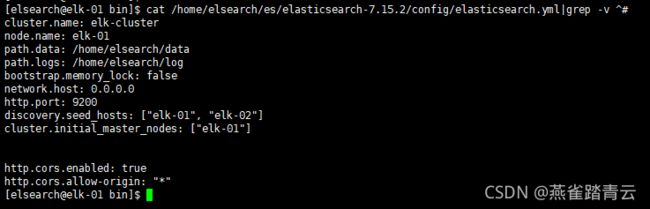
2) 修改vim elasticsearch.yml文件
elk-01的配置
cluster.name: elk-cluster #集群名字
node.name: elk-01 #添加本机在集群内的节点名称
path.data: /home/elsearch/data
path.logs: /home/elsearch/log
bootstrap.memory_lock: false
network.host: 192.168.10.134 #若是更改ip地址为0.0.0.0,允许任意网络访问,若是机器内有docker服务,需要配置本地地址
http.port: 9200
discovery.seed_hosts: [“192.168.10.134”, “192.168.10.135”,“192.168.10.136”]
cluster.initial_master_nodes: [“elk-01”,“elk-02”,“elk-03”] #master为elk-01、elk-02和elk-03中选举(必须大于节点数n/2+1)
http.cors.enabled: true #是否支持跨域,elasticsearch-head插件会用到,需要打开
http.cors.allow-origin: “*” # * 表示支持所有域名

elk-02的配置
cluster.name: elk-cluster
node.name: node-2
path.data: /home/elsearch/data
path.logs: /home/elsearch/log
bootstrap.memory_lock: false
network.host: 0.0.0.0 #配置0.0.0.0即可
http.port: 9200
discovery.seed_hosts: [“192.168.10.134”, “192.168.10.135”,“192.168.10.136”]
cluster.initial_master_nodes: [“elk-01”,“elk-02”,“elk-03”]
http.cors.enabled: true
http.cors.allow-origin: “*”
elk-03的配置
注意:具体参数配置请参考官网 https://www.elastic.co/guide/en/elasticsearch/reference/7.16/important-settings.htmlcluster.name: elk-cluster
node.name: node-3
path.data: /home/elsearch/data
path.logs: /home/elsearch/log
bootstrap.memory_lock: false
network.host: 0.0.0.0 #配置0.0.0.0即可
http.port: 9200
discovery.seed_hosts: [“192.168.10.134”, “192.168.10.135”,“192.168.10.136”]
cluster.initial_master_nodes: [“elk-01”,“elk-02”,“elk-03”]
http.cors.enabled: true
http.cors.allow-origin: “*”
如果启动过程中遇到提示172.17.0.1地址报错,elk-01的本机IP为192.168.10.134, 但在注册成es节点时的IP确是 172.17.0.1,由于172.17.0.1 这个是被docker使用地址(elasticsearch-head为容器部署),而ES集群中只有该节点装有docker,导致不能通过172.17.0.1跟其他192.168.10.*上的节点通信。
解决方法:将elk-01修改为network.host: 192.168.10.134,可解决)
4) 在所有机器中修改vim config/jvm.options #可根据自己情况修改(elsearch用户操作)
说明:如果network.host不是localhost或者127.0.0.1的话,程序会默认是生产环境,对配置要求较高,因为需要做 4)的修改-Xms1024m (默认2g且注释状态)
-Xmx1024m (默认2g且注释状态)
5.2.4 启动Elasticserch服务
1)进入bin目录下,执行./elasticsearch启动服务(建议放到后台运行)
[elsearch@elk-01 bin]$ ./elasticsearch &
注意:如果启动失败,需要集群全部重启的时候,需要删除elasticsearch中的data目录内所有文件,然后再执行重启
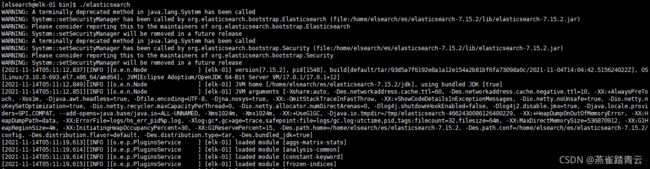
2)通过浏览器访问elasticsearch端口
http://192.168.10.134:9200
http://192.168.10.135:9200
http://192.168.10.136:9200

5.3 elasticsearch插件head
我们不可能经常通过命令来查看集群的信息,由于官方没有提供ES的界面管理平台或者官方提供的都是收费的,所以我们就使用到了第三方插件 –head,对elasticsearch集群的状态监控与管理配置等功能。head主要用来做集群管理的插件。
下载地址:https://github.com/mobz/elasticsearch-head
5.3.1 Elasticsearch head 提供的主要功能
ClusterOverview,它显示集群的拓扑,并允许您执行索引和节点级别的操作
几个搜索界面,使您可以查询集群以原始json或表格格式检索结果
几个快速访问选项卡,显示集群的状态
输入部分,允许对RESTful API进行任意调用。该界面包括几个选项,可以组合使用以产生有趣的结果。
选择请求方法(获取,放置,发布,删除),json查询数据,节点和路径
JSON验证器
能够在计时器上重复请求
能够使用javascript表达式转换结果
能够随时间(使用计时器)收集结果或比较结果
能够以简单的条形图(包括时间序列)绘制转换结果的图表
5.3.2 Elasticsearch head安装方法
- 通过docker安装(推荐)
- 通过chrome插件安装(推荐)
- 通过ES的plugin方式安装(不推荐)
- 源码安装,通过npm run start (不推荐)
参考:https://github.com/mobz/elasticsearch-head
5.3.3 head安装方法 - docker(本次使用该方式)
#拉取镜像
docker pull mobz/elasticsearch-head:5
#创建容器
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
#启动容器
docker start elasticsearch-head
5.3.4 head安装方法 - chrome插件
下载地址:https://chrome.google.com/webstore/detail/elasticsearch-head/ffmkiejjmecolpfloofpjologoblkegm
5.3.5 head安装方法 - plugin
很少用,省略
5.3.6 head安装方法 - 源码
1) 安装npm和git
[root@xiyu-1 ~]# yum -y install npm git
2) 安装elasticsearch-head插件
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install #执行安装,时间会有点久,约20分钟时间
npm run start & #后台启动服务
ss -nlt |grep 9100 #端口是否正常
open http://localhost:9100/ :
5.3.7 elasticsearch-head测试
1)浏览器访问9100端口,将连接地址修改为elasticsearch地址。
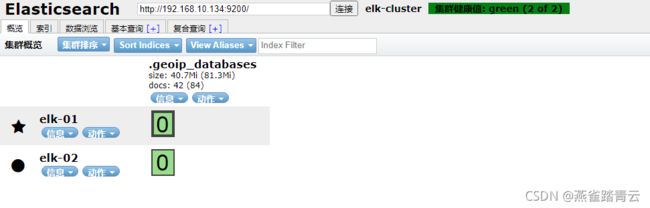
http.cors.enabled: true
http.cors.allow-origin: “*”
然后重启elasticsearch,再次elasticsearch-head测试
关于http.cors介绍说明:
| 功能 | 说明 |
|---|---|
| http.cors.enabled | 是否支持跨域,默认为false |
| http.cors.allow-origin | 当设置允许跨域,默认为*,表示支持所有域名,如果我们只是允许某些网站能访问,那么可以使用正则表达式。比如只允许本地地址。 /https?: //localhost(:[0-9]+)?/ |
| http.cors.max-age | 浏览器发送一个“预检”OPTIONS请求,以确定CORS设置。最大年龄定义多久的结果应该缓存。默认为1728000(20天) |
| http.cors.allow-methods | 允许跨域的请求方式,默认OPTIONS,HEAD,GET,POST,PUT,DELETE |
| http.cors.allow-headers | 跨域允许设置的头信息,默认为X-Requested-With,Content-Type,Content-Length |
| http.cors.allow-credentials | 是否返回设置的跨域Access-Control-Allow-Credentials头,如果设置为true,那么会返回给客户端。 |
2)测试提交数据

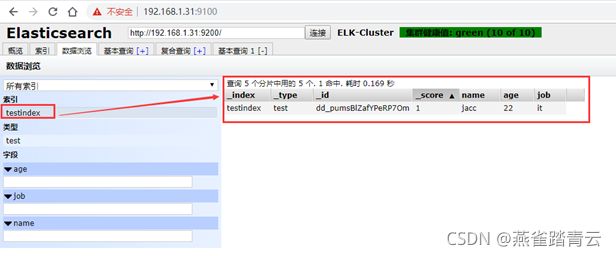
3)验证索引是否存在
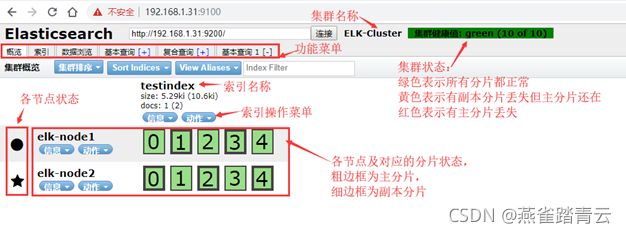
4)查看数据
5)Master和Slave的区别
Master的职责:统计各node节点状态信息、集群状态信息统计、索引的创建和删除、索引分配的管理、关闭node节点等
Savle的职责:同步数据、等待机会称为Master
[root@xiyu-1 elk]# #rpm -qa |grep jdk |xargs yum -y remove {};
[root@xiyu-1 elk]# #yum -y localinstall jdk-8u211-linux-x64.rpm
[root@xiyu-1 elk]# java -version
java version “1.8.0_211”
Java™ SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot™ 64-Bit Server VM (build 25.211-b12, mixed mode)
注意:如果elasticsearch-head中创建索引点击无反应
1、导出容器中文件docker cp elasticsearch-head:/usr/src/app/_site/vendor.js ./
2、将vendor.js中的contentType: "application/x-www-form-urlencoded改为contentType: "application/json;charset=UTF-8"
3、将vendor.js中的var inspectData = s.contentType === "application/x-www-form-urlencoded" &&改为var inspectData = s.contentType === "application/json;charset=UTF-8" &&
4、替换新文件docker cp vendor.js elasticsearch-head:/usr/src/app/_site
5、测试
5.4 ES基本概念
5.4.1 索引
- 索引是Elasticsearch对逻辑数据的逻辑存储,所以它可以分为更小的部分
- 可以把索引看作关系型数据库的表,索引的结构是为快速全文索引准备的,不存储原始值
- 可以把索引存放在一台或者多台机器上,每个索引有一个或多个分片(shard),每个分片可以有多个副本(replica)
5.4.2 文档类型
一个索引对象可以存储很多不同用途的对象。例如,一个博客可以保存文章和评语
每个文档可以由不同的结构
不同的文档类型不能为相同的属性设置不同的类型。例如,同一个索引中的所有文档类型,一个叫title的字段必须具有相同的类型
_type名字可以是大写和小写,不能含逗号或者下划线等特殊字符,每个类型都有自己的映射(mapping)或者结构定义,就像数据库的表中列一样
_id仅仅是一个字符串,它与_index和_tpye组合时,就像es中唯一标识一个文档,当创建一个文档时,你可以自定义id,也可以让es自动生成(长度为32位)
5.4.3 分片和副本
为了将数据添加到es中,通过索引(index)存储关联数据,实际上,索引只是用来指向一个或多个分片(shards)的逻辑命令空间
-
一个分片是一个最小级别的工作单位,保存了所有数据中一部分数据
-
分片就是一个Lucene实例,并且它本身就是一个完整的索引引擎,应用程序不会和它直接通信
-
分片可是是主分片(primary shard)也可是是复制分片(replica shard)
-
索引中的每个文档都属于一个单独的主分片,所以主分片的数量决定了索引最多能存多少数据量
-
复制分片只是主分片的一个副本,可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的shard取回文档
-
当索引创建完成后,主分片的数量就固定了,不可以更改,但是复制分片的数量可以随时调整
5.4.4 文档
存储在es中的主要实体是文档(document),相关与数据库表的一行记录
与MongoDB中文档类似,都可以有不同的结构,但是es文档中,相同字段必须类型相同
文档由多个字段组成,可以是文本、日期、数值等
5.4.5 映射
所有文档写入索引前都会进行分析,如何将输入的文本分割为词条、哪些词条会被过滤,这种行为叫做映射(mapping)。一般由用户自己自定义规则
5.5 RESTful API
5.5.1 RESTClient - 创建删除索引
1) 在火狐浏览器内添加restful 插件进行RESTful创建和删除索引的测试

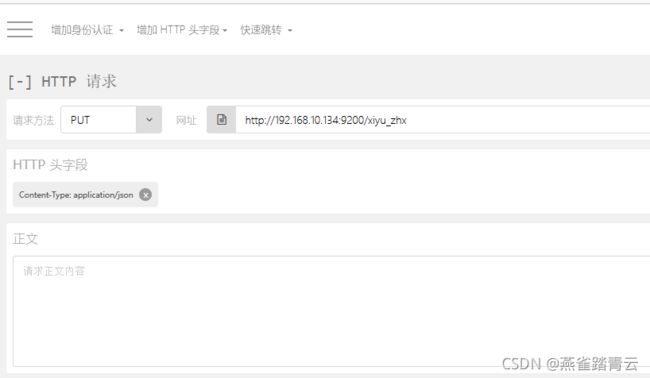
2) 添加自定义HTTP头字段


3)创建空索引
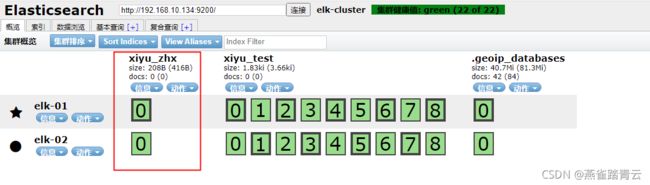
put http://192.168.10.134:9200/xiyu_zhx/ (默认1个副本一个分片)
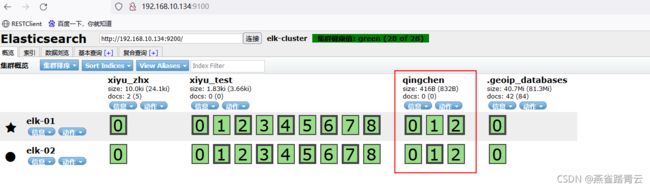
-
自定义分片和副本
PUT http://192.168.10.134:9200/qingchen/
{
“settings”: {
“index”: {
“number_of_shards”:3, #三分片,(操作时请将注释删除)
“number_of_replicas”:1 #一个副本
}
}
}

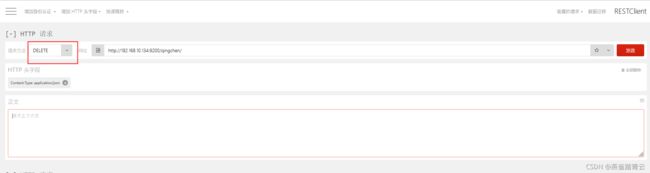
5)删除索引
DELETE http://192.168.10.134:9200/qingchen/
5.5.2 RESTful API - 插入、更新数据
-
插入数据
URL: POST /索引/类型/id
POST http://192.168.10.134:9200/xiyu_zhx/book/1
{
“name”: “Tom”,
“year”: “1990”
}
{
“name”: “Lily”,
“year”: “1995”
}

-
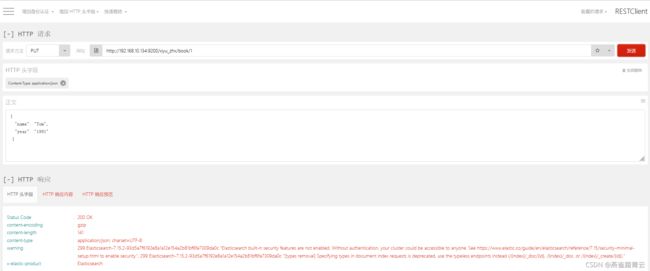
更新数据
put http://192.168.10.134:9200/xiyu_zhx/book/1
{
“name”: “Tom”,
“year”: “1991”
}

5.5.3 RESTful API - 删除和搜索数据
1)搜索全部数据
GET http://192.168.10.134:9200/xiyu_zhx/book/_search

2)根据id搜索
GET http://192.168.10.134:9200/xiyu_zhx/book/2
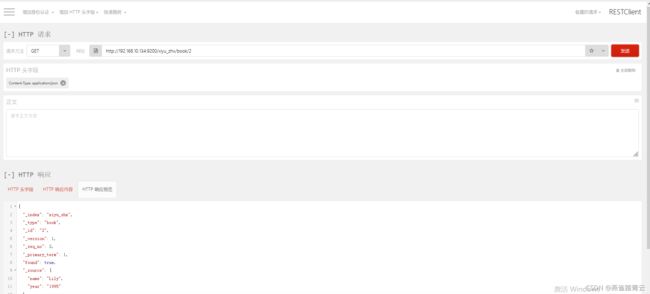
3)关键字搜索
GET http://192.168.10.134:9200/xiyu_zhx/book/_search?q=year:1995

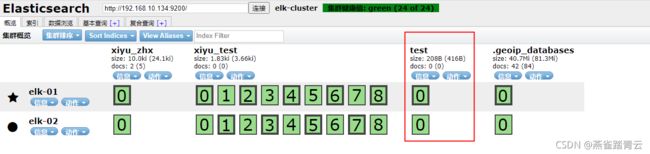
4)删除
DELETE http://192.168.10.134:9200/test


5.5.4 RESTful API - DSL搜索
Elasticsearch提供丰富而且灵活的查询语言叫DSL查询(Domain Specific Language特定领域语言),它允许构建更加复杂强大的查询,以JSON请求体的形式出现
1)创建一个索引
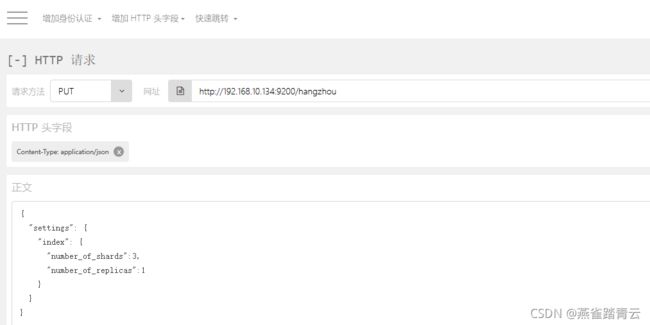
1)先插入数据
put http://192.168.10.134:9200/hangzhou/text/1001
{
“name”: “Tom”,
“year”: “1990”
“age”:"25
}
{
“name”: “Lily”,
“year”: “1995”
“age”:“22”
}
{
“name”: “Jack”,
“year”: “1998”
“age”:“19”
}
2)执行查询
POST http://192.168.10.134:9200/xiyu_zhx/book./_search
#请求体
{
“query”:{
“match”:{
“age”:22}
}
}
#请求体
{
“query”:{
“bool”:{
“filter”:{
“range”:{
“age”:{
“gt”:22
}
}
},
“must”:{
“match”:{
“sex”:“男”
}
}
}
}
}
5.2.7.6 RESTful API - 高亮显示和聚合
#请求体
{
“query”:{
“match”:{
“name”:“Tom Jack”
}
},
“higthlight”:{
“fields”:{
“name”:{}
}
}
}
5.5 日常操作
-
健康检查
http://192.168.10.135:9200/_cat/health?v
2) 批量查询
POST http://192.168.10.134:9200/qingchen/test/_mget
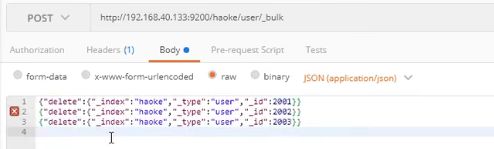
3) 借助_bulk批量删除
4) 分页
和sql的limit类似
GET http://192.168.10.134:9200/qingchen/test/_search?size=1&from=2
GET http://192.168.10.134:9200/qingchen/test/_search?size=1&from=10
-
查询响应pretty
在查询url后面添加pretty参数,让返回的json更容易看懂
GET http://192.168.10.134:9200/qingchen/test/1001?pretty
5.6 故障转移
5.6.1 将data节点停止
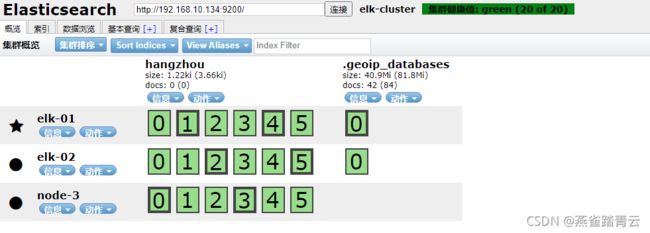
通过kill将data节点的elk-02的elasticsearch服务杀掉,过一段时间后重新拉起
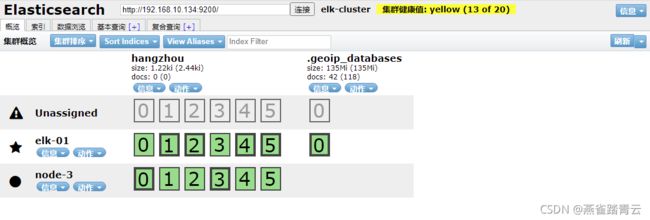
yellow:代表主节点可用,部分副本节点不可用
结论:data节点宕机对业务无影响,恢复后,重新加入集群
5.6.2 将master节点停止
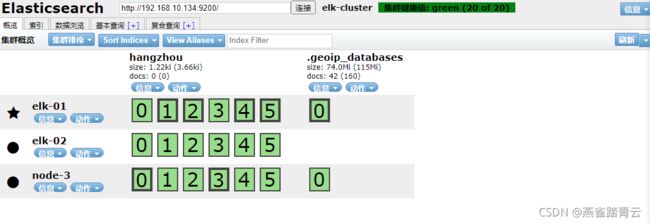
通过kill将master节点的elk-01的elasticsearch服务杀掉

将elk-01节点的elasticsearch服务重新拉起
结论:master节点宕机对业务无影响,集群对master节点进行了重新选举,切换为elk-03,恢复后,重新加入集群elk-01变为了data节点
5.7 Beats


5.7.1 Filebeat

轻量型日志采集器,无论您是从安全设备、云、容器、主机还是 OT 进行数据收集,Filebeat 都将为您提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁杂。



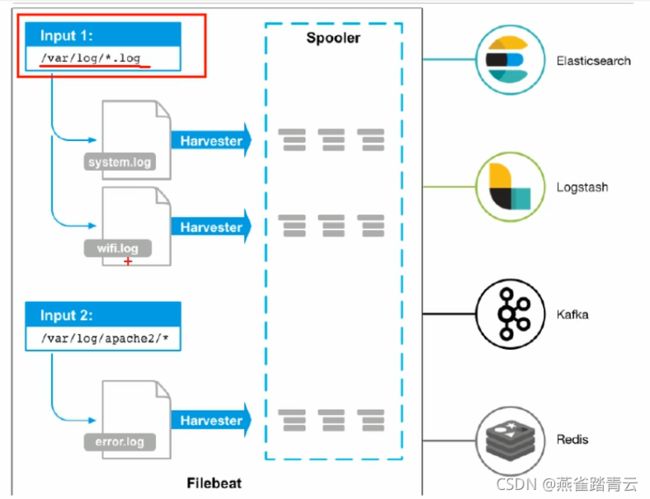
5.7.1.1 输出到console
1) 在filebeat-7.15.2-linux-x86_64目录内将filebeat.yml复制一份为xiyu.yml,测试通过console输出
filebeat.inputs:
- type: stdin
enabled: true
setup.template.settings:
index.number_of_shards: 3
output.console:
pretty: true
enable: true

2) 执行./filebeat -e -c xiyu.yml ,然后输入hello


5.7.1.2 读取日志文件输出到console
-
创建/home/elsearch/beat/filebeat/logs/路径,添加a.log文件 -
修改xiyu-log.yml 如下

3) 启动./filebeat -e -c xiyu-log.yml
4) 向a.log中echo数据 echo “hello world” >>a.log
5) 看到output有输出
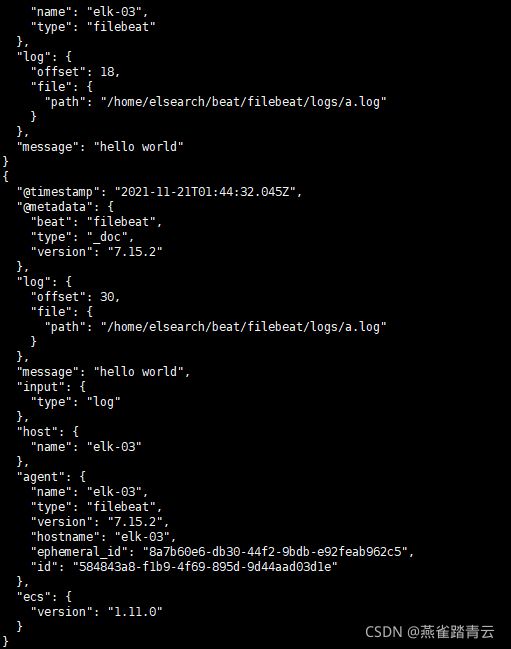
5.7.1.3 读取日志文件输出到elasticseach
-
修改xiyu-log.yml 如下

-
启动./filebeat -e -c xiyu-log.yml ,发现会生成一个新的索引
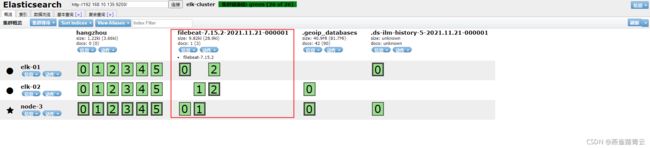
-
向a.log中echo数据
[root@elk-03 logs]# echo “this is test page” >>a.log
[root@elk-03 logs]# echo "xiyu test experiment " >>a.log

5.7.1.4 读取nginx文件输出到elasticseach
-
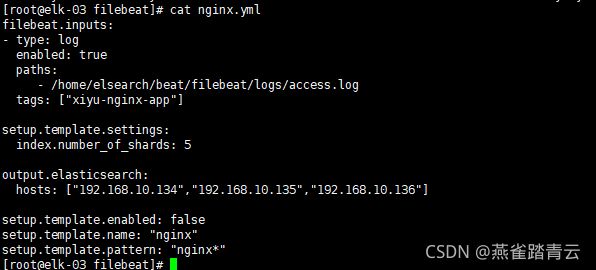
修改配置nginx.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/elsearch/beat/filebeat/logs/access.log
tags: ["xiyu-nginx-app"]
setup.template.settings:
index.number_of_shards: 5
output.elasticsearch:
hosts: ["192.168.10.134","192.168.10.135","192.168.10.136"]
setup.template.enabled: false
setup.template.name: "nginx"
setup.template.pattern: "nginx*"
-
启动./filebeat -e -c nginx.yml & ,发现会生成一个新的索引


-
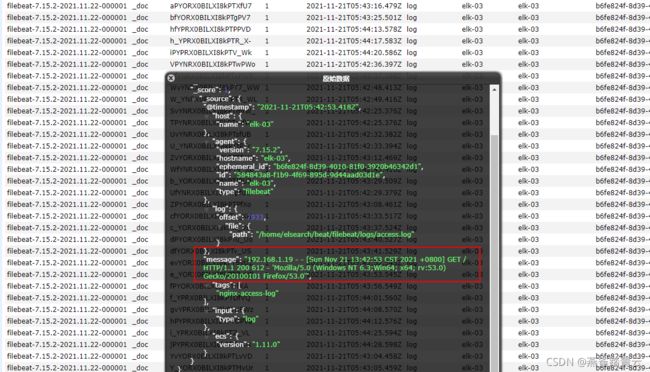
创建实时写入access.log日志
我们使用echo定时输入访问信息到/home/elsearch/beat/filebeat/logs/access.log 来模拟实时nginx访问日志
for i in `seq 1 100`;do sleep 2; echo "192.168.1.$i - - [`date` +0800] "GET / HTTP/1.1" 200 612 "-" 'Mozilla/5.0 (Windows NT 6.3;Win64; x64; rv:53.0) Gecko/20100101 Firefox/53.0'" >>/home/elsearch/beat/filebeat/logs/access.log;done

5.7.1.5 filebeat的module
-
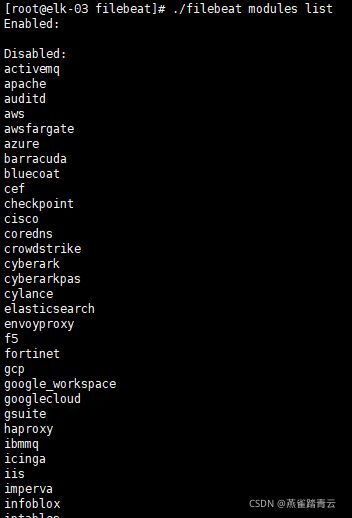
查看目前启用和未启用的module
./filebeat modules list
-
启用和禁用
./filebeat modules disable nginx
./filebeat modules enable nginx

3) 修改nginx的module
#cd modules.d/
#cat nginx.yml |grep -v ^$ |grep -v ‘#’
- module: nginx
access:
enabled: true
var.paths: ["/home/elsearch/beat/filebeat/logs/access.log*"]
error:
enabled: true
var.paths: ["/home/elsearch/beat/filebeat/logs/error.log*"]
-
修改filebeat
#vim /home/elsearch/beat/filebeat/nginx.yml
filebeat.inputs:
#- type: log
# enabled: true
# paths:
# - /home/elsearch/beat/filebeat/logs/access.log
# tags: ["nginx-access-log"]
setup.template.settings:
index.number_of_shards: 5
output.elasticsearch:
hosts: ["192.168.10.134","192.168.10.135","192.168.10.136"]
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
5) 启动filebeat服务

6) 测试
for i in `seq 1 100`;do sleep 2; echo "192.168.1.$i - - [`date` +0800] "GET / HTTP/1.1" 200 612 "-" 'Mozilla/5.0 (Windows NT 6.3;Win64; x64; rv:53.0) Gecko/20100101 Firefox/53.0'" >>/home/elsearch/beat/filebeat/logs/access.log;done
使用上面for循环写入数据进行测试,自动新出现一个索引(为了方便测试,之前小节使用的filebeat索引已删除)
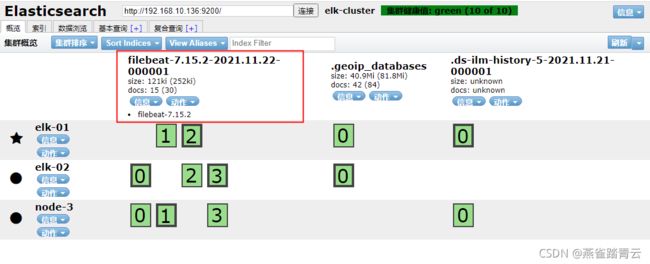
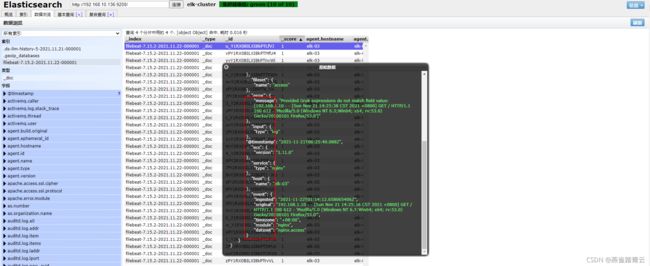

测试发现,已使用到module有格式化输出
5.7.2 Metricbeat
5.7.2.1 Metricbeat介绍

功能:
1)定期收集系统或者服务的性能指标数据
2)不断的存储到ES中,进行实时分析
组成:
1)Module(收集的对象,如redis、nginx、tomcat以及系统等)
2)Metricset(对象的指标,如cpu、内存、网络等)

- 通过info命令去收集redis的性能指标数据
#>info
5.7.2.2 Metircbeat部署
然后修改配置文件
vim metricbeat.yml
添加如下内容
metricbeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
index.codec: best_compression
setup.kibana:
output.elasticsearch:
hosts: [""127.0.0.1:9200"]
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
在配置完成后,我们通过如下命令启动即可
./metricbeat -e
在ELasticsearch中可以看到,系统的一些指标数据已经写入进去了:
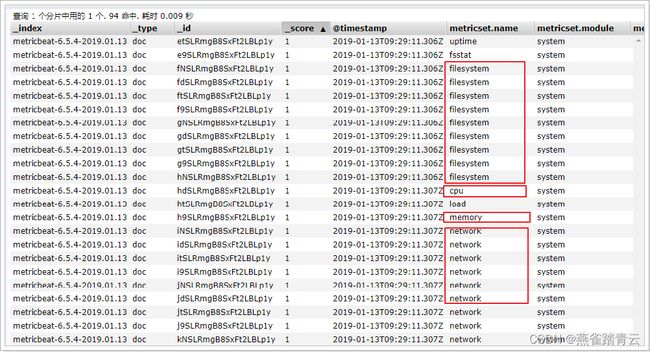
5.7.2.3 system module配置
- module: system
period: 10s # 采集的频率,每10秒采集一次
metricsets: # 采集的内容
- cpu
- load
- memory
- network
- process
- process_summary
Metricbeat Module的用法和我们之前学的filebeat的用法差不多
#查看列表
./metricbeat modules list
能够看到对应的列表
Enabled:
system #默认启用
Disabled:
aerospike
apache
ceph
couchbase
docker
5.7.2.4 Nginx Module
开启Nginx Module
在nginx中,需要开启状态查询,才能查询到指标数据。
#重新编译nginx
./configure --prefix=/usr/local/nginx --with-http_stub_status_module
make
make install
./nginx -V #查询版本信息
nginx version: nginx/1.11.6
built by gcc 4.4.7 20120313 (Red Hat 4.4.7-23) (GCC)
configure arguments: --prefix=/usr/local/nginx --with-http_stub_status_module
#配置nginx
vim nginx.conf
location /nginx-status {
stub_status on;
access_log off;
}
#重启nginx
./nginx -s reload
测试
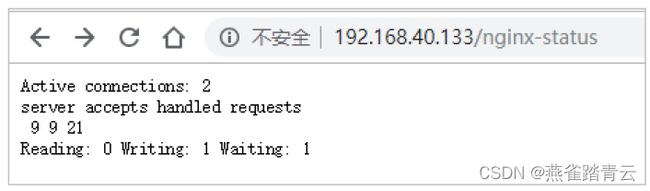
结果说明:
Active connections:正在处理的活动连接数
server accepts handled requests
第一个 server 表示Nginx启动到现在共处理了9个连接
第二个 accepts 表示Nginx启动到现在共成功创建 9 次握手
第三个 handled requests 表示总共处理了 21 次请求
请求丢失数 = 握手数 - 连接数 ,可以看出目前为止没有丢失请求
Reading: 0 Writing: 1 Waiting: 1
Reading:Nginx 读取到客户端的 Header 信息数
Writing:Nginx 返回给客户端 Header 信息数
Waiting:Nginx 已经处理完正在等候下一次请求指令的驻留链接(开启keep-alive的情况下,这个值等于 Active - (Reading+Writing))
配置nginx module
#启用redis module ./metricbeat modules enable nginx
#修改redis module配置 vim modules.d/nginx.yml
然后修改下面的信息
#Module: nginx
#Docs: https://www.elastic.co/guide/en/beats/metricbeat/6.5/metricbeat-modulenginx.
html
- module: nginx
#metricsets:
#- stubstatus
period: 10s
#Nginx hosts
hosts: ["http://127.0.0.1"]
#Path to server status. Default server-status
server_status_path: "nginx-status"
#username: "user"
#password: "secret"
修改完成后,启动nginx
#启动
./metricbeat -e
测试
我们能看到,我们的nginx数据已经成功的采集到我们的系统中了

可以看到,nginx的指标数据已经写入到了Elasticsearch。